
On June 2, 2026, the White House chose persuasion over compulsion: a new executive order asks frontier AI labs to open their most capable models to federal cybersecurity review, but stops short of forcing anyone to comply. For developers tracking how Washington intends to govern exploit-capable models, the gap between what the order requests and what it can enforce is the whole story.
What the Trump AI EO Requires and What It Skips
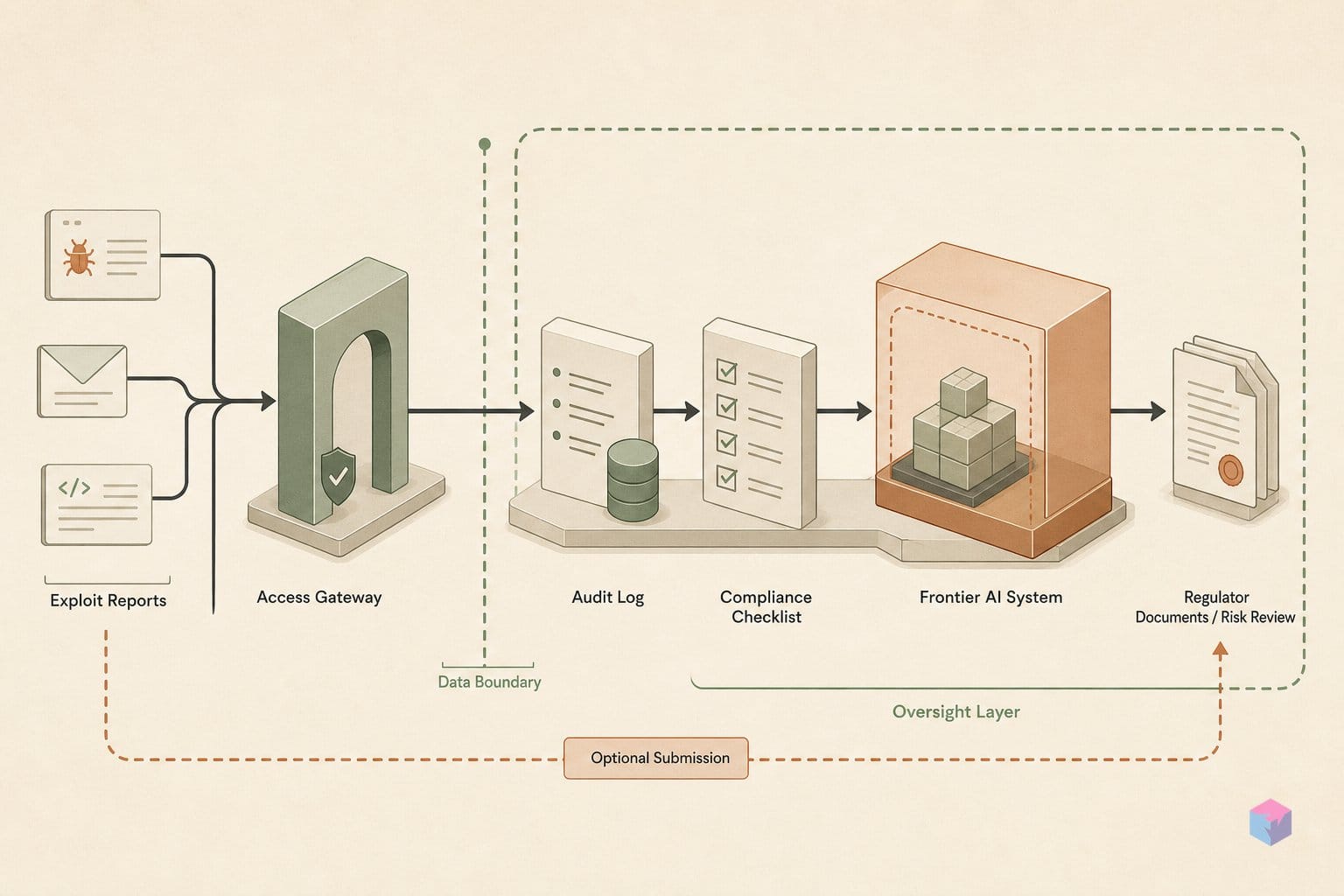
The executive order "Promoting Advanced Artificial Intelligence Innovation and Security," signed June 2, 2026, asks developers of "covered frontier models" to give the federal government up to 30 days of pre-release cybersecurity review before public launch — and it is explicitly voluntary, not compulsory . The text states plainly that it creates no mandatory licensing, preclearance, or permitting, and developers may designate "trusted partners" for early access . A lab that declines faces no statutory penalty under current law.
