
When the CEO of Europe's flagship AI lab puts custom silicon "on the table," the verb tense matters more than the headline. At Mistral AI's first AI Now Summit on May 28, 2026, Arthur Mensch did exactly that — and every word he chose was conditional.
What Mensch Said at AI Now Summit
Mistral has not announced a chip. What changed on May 28, 2026 is that co-founder and CEO Arthur Mensch, speaking at the company's first AI Now Summit and in a CNBC interview, publicly raised custom chip design for the first time — in explicitly conditional language . The framing is the story: this was one exchange in an interview, not a product reveal, a roadmap, or a press release.
His exact words leave little room for over-reading:
"Owning the chips may come, I think it should come at some point, but for now we are relying on Nvidia, which is a great partner to us, and we're testing a few things here and there," — Arthur Mensch, co-founder and CEO of Mistral AI (source: CNBC, 2026-05).
Pushed directly on whether Mistral might build proprietary silicon, Mensch said only "Of course, it is interesting," declining to rule it out . That is a signal of intent, not a committed program — there is no announced architecture, tape-out, foundry partner, or silicon team behind it. The AI Now Summit itself was Mistral's first such event , and the chip remarks landed alongside infrastructure announcements rather than as a standalone reveal.
Le Monde's May 29, 2026 report places the comment in its real context: Mensch's stated goal is for Mistral to become an independent, full-stack player "from chips in data centers to enterprise software" . That is a multi-year vision, not a funded initiative. For now, Mistral procures its compute through Nvidia — the dependency it would, eventually, like to reduce.
The Confirmed Buildout: 44 MW, GB300s, Q3 2026
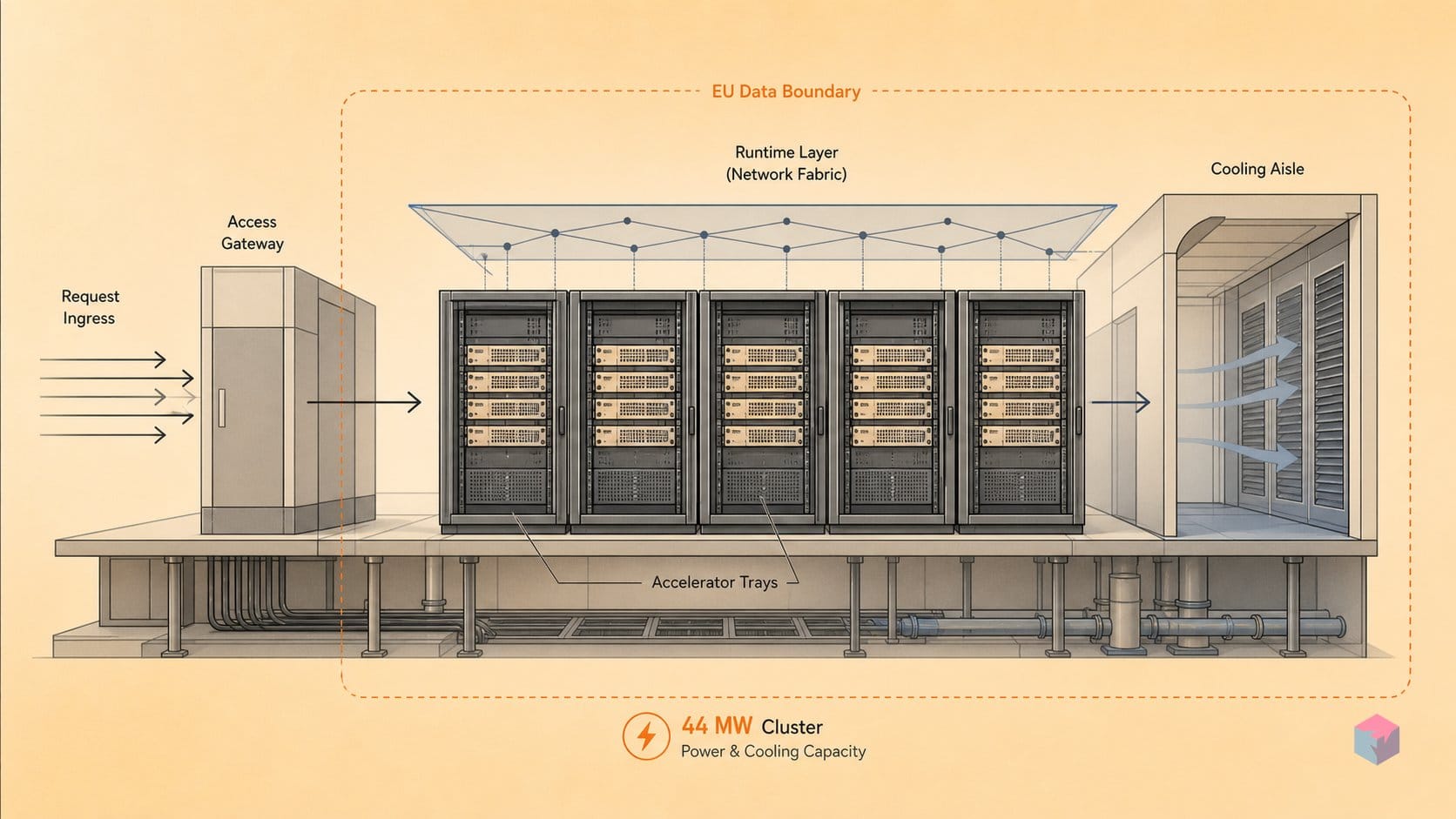
Behind the conditional chip language sits a concrete, funded program: physical inference capacity, all of it running on Nvidia hardware. CNBC-sourced reporting describes a French inference facility near Bruyères-le-Châtel equipped with 13,800 Nvidia GB300 accelerators and drawing roughly 44 MW, expected to come online around mid-2026 . Separately, Mistral's official AI Now Summit material cites a 10 MW inference facility at Les Ulis (Essonne) scheduled to open in Q3 2026, framed as a way to reduce compute supply-chain risk and increase capacity control . Whether Les Ulis is the same project as the 44 MW Bruyères-le-Châtel cluster or a distinct, smaller site is not resolvable from the available sources — the two figures do not reconcile, and neither source cross-references the other.
Both sites sit under Mistral Compute, the integrated infrastructure stack announced on June 11, 2025 . Its product page documents a steady hardware cadence and a stated 2027 capacity target:
| Milestone | Date |
|---|---|
