
Google DeepMind's open-weight family grew a new middle child this month, and the interesting part isn't the parameter count — it's what's missing from the architecture.
Gemma 4 12B's Encoder-Free Unified Checkpoint, Explained
Gemma 4 12B is an encoder-free, unified multimodal model released by Google DeepMind on June 3, 2026 under the permissive Apache 2.0 license. It carries 11.95B parameters across 48 layers with a 256K-token context window, sitting between the 4B-class edge variants and the larger 26B A4B and 31B Mixture-of-Experts models that shipped first.
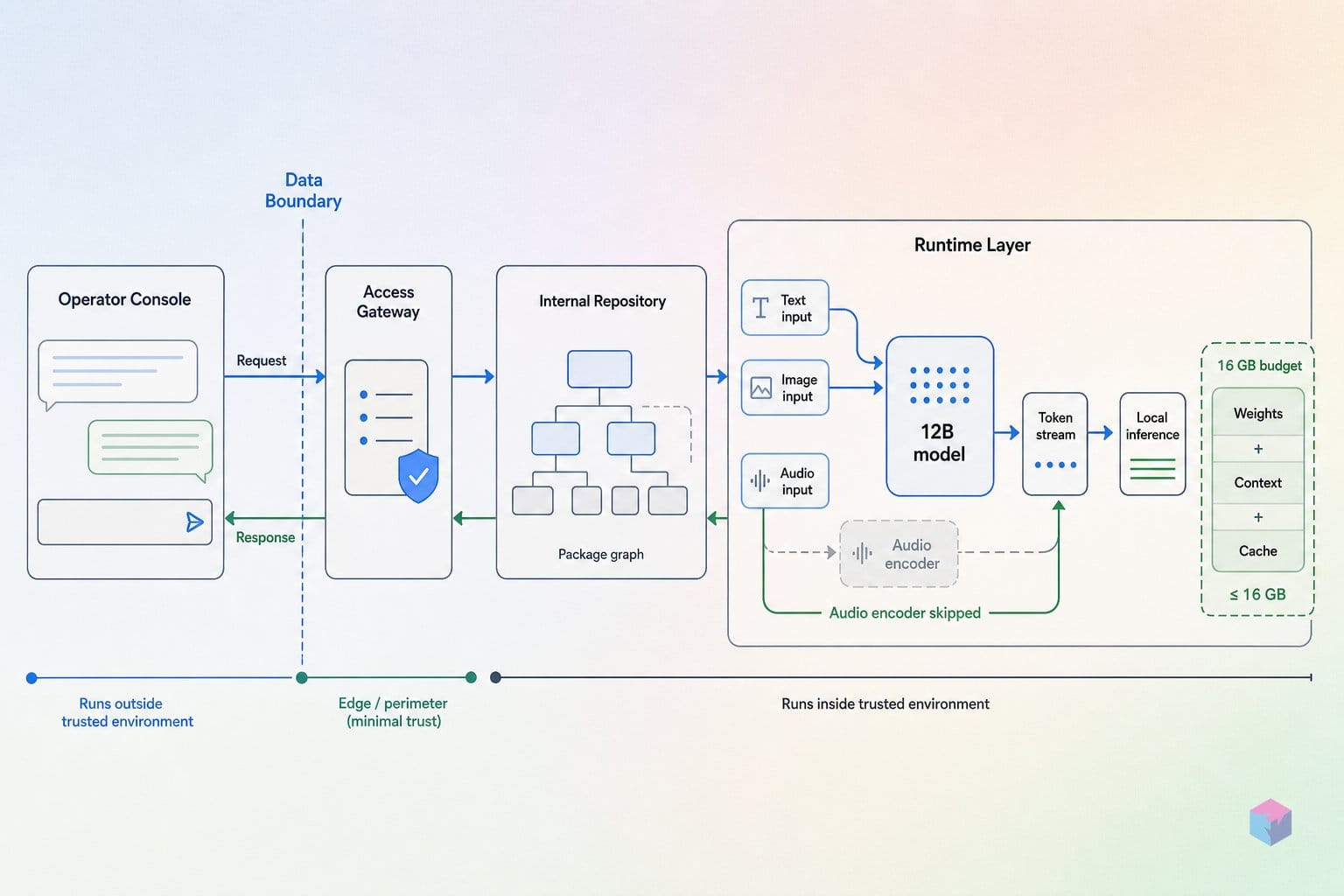
The defining change is that nothing is bolted on. Instead of dedicated vision and audio towers, raw inputs project straight into the LLM embedding space: vision runs through a ~35M-parameter embedding module operating on raw 48×48 patches, and 16 kHz audio is sliced into 40 ms frames of 640 floats — no separate conformer audio encoder. That makes it the first mid-sized Gemma with native audio input.