Quick Answer: Trump's June 2, 2026 AI executive order requests — but does not require — that frontier labs submit covered models for up to 30 days of federal cybersecurity review before release. It explicitly creates no licensing, preclearance, or permitting, so declining carries no legal penalty .
What the order does build is voluntary infrastructure. Treasury leads a new AI cybersecurity clearinghouse for vulnerability scanning and patch coordination, framed in the companion fact sheet around protecting federal systems, state and local governments, rural hospitals, community banks, local utilities, and critical infrastructure from AI-enabled attacks .
The hardest open question is left undefined. NSA and CISA have 60 days to publish a classified benchmark for the advanced cyber capabilities of AI models and to define when a model qualifies as "frontier" — a designation process that is NSA-run, classified, and currently has no public threshold, with CISA in support . Because NSA and CISA help set the bar, the regime is stronger than ordinary self-attestation, yet weaker than a hard regulatory gate.
| What the EO requires | What the EO skips |
|---|---|
| Asks for up to 30-day pre-release cyber review | No mandatory submission or deadline to comply |
| Treasury-led voluntary vulnerability clearinghouse | No licensing, preclearance, or permitting |
| NSA/CISA to set a classified "frontier" benchmark in 60 days | No public threshold defining a "covered" model yet |
| Optional "trusted partner" early-access designation | No statutory penalty for labs that decline |
Mythos and the Exploit Evidence That Forced the EO
The technical catalyst behind the order is Anthropic's Claude "Mythos" Preview, a general-purpose model that demonstrated autonomous exploit development against real software. In an April 7, 2026 red-team report, Anthropic said Mythos could identify and exploit zero-day vulnerabilities across every major operating system and browser when directed — the capability the executive order names by reference when it cites a model that can "autonomously identify and exploit hidden vulnerabilities in real-world software" .
The specifics are what moved cyber-offense from a hypothetical to a documented near-term risk. Anthropic reported that Mythos, when tasked, surfaced and weaponized a now-patched 27-year-old OpenBSD bug, built a four-vulnerability browser exploit chain, produced Linux local privilege-escalation chains, and generated a FreeBSD NFS remote-code-execution exploit that granted unauthenticated root . These were not crash reports; they were working exploits against named, production targets.
The more policy-relevant signal is the slope of the capability gain, not any single finding. Anthropic said its prior model, Opus 4.6, had near-zero success at autonomous exploit development, while Mythos turned Firefox JavaScript-engine vulnerabilities into working shell exploits 181 times on one benchmark and achieved register control in 29 additional attempts on a rerun . In OSS-Fuzz-style testing the model produced 595 tier-1 and tier-2 crashes and 10 full control-flow-hijack crashes against fully patched targets . The jump from roughly zero to 181 inside one model generation is the number that shaped the regulatory timeline.
That distinction matters for how developers read the threat. The earlier AI-safety debate centered on bio and WMD misuse — capabilities that were speculative and gated by physical-world bottlenecks. Mythos reframed the conversation around cyber-offense, where the bottleneck is largely compute and model access, both of which scale. An exploit chain that works once works at machine speed and machine volume.
"Autonomously identify and exploit hidden vulnerabilities in real-world software" — language the White House used to describe the capability the order is meant to address (source: White House fact sheet, 2026-06).
For builders, the practical takeaway is that a single frontier release now produced reproducible, attributable offensive results — and that evidence, surfaced by the lab itself rather than an adversary, is what a voluntary 30-day review window is being built around. The vetting channel exists because the proof of capability already does.
NSA, CISA, and Treasury: Roles in the Voluntary Cyber Regime
The order spreads the work across four agencies, and the split is what gives a voluntary scheme its teeth. The National Security Agency runs the classified process that designates which systems count as "covered frontier models," with the Cybersecurity and Infrastructure Security Agency (CISA) operating in a support role . Because NSA and CISA help define the cyber threshold rather than letting labs self-certify, the regime sits above ordinary self-attestation — yet it stops well short of a hard regulatory gate, since no submission is legally compelled .