| GB200 racks installed | July 2025 |
| GB300 added | December 2025 |
| GB200 serving in production | February 2026 |
| First external customers | March 2026 |
| Target: 200 MW sovereign EU capacity | 2027 |
The roadmap above is drawn from Mistral's Compute product page, which lists the timeline and the 200 MW EU sovereign-capacity goal for 2027 . The detail that matters for this story is what the page does not contain: every component named is Nvidia-based — GB200, GB300, and B300 GPUs, plus Grace and x86 CPU nodes — with no proprietary silicon anywhere in the stack . The confirmed buildout is therefore a near-term scaling of Nvidia inference, not a step toward custom chips. The 44 MW figure in the headline is real and Nvidia-powered; the silicon ambition discussed elsewhere remains separate from it.
Mistral's Integrated Stack and the Partners Behind It
The buildout slots into Mistral Compute, the integrated infrastructure stack Mistral announced on June 11, 2025 . It bundles GPU capacity, orchestration, APIs, and products into a single offering aimed at three buyer tiers: nation states, enterprises, and research labs. The pitch is sovereign full-stack compute — EU-hosted hardware, data residency, and capacity control — rather than a single model endpoint. The published roadmap targets 200 MW of sovereign EU capacity by 2027 .
What gives that pitch commercial grounding is the launch-partner roster, which is predominantly regulated French enterprise: BNP Paribas, Orange, Thales, SNCF, Schneider Electric, and Veolia, among others . These are exactly the data-residency-sensitive customers a European sovereign-cloud story needs — banks, telcos, defense, and infrastructure operators that cannot freely route workloads through U.S. hyperscalers. Their presence signals demand, not just ambition.
The hardware behind it stays Nvidia. The June 2025 partnership put a European platform powered by 18,000 advanced Nvidia chips near Saclay, built with Eclairion and starting in 2026, with Le Monde estimating the move at €500 million to €1 billion .
The closest thing to an engineering signal is the Emmi AI acquisition on May 23, 2026, which added 30-plus researchers working on Physics AI, simulation, and digital twins . That talent is adjacent to semiconductor and industrial workflows, but it is a simulation team, not a silicon team — no chip designers, no tape-out capability.
In-House Silicon: The Economics Hyperscalers Already Proved
The economic case Mensch made for custom chips is the same one Amazon and Google used to justify their own accelerators: tighter hardware-software co-design lowers per-token inference cost. Mensch told CNBC that owning silicon could "lower the cost of deploying tokens to meaningful extents" . That is an inference-economics argument, not a capability claim — the gain comes from co-tuning the chip to the model serving stack, not from beating Nvidia on raw FLOPS.