- Inputs: text, images (configurable token budgets of 70/140/280/560/1120), audio up to 30 s, and video up to 60 s at ~1 fps; output is text-only .
- Attention: hybrid layout interleaving local sliding-window (1024 tokens) with global attention, plus Proportional RoPE and Per-Layer Embeddings for on-device efficiency .
- Knowledge cutoff: pre-training data stops at January 2025, so factual answers can be stale and should be tool-augmented.
RAM, VRAM, and Dependency Requirements Before Downloading
Before pulling weights, size your hardware to the quantization you intend to run, because free memory must exceed the quantized file on disk or the process crashes on load. Per Unsloth, the 12B model needs roughly 7–8 GB at 4-bit and 13–14 GB at 8-bit, while the full FP16 instruction-tuned checkpoint lands near 24 GB . The widely quoted "runs on a 16 GB laptop" figure targets a quantized IT checkpoint at modest context lengths on Apple Silicon unified memory or a discrete GPU — 256K context at large batch sizes will push well past it .
| Quant | Approx. memory | Notes |
|---|---|---|
| UD-Q4_K_XL (dynamic 4-bit) | ~7–8 GB | Preferred; best fit for 16 GB |
| Q8_0 | ~13–14 GB | Higher precision, tighter headroom |
| FP16 IT checkpoint | ~24 GB | Needs a larger GPU or split |
For the Transformers path you need Python 3.9+ and pip install transformers torch accelerate, plus torchvision librosa if you want image, audio, or video input . One step blocks everyone first time: google/gemma-4-12B-it is a gated repo, so accept Google's usage license on Hugging Face or Kaggle while logged in — otherwise the download fails outright .
Pulling and Serving Gemma 4 12B: Ollama, Transformers, and llama.cpp
With the license accepted, four runners cover almost every local setup, and each starts a usable endpoint in one or two commands. Ollama is the fastest path to a chat server, Transformers gives you full multimodal control in Python, llama.cpp via Unsloth's GGUFs is the leanest on memory, and LiteRT-LM exposes an OpenAI-compatible API across Linux, macOS, Windows, and Raspberry Pi. Across all of them, use the instruction-tuned google/gemma-4-12B-it checkpoint — the base model is not chat- or multimodal-ready.
Ollama. ollama run gemma4:12b pulls the Q4 tag — listed at 7.6 GB with a 256K context window — and starts an OpenAI-compatible chat endpoint. The Ollama library lists text and image input for this tag . Audio input is official only for the Transformers/HF path, so verify it against your installed Ollama version before building on it .
HuggingFace Transformers. Load with AutoModelForMultimodalLM.from_pretrained('google/gemma-4-12B-it', dtype='auto', device_map='auto'). Build messages with standard system/user/assistant roles — Gemma 4 dropped the older Gemma turn format . Call processor.apply_chat_template(..., add_generation_prompt=True, enable_thinking=False), run model.generate, decode only the new tokens, and finish with processor.parse_response(...) .
llama.cpp (GGUF via Unsloth). The dynamic 4-bit quant is the recommended default:
export LLAMA_CACHE="unsloth/gemma-4-12B-it-GGUF"
./llama.cpp/llama-cli -hf unsloth/gemma-4-12b-it-GGUF:UD-Q4_K_XL \
--temp 1.0 --top-p 0.95 --top-k 64This pulls the IT GGUF and runs at the model card's recommended sampling .
LiteRT-LM is the cleanest route to a local OpenAI-compatible API, with chat, multimodal attachments, function calling, and stateless prefix caching:
litert-lm import --from-huggingface-repo=litert-community/gemma-4-12B-it-litert-lm \
gemma-4-12B-it.litertlm gemma4-12b
litert-lm serve"You can try Gemma 4 12B with a couple of clicks" across LM Studio, Ollama, AI Edge Gallery, and the LiteRT-LM CLI — Google DeepMind, Gemma 4 12B developer guide (source: developers.googleblog.com).
Recommended sampling is identical on every backend: temperature=1.0, top_p=0.95, top_k=64 . These are model-card values — don't tune them without a clear evaluation criterion, since drift here is a common source of "the model got worse after I changed settings."