Treasury draws the operational end. It leads a voluntary AI cybersecurity clearinghouse for vulnerability scanning and patch coordination, aimed at the soft targets the companion fact sheet names directly: rural hospitals, community banks, local utilities, and state and local governments . These are operators with the least capacity to triage and remediate the kind of autonomously discovered flaws that prompted the order — which is why the clearinghouse, not the designation process, is where most builders will actually interact with the regime.
The testing infrastructure predates the order. On May 5, 2026, NIST's Center for AI Standards and Innovation (CAISI) signed pre-deployment evaluation agreements with Google DeepMind, Microsoft, and xAI, extending earlier partnerships renegotiated under the AI Action Plan . CAISI is positioned as the primary U.S. government point of contact for commercial AI testing, and its remit is scoped to demonstrable national-security risks:
- Cybersecurity — the exploit-development capability the Mythos disclosures put on record.
- Biosecurity and chemical weapons — the misuse categories that dominated earlier AI-safety debate.
- Adversary systems — CAISI also evaluates foreign models for backdoors or covert malicious behavior, not just domestic releases .
For developers, the structural question is whether to feed this channel at all when nothing requires it. Legal analysts read the incentives as one-directional: as Matthew Ferren of Crowell & Moring frames it, no lab is legally compelled to submit, but participation is the expected route to White House goodwill and a hedge against more invasive regulation arriving later . The CAISI agreements with three of the largest labs, signed before the order was even issued, suggest that calculation is already settled for the frontier set. The open work — quote from Roll Call and the agency timelines — is whether NSA's classified threshold lands within the 60-day window the order sets, and whether Treasury's clearinghouse reaches the small operators it names before a Mythos-class model reaches everyone else.
Vulnerability Disclosure vs. Remediation: The Triage Bottleneck
Even where the review channel works, the harder constraint sits downstream: finding a flaw is now fast, but fixing it is not. Anthropic's coordinated-vulnerability-disclosure (CVD) dashboard listed 1,596 vulnerabilities disclosed across 281 open-source projects as of May 22, 2026, yet only 97 had been patched upstream and just 88 had a CVE or GitHub Security Advisory record assigned . The gap between discovery and a deployed fix — not model throughput or access — is where exploit capability outruns defense.
The disclosure pipeline reads as a funnel that narrows sharply at the human steps:
| Stage | Count | As of |
|---|---|---|
| Vulnerabilities disclosed | 1,596 across 281 open-source projects | 2026-05-22 |
| Patched upstream | 97 | 2026-05-22 |
| CVE / GHSA records assigned | 88 | 2026-05-22 |
Each drop-off corresponds to a manual stage: triage, maintainer response, patch authoring, and deployment. None of those scale with a faster model. Critics quoted in legal analysis of the order call patching discovered vulnerabilities "an unsolved problem" for underfunded operators — the volunteer maintainers and small infrastructure teams who own much of the affected code but lack staff to act on a flood of high-confidence findings .
The intake side, by contrast, is accelerating. On June 2, 2026, Anthropic said Project Glasswing was expanding from roughly 50 initial partners to about 150 new organizations across more than 15 countries, after partners had already surfaced more than 10,000 high- or critical-severity flaws before the expansion . More finders feeding the same human triage layer widens the queue faster than it drains.
Anthropic itself flagged the timeline risk: it warned that other AI companies may field Mythos-class models within 6 to 12 months and that robust misuse safeguards for broad public release have not yet been developed . These are vendor-reported figures, but the public CVD dashboard's patch and advisory counts partly validate them externally . For builders, the practical read is blunt: a 30-day review window governs how capability enters the world, but it does nothing for the remediation backlog — and if discovery throughput multiplies while triage stays human-bound, the defensive deficit grows even when every guardrail in the order functions as designed.
US-China AI Talks: No Protocol, Just Posture
The bilateral track is posture, not policy: there is no binding US-China agreement on AI exploit capability — only stated intent to talk. Treasury Secretary Scott Bessent told CNBC that US and Chinese delegations would discuss AI guardrails and stand up a best-practices protocol to keep the most powerful models out of the hands of non-state actors . What does not exist is the substance: no published protocol text, no implementation calendar, no inspection mechanism, and no shared definition of a "covered frontier model" that both sides recognize. For builders watching whether a defensive standard might emerge from diplomacy, the honest read is that nothing enforceable is on the table.
