
On June 2, 2026, a single blog post turned a routine desk-rejection round into a referendum on whether AI-writing detectors are accurate enough to end a paper's life. The NeurIPS 2026 Position Paper Track had run every submission through a commercial detector — and then rejected 178 of them with no ordinary appeal.
What Happened: 178 Rejections, Pangram 3.3.2, No Appeal
NeurIPS 2026 Position Paper chairs used Pangram 3.3.2, a commercial AI-writing detector, to screen every submission to the track and desk-rejected 178 papers — 18.4% of the track — for suspected AI authorship, with no standard appeal path. The decision was disclosed in a June 2, 2026 post by chairs Alex Lu, Seth Lazar, and David Rügamer (with assistant chairs Stanley Hua and Kate Metcalf), which screened the roughly 969–971 Position Paper submissions and applied the track's rule that a paper "must itself be substantially written by human authors" .
Quick Answer: NeurIPS 2026's Position Paper Track desk-rejected 178 papers (18.4% of the track) after running all ~969 submissions through the Pangram 3.3.2 AI detector, per the chairs' June 2, 2026 post. A further 123 papers (12.7%) are conditional and must submit provenance evidence by June 15 or be rejected.
Beyond the 178 rejections, the chairs placed 123 papers (12.7%) in a conditional group: those authors must submit provenance evidence — version history identifying pre-AI, post-AI, and final checkpoints — by June 15, 2026, or face rejection . Crucially, the enforcement applied only to the Position Paper Track. The NeurIPS 2026 Main Program takes the opposite stance: its handbook lets authors use any tool to prepare and write papers, with no documentation required for editing aid, grammar suggestions, or basic code assistance, as long as the authors remain responsible for correctness .
The outcome distribution across the track:
| Outcome | Papers | Share of track | Consequence |
|---|---|---|---|
| Desk-rejected | 178 | 18.4% | Rejected, no ordinary appeal |
| Conditional | 123 | 12.7% | Submit provenance by June 15, 2026 or be rejected |
| Cleared | ~668 | ~68.9% | Proceed to review |