This is the dual-track model Mistral is watching rather than inventing. Amazon (Trainium/Inferentia) and Google (TPU) both run large in-house accelerator programs while continuing to buy significant Nvidia volume . Owning silicon for cost-sensitive inference and renting Nvidia for everything else is now a settled hyperscaler playbook — and it explains why Mistral has deepened, not reduced, its Nvidia dependence even while putting chips on the table.
| Operator | In-house silicon | Still buys Nvidia? | Stage |
|---|---|---|---|
| Amazon | Trainium / Inferentia | Yes, at scale | In production |
| TPU | Yes, at scale | In production | |
| Mistral | None disclosed | Yes — GB300-based | Conditional / exploratory |
The structural gap matters. AWS and Google assembled dedicated silicon teams at hyperscaler scale, spending years and billions before their first tape-out. Mistral has disclosed neither equivalent headcount nor capital earmarked for chip design — its closest engineering hire, the Emmi AI simulation team, does not change that. On current evidence the dual-track model is an aspiration Mistral is studying, not a program it has staffed.
There is also a non-economic layer. Mensch's framing is that AI infrastructure ownership should not be limited to a handful of cloud providers . That scarcity argument maps directly onto European industrial-policy goals, where the motivation for sovereign silicon is strategic independence as much as cheaper tokens — a rationale the U.S. hyperscalers never needed to invoke.
The €1.7B Series C: ASML and the Semiconductor Angle
The strongest financial signal of that value-chain ambition is the lead investor on Mistral's latest round. On September 9, 2025, Mistral closed a €1.7 billion Series C at an €11.7 billion post-money valuation, led by ASML . The participant list mixes deep-tech and growth capital: Nvidia, Andreessen Horowitz, Bpifrance, DST Global, General Catalyst, Index Ventures, and Lightspeed all joined .
What makes ASML's lead position notable is what ASML actually builds. ASML is the sole supplier of extreme ultraviolet (EUV) lithography machines — the tooling layer without which advanced sub-7nm chip fabrication does not happen. A hardware-tooling monopoly taking the lead investor slot in a model lab is a value-chain alignment, not a passive financial bet. Mistral and ASML framed it that way publicly, describing two firms in the same value chain working jointly on "semiconductor and AI problems" .
Read carefully, though, that framing is consistent with long-term chip intent without being a chip contract. There is no disclosed accelerator program, design partnership, or fabrication agreement attached to the round — only a stated willingness to work on shared problems. The capital is going to compute first. Mistral has committed roughly €4 billion to data-center buildout across France and Sweden, of which about €725 million was already borrowed per Le Monde, while targeting €1 billion in revenue by end-2026 .
The arithmetic matters: a company already borrowing to fund GPU clusters and chasing its first €1 billion revenue year is not obviously positioned to also self-finance a multi-billion-dollar silicon design effort. ASML's involvement signals where Mistral wants to sit in the stack — it does not yet fund a move there.
Mensch's Sovereignty Warning: Europe's Closing Window on AI
The chip question is downstream of a political argument Mensch has been making to French lawmakers. On May 12, 2026, addressing France's National Assembly, he warned that Europe has roughly two years to avoid structural dependency on U.S. AI infrastructure — a race he framed as decided by three inputs: energy, chips, and data-center capacity. Custom silicon sits at the logical endpoint of that framing. If the goal is European AI that does not run indefinitely on U.S.-controlled hardware, the chip layer is the last piece still outside Mistral's reach.
That is why the conditional chip language reads as strategy rather than improvisation. Mensch is not separating "own the chips" from "own the stack" — he is treating them as the same project, with silicon as the final step.
"Owning the chips may come, I think it should come at some point, but for now we are relying on Nvidia, which is a great partner to us, and we're testing a few things here and there," — Arthur Mensch, CEO of Mistral AI (source: CNBC).
The European supply side is being watched, not yet committed to. Le Monde reported on May 29, 2026 that Mistral is monitoring European processor-design efforts — but no named European chipmaker partnership has been confirmed. Politically, the direction has cover: when the Nvidia partnership landed in June 2025, President Macron publicly urged Europe to eventually master chip manufacturing, aligning with Mistral's stated trajectory.
Alignment is not funding. No government-backed chip program earmarked for Mistral has been disclosed, and warning that the window closes in two years is not the same as having the silicon to keep it open.
For Engineers Using Mistral: Near-Term vs. Long-Term Impact

If you build on Mistral, the only thing that changes in 2026 is capacity, not your code. The concrete near-term effect is more EU-hosted inference coming online on Nvidia GB300 hardware — the Bruyères-le-Châtel facility runs roughly 13,800 GB300 accelerators at about 44 MW and is expected operational around mid-2026 , with the 10 MW Les Ulis inference site targeted for Q3 2026 . For developers, that means better availability and lower latency for EU-region API calls — and nothing else.