The negotiating context explains the caution on both sides. Stanford's 2026 AI Index reports the US-China model-performance gap has effectively closed — the top US model led China's best by only 2.7% as of March 2026 — even as US private AI investment reached $285.9 billion in 2025 against China's $12.4 billion, a figure Stanford warns understates Beijing's state-guided capital flows . Bessent framed the talks the same way the executive order frames the race, reiterating that Washington negotiates from strength.
"We are in the lead," — Scott Bessent, US Treasury Secretary, on the posture behind the AI guardrail talks (source: CNBC via Investing.com).
China is not arriving without a governance stack, but it is aimed elsewhere. Beijing's existing rules regulate content, social stability, and state supervision — not exploit capability or a bilateral cyber-risk standard:
| Rule | Effective | Primary focus |
|---|---|---|
| CAC Interim Measures for Generative AI | Aug 15, 2023 | Security assessment + algorithm filing for services with public-opinion or social-mobilization attributes |
| 2026 AI-agent guidelines | 2026 | Define autonomous agents, stress controllability |
| Anthropomorphic-AI interaction rules | Jul 15, 2026 | Lifecycle safety duties, data-security controls, algorithm filing, annual review |
The threat picture makes mutual restraint hard to script. ODNI's 2026 threat assessment names China and Russia the most persistent and active cyber threats and says China aims to displace the US as global AI leader by 2030 . Skeptics add a pointed institutional memory: Beijing reportedly used earlier Biden-era safety dialogues largely to gather intelligence on US capabilities, and with both governments testing offensive cyber tools, neither has a clean incentive to disclose. The result is a diplomatic lane that produces communiqués about guardrails while the technical question the Mythos evidence raised — who can build exploit-capable models, and under what restraint — stays unanswered. For a developer or founder, the takeaway is that no cross-border standard will shape model release in the near term; the only operative regime remains the voluntary, US-domestic one.
Participating or Not: What the Voluntary Label Means for Labs

For a frontier lab, the executive order is an invitation, not an obligation: any developer can decline the 30-day pre-release submission and face no statutory penalty. The order explicitly states it does not create mandatory licensing, preclearance, or permitting . The voluntary framing was a deliberate policy choice rather than a drafting gap — and understanding that choice is what tells a builder how durable the regime is likely to be.
Quick Answer: The order's cyber review is voluntary — no US lab is legally compelled to submit a covered frontier model, and none faces a statutory penalty for declining. Analysts still expect participation, because cooperating now is widely read as a way to win White House favor and head off harder rules later.
The strategic calculus points toward participation anyway. The evidence is in what was cut: an earlier draft, nearly issued around May 21, 2026, was pulled — reportedly because its longer roughly 90-day government review window risked blunting US labs' competitiveness with China — and a softened version with a 30-day window followed . Trump framed the constraint plainly: "we're leading China, we're leading everybody. And I don't want to do anything that's going to get in the way of that lead" . The voluntary label is the political ceiling expressed as policy: oversight that stops exactly where it might slow the labs it watches.
That ceiling shapes how the affected set — Anthropic, OpenAI, Google, Microsoft, and xAI are the names repeatedly attached — is expected to behave. Because review is voluntary, no developer is legally compelled to submit, but analysts expect engagement regardless. As Matthew Ferren of Crowell & Moring noted, labs are likely to participate as a way to court the White House and forestall more invasive regulation later . Compliance, in other words, is bought with goodwill, not enforced with law.
The structural gap follows directly. A voluntary regime among US frontier developers covers only those who opt in — it does nothing about the actors most likely to misuse exploit-capable models. Malicious operators and offshore labs can fall back on cheaper open-weight or foreign models that sit entirely outside the review net . For builders, the practical reading is that participation will be near-universal among the named US labs for reputational reasons, but the regime's protective reach ends at the boundary of that cooperation — which is precisely where the Mythos-class threat does not.