NeurIPS's own figures carry a caveat worth flagging upfront: the post's text cites 969 submissions in one place while an accompanying table lists 971, and the discrepancy is unresolved in the public record — so submission counts here should be read as approximate . What is not approximate is the scale of the action and the fact that the screening tool, Pangram 3.3.2, had shipped only weeks earlier in May 2026 .
How Pangram Segments and Flags Submitted Papers
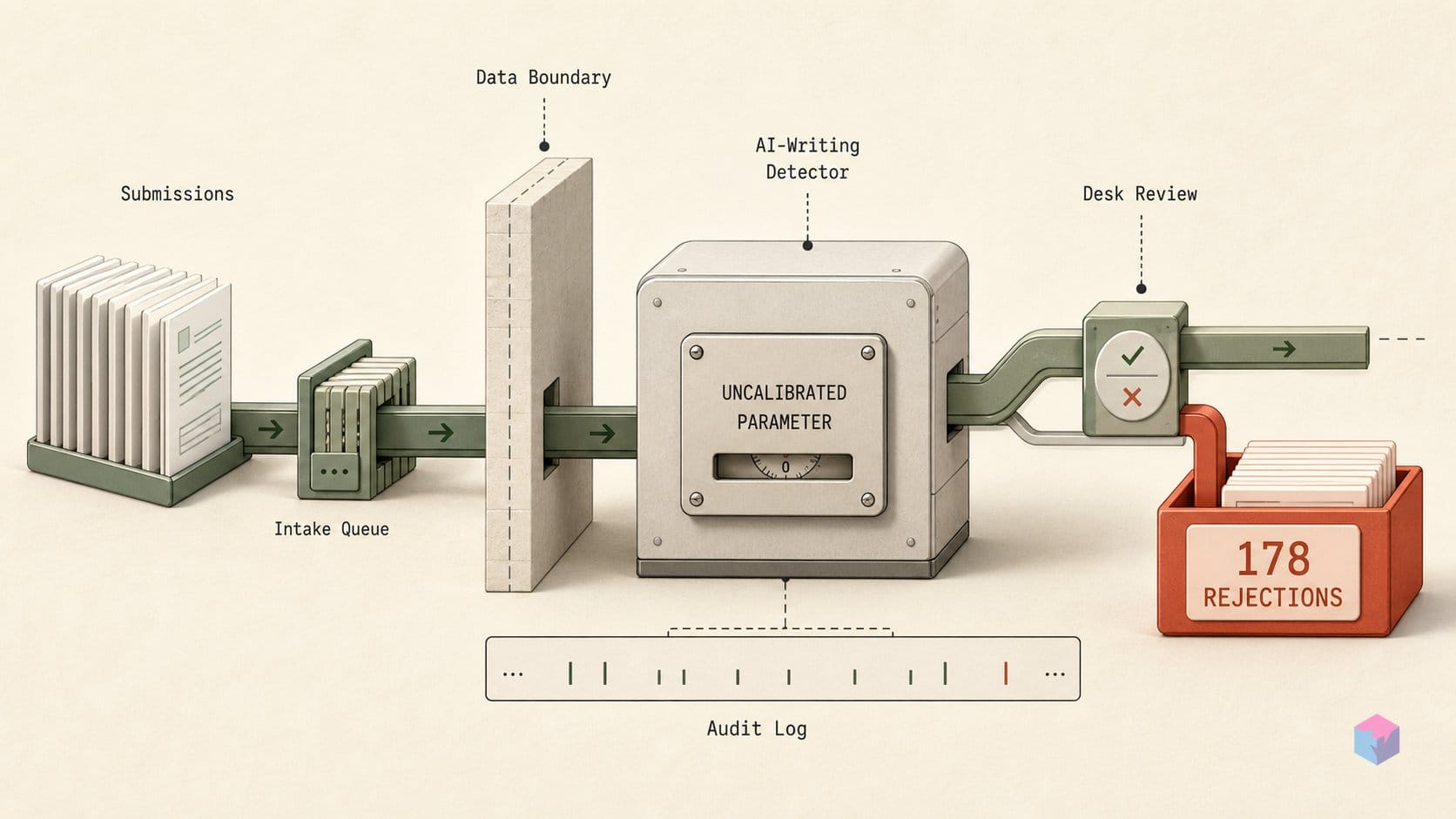
Pangram does not judge a paper as a single blob of text. It splits a document into fixed-size text windows, assigns each window an independent AI probability, flags any window above a 0.75 probability threshold, and then reports the paper's headline "Pangram AI score" as the percentage of windows that were flagged . The critical consequence: a 100% score means every window crossed the threshold, not that 100% of the words were machine-generated. The metric measures how many chunks looked AI-like, not how much of the prose actually was.
That distinction matters because the chunk size is a parameter, and the score moves with it — a sensitivity the next section examines in detail. For now, the mechanic to hold onto is that the score is a count of flagged windows divided by total windows, so the number that drove rejections is a derived percentage, not a direct word-level measurement .
The version timeline tightens the picture. Pangram 3.3 shipped May 13, 2026, followed by a 3.3.1 segmentation update on May 15 and a 3.3.2 bugfix on May 18 that the company said could alter under 3% of predictions . NeurIPS ran 3.3.2 — the model that had been public for roughly three weeks when desk rejections went out.
On accuracy, Pangram's published numbers are genuinely strong. Its 3.3 model card reports an Academic Writing (English) false-positive rate of 0.02% across 62,971 samples and a Biomedical Research Papers FPR of 0.01% across 65,053 samples . But the same card flags conditions that raise false-positive risk: dense equations, PDF parsing artifacts, reference lists, and templated writing — exactly the structural features that define a formal academic position paper. The detector is reliable on prose that reads like prose; the question is what it does with the equation-and-citation-dense documents it was pointed at here.