There is no custom-silicon implication today. Mensch's chip comments were explicitly conditional — "owning the chips may come" — and no Mistral-designed accelerator, tape-out, or foundry partner exists . So expect:
- No new SDK surface. No hardware-specific endpoints, flags, or client changes to migrate to.
- No pricing shift. Token economics stay tied to the existing Nvidia-based stack, not to in-house chips.
- No model capability gated behind Mistral-designed hardware. Every model still serves from GB200/GB300 racks .
The long-term case (three to five-plus years, and only if funded) is the one hyperscalers already validated: custom accelerators co-designed with the model could lower per-token cost and lift throughput on Mistral-specific architectures — the exact "cost of deploying tokens" rationale Mensch cited . Treat that as a roadmap input for procurement planning, not a feature you can build against. It depends on a program that does not yet exist.
What is concrete now is the sovereign-compute angle. A French-owned cluster running Mistral models strengthens data-residency and regulatory-compliance claims — GDPR and sector-specific EU rules — for European governments and regulated industries evaluating a non-U.S. provider . If data residency is on your requirements list, that benefit is available today; chip independence is not.
Unanswered: No Foundry, No Tape-Out, No Committed Roadmap
Strip away the framing and Mistral has announced no chip. As of June 2026 there is no disclosed architecture — CPU, inference accelerator, or training chip are all equally undefined — no named target workload, no transistor node, and no foundry or design partner . Mensch's own words were conditional: owning chips "may come," while the company keeps "testing a few things here and there" and relies on Nvidia . That is exploration, not a program.
Two structural gaps make a near-term launch implausible. First, people: no silicon engineering team or dedicated hiring has been disclosed. The hyperscaler precedent is instructive — Amazon's and Google's accelerator efforts staffed hundreds of specialist engineers before reaching first tape-out. Second, money. Mistral already funds compute with debt, having borrowed roughly €725 million against a ~€4 billion data-center commitment across France and Sweden . Competitive AI silicon typically takes years and multiple billions beyond what is currently earmarked, and Mistral has signaled neither the team nor the capital to close that gap.
The honest read: this is a credible long-term sovereignty signal from a CEO publicly committed to a full-stack European AI vision — not a chip launch, not a funded program, and not a timeline you can plan around. Treat the inference buildout as real and shippable; treat the silicon as intent. If you build on Mistral, the actionable change this year is more EU-hosted GB300 capacity, not custom hardware.
Frequently asked questions
Is Mistral building its own AI chips?
No chip program has been announced. Speaking at Mistral's first AI Now Summit on May 28, 2026, CEO Arthur Mensch used conditional language — "owning the chips may come, I think it should come at some point, but for now we are relying on Nvidia" . No foundry partner, silicon team, tape-out, production timeline, or earmarked capital has been disclosed. Treat any "Mistral chip" framing as multi-year intent, not a shipping roadmap.
What is the Mistral EU compute cluster and when does it open?
The largest confirmed facility is a French inference cluster equipped with 13,800 Nvidia GB300 accelerators and roughly 44 MW, expected operational around mid-2026 . A separate 10 MW inference site at Les Ulis (Essonne) targets Q3 2026 . All hardware is Nvidia-based — GB200, GB300 and B300 GPUs — with no custom silicon. Both sit inside Mistral Compute, the integrated infrastructure stack announced June 11, 2025 .
Why did ASML lead Mistral's €1.7B Series C?
ASML makes the EUV lithography tools that are critical for fabricating advanced chips, so its lead role signals value-chain alignment rather than a passive financial round. On September 9, 2025, Mistral closed a €1.7 billion Series C at an €11.7 billion post-money valuation led by ASML, with Nvidia, Andreessen Horowitz, Bpifrance, DST Global and others participating . Both firms framed it as two companies in the same value chain working jointly on semiconductor and AI problems — consistent with long-term silicon intent, but not itself a chip program.
Does Mistral's chip ambition affect its API or pricing today?
No. There is no pricing change, no SDK update, and no model capability tied to custom silicon — that scenario is years out at best. The only near-term, concrete change for developers is more European inference capacity coming online via Nvidia GB300 hardware, which improves EU-region availability and latency for EU-hosted models . If you build on Mistral, plan around the inference buildout, not hypothetical in-house chips.
How does Mistral's approach compare to Amazon Trainium or Google TPU?
Amazon (Trainium/Inferentia) and Google (TPU) designed in-house accelerators only after reaching hyperscaler scale, and both still buy large volumes of Nvidia GPUs — a dual-track model Mensch explicitly cited as the rationale for lowering per-token inference costs . Mistral is far earlier in that trajectory: it is deepening, not reducing, its Nvidia dependence and has not announced the engineering team or capital a comparable silicon program would require .