16 GB Isn't a Guarantee, Audio Support Varies, Figures Are Self-Reported

The 16 GB target is a floor for the 4-bit instruction-tuned checkpoint at modest context lengths, not a ceiling for every workload. Unsloth puts the quantized weights at roughly 7–8 GB at 4-bit and 13–14 GB at 8-bit, and advises that free memory exceed the file size . Push toward the full 256K context, raise batch sizes, or load BF16 weights and you blow past 16 GB quickly. Treat Google's 1 GB mobile footprint as an E2B figure only — it does not extrapolate to the 12B model .
Audio input is spec'd for the Transformers/HF path, but it is not consistently surfaced in Ollama or llama.cpp GGUF runners at launch — image input historically failed through some GGUF paths, so verify multimodal support in your runtime . Run a short audio-input test against your chosen runner before building anything audio-dependent.
The headline numbers — AIME 2026 77.5%, LiveCodeBench v6 72.0%, GPQA Diamond 78.8% — are all Google model-card results as of June 2026, and third-party leaderboard entries are still thin . The card shows the 12B beating Gemma 3 27B (no-think) on AIME 2026 (77.5% vs 20.8%) and LiveCodeBench v6 (72.0% vs 29.1%) — a meaningful delta if it survives independent reproduction. InfoQ reports mixed community feedback: "strong on simple coding and bug fixes but questionable on ambiguous, complex-reasoning problems," and not positioned to replace specialized models like Qwen — InfoQ, June 2026 (source: InfoQ). Watch the Open LLM Leaderboard for entries as they appear.
LoRA Fine-Tuning and MTP Drafter Acceleration
The encoder-free design also simplifies fine-tuning: because one set of weights handles text, image, and audio, a single LoRA adapter can update the entire multimodal loop in one pass — there are no separate encoder weights to reconcile, so you manage one adapter instead of a stack of modality-coupled ones . Unsloth advertises roughly 2x faster fine-tuning with about 70% less VRAM versus full-parameter training ; a practical 16–24 GB target is realistic, but measure it against a vanilla HF Trainer run on your task before assuming the savings hold.
For inference throughput, the 12B ships Multi-Token Prediction (MTP) drafters and is listed as drafter-ready. Google reports up to 3x decode speedup without reasoning degradation — enable it in LiteRT-LM or vLLM when latency matters. The model is also compatible with MLX and SGLang, and Google lists Cloud Run and GKE for production-scale serving .
The takeaway: one checkpoint, one adapter, one OpenAI-compatible server. Start with a UD-Q4_K_XL quant on 16 GB, confirm your runtime actually surfaces audio, then layer in MTP and a single LoRA pass only after you have measured the baseline on your own workload.
Frequently asked questions
Does Gemma 4 12B support audio input through Ollama?
Not reliably at launch. Audio is part of Gemma 4 12B's official multimodal spec — text, images, audio up to 30 seconds, and video up to 60 seconds — but Ollama's gemma4:12b tag (7.6 GB, 256K context) lists only text and image input . Image input has historically not been surfaced through some Ollama and HF GGUF paths either . Run a short audio-input test against your installed Ollama version before building on it.
How much RAM do I actually need to run Gemma 4 12B?
Roughly 7–8 GB at 4-bit GGUF (UD-Q4_K_XL) and 13–14 GB at 8-bit, with free memory exceeding the quantized file size . The 16 GB headline figure covers the instruction-tuned checkpoint at modest context lengths on Apple Silicon unified memory or a discrete GPU . Longer contexts toward the 256K maximum or larger batch sizes will exceed 16 GB.
Can I fine-tune Gemma 4 12B on a single consumer GPU?
Yes, via Unsloth LoRA. Because one set of weights handles every modality, a single LoRA adapter updates the entire multimodal loop in one pass — there are no separate vision or audio encoders to train . Unsloth advertises fine-tuning around 2x faster with roughly 70% less VRAM than full-parameter training . A practical target is 16–24 GB of VRAM.
How do I enable thinking mode in Gemma 4 12B?
Pass enable_thinking=True to apply_chat_template, or prepend a <|think|> control to the start of the system prompt . Do not store prior hidden thinking blocks in multi-turn conversation history — the model card flags this as incorrect usage . Recommended sampling across backends is temperature 1.0, top_p 0.95, top_k 64.
Are Gemma 4 12B's benchmark numbers independently verified?
Not as of June 2026. Every headline figure — MMLU-Pro 77.2%, AIME 2026 77.5%, LiveCodeBench v6 72.0% — comes from Google's own model card, and third-party reproduction remains thin this early . Community feedback is positive for simple coding and bug fixes but mixed on ambiguous, complex-reasoning problems . Monitor independent leaderboards for third-party entries as they appear.