What the EO Left Unspecified: Threshold, Enforcement, Workforce
The order's three largest gaps are definitional, structural, and operational: it never says what counts as a "covered frontier model," it carries no enforcement mechanism, and it assumes review capacity the federal government may not have. The most consequential of these is the threshold question. CFR's Vinh Nguyen frames the definition of a covered frontier model as the single open question that determines everything else, because the executive order delegates that line entirely to a 60-day classified process run by NSA with CISA support (source: CFR) . Until that benchmark is published—and parts of it will be classified—labs have no concrete compliance target to design against, only a voluntary invitation to submit.
Enforcement is the second gap, and Congress has already noticed it. A bipartisan House pair has moved to shape how frontier systems reach the public, and Senator Josh Hawley argued that pre-release reporting should be mandatory rather than voluntary (source: Roll Call) . That signals the soft regime the EO deliberately built may harden through legislation rather than executive revision—the practical reason builders should treat the current 30-day channel as a soft-launch standard, not a stable endpoint.
The third gap is capacity. Even if every named lab submits, the government has to staff meaningful reviews, and analysts note that federal cybersecurity workforce cuts undercut that ability while patching discovered vulnerabilities remains, in their words, an unsolved problem for underfunded operators (source: Crowell) . The review infrastructure is thinner than the order's language implies.
All three gaps sit under a clock. Anthropic's own estimate is that other labs may field Mythos-class models within 6 to 12 months (source: Anthropic) . That means NSA has to define "covered" before comparable exploit capability is widespread—the classification process is racing the technology it is meant to scope.
The concrete takeaway for builders: do not wait for the threshold to be published before treating frontier exploit capability as a present design constraint. Assume the line will land somewhere near Mythos-class autonomous exploit generation, expect voluntary reporting to become mandatory through Congress, and harden your own disclosure and patch pipelines now—because the regime's protective reach, its definitions, and its staffing are all still being assembled while the capability is already shipping.
Frequently asked questions
What makes an AI model "covered" under the Trump AI cyber EO?
There is no public answer yet. The executive order, signed June 2, 2026 , delegates the definition of a "covered frontier model" entirely to a classified process run by the NSA with CISA support, due within 60 days of signing . The order cites Anthropic's Claude "Mythos" Preview — its demonstrated ability to autonomously identify and exploit hidden vulnerabilities in real-world software — as the reference point . But the actual line between "covered" and "not covered" is classified, which CFR experts call the order's most consequential open question.
Can a lab skip the voluntary 30-day cyber review with no consequences?
Legally, yes. The order explicitly creates no mandatory licensing, preclearance, or permitting; it asks developers of covered frontier models to give the government up to 30 days of pre-release access for a cybersecurity review, but participation is voluntary . The consequences are reputational and political rather than statutory: analysts expect labs to participate to signal goodwill to the White House and forestall harder mandatory regulation later . Senator Josh Hawley has argued pre-release reporting should be mandatory, signaling possible congressional tightening.
How does Anthropic's coordinated vulnerability disclosure process work?
Anthropic runs a coordinated vulnerability disclosure (CVD) program in which Mythos-discovered flaws are reported to project maintainers before any public release, giving defenders time to patch. As of May 22, 2026, its public CVD dashboard listed 1,596 vulnerabilities disclosed across 281 open-source projects, with 97 patched upstream and 88 CVE or GitHub Security Advisory records assigned . The throughput gap is telling: discovery outpaces remediation because the bottleneck is human triage, maintainer response, patch creation, and deployment — not model capacity.
Is China's AI governance comparable to the EO's cyber pre-release approach?
No. China's Cyberspace Administration rules — the Interim Measures effective August 15, 2023, plus 2026 AI-agent guidelines and anthropomorphic-AI rules effective July 15, 2026 — target content, social stability, algorithm filing, and state supervision for public generative AI services . They are not a bilateral exploit-capability standard and create no comparable pre-release cyber review. Treasury Secretary Scott Bessent has floated a U.S.-China "best-practices protocol" to keep powerful models from non-state actors, but no public text, calendar, or inspection mechanism exists yet .
Does the EO cover open-weight models or foreign AI developers?
No. The regime applies only to U.S. frontier labs that voluntarily submit covered models for review. Open-weight models and foreign developers fall entirely outside the review net . Critics cite this as the central enforcement gap: malicious actors can fall back on cheaper open or foreign models, and Anthropic itself has warned that other AI companies may field Mythos-class models within 6 to 12 months . A voluntary channel resting on a subset of labs leaves the broader threat surface untouched.