An Undisclosed Setting Drove a 30-Point Swing in Flagging
The single most consequential choice in the whole procedure was a window-size parameter that authors never saw. Under Pangram's default segmentation — roughly 250–350-word windows — 42.7% of Position Paper Track submissions returned an AI score ≥0.9, and 28.2% scored a full 100% (about 273 of 969 papers) . When the chairs re-ran the same documents through a "medium" ~100-word windowing strategy, the ≥0.9 rate dropped to 12.7% and the 100% rate collapsed to 2.16% . That is a roughly 30-percentage-point swing on the ≥0.9 figure, produced by nothing more than how the text was sliced.
| Configuration | Window size | ≥0.9 flagging rate | 100% flagging rate |
|---|---|---|---|
| Default (used for rejections) | ~250–350 words | 42.7% | 28.2% |
| "Medium" | ~100 words | 12.7% | 2.16% |
NeurIPS ran its desk-rejection procedure on the default, larger-chunk configuration . Authors were not told which segmentation strategy had been applied to their work, so a paper that would have cleared the bar under one setting could be flagged under another with no notice. The mechanism behind the swing is structural: larger windows average more text per probability estimate, and in equation-, reference-, and template-dense academic writing that averaging pushes more windows above Pangram's 0.75 flag line — inflating the share of flagged windows that becomes the reported paper score.
The same parameter undercuts the comparison the chairs leaned on. They anchored their suspicion in venues with far lower default-window rates — FAccT 2022, FAccT 2025, and the NeurIPS Datasets & Benchmarks 2025 track . But if a single segmentation choice can move the ≥0.9 rate by 30 points, then a gap between this track and those comparators may reflect document structure and chunking interactions as much as any real difference in authorship behavior. The NeurIPS Ethics & Datasets 2026 comparator itself jumped sharply versus 2025 , which suggests the baseline was not stable enough to treat as a clean control.
For a developer, the takeaway is concrete: when a detector's output feeds a discrete, no-appeal decision, the pipeline's hidden hyperparameters are part of the decision. A 250-word default versus a 100-word setting is not a cosmetic toggle here — it is the difference between flagging 28% of submissions at 100% and flagging 2%.
The Exact Thresholds and Heuristics Used to Reject 178 Papers
The 178 desk rejections were not a single cutoff but three stacked rules, each pairing a Pangram score band with a different secondary signal . Reading the tiers in order shows how much weight the score carried alone versus how much depended on author-level heuristics layered on top of it.
- Tier A — 77 papers: a Pangram rating of ≥0.9 with no additional condition was sufficient on its own for desk rejection . Here the detector output was the entire basis for the decision.
- Tier B — 79 papers: a rating of ≥0.8 combined with an author-level signal — multiple solo-authored submissions, or a separate desk-reject signal — pushed these into rejection . The score alone was treated as insufficient; a behavioral heuristic had to corroborate it.
- Tier C — 22 papers: a rating of ≥0.5 where authors declared no AI use, or made no declaration at all . The attestation itself became the secondary signal that lowered the score threshold.
Separately, 123 papers (12.7% of the track) landed in a conditional group: a rating of ≥0.8 and <0.9 with no additional condition . These authors were not rejected outright but were required to submit provenance evidence by June 15, 2026 — a version history identifying pre-AI, post-AI, and final checkpoints, plus an analysis of whether AI edits introduced new substantive content — or be rejected .
One detail undercuts the precision the tiers imply: the counting does not fully reconcile. The post body reports the 100% cohort as 273 of 969 submissions, while an accompanying table lists 971 papers . The denominator discrepancy is left unresolved in the public record, so the submission counts — and any percentage derived from them — should be treated as approximate. For a procedure issuing no-appeal rejections, an unexplained two-paper drift in the base population is the kind of bookkeeping gap that matters: it is the same data that anchors every threshold rate cited above.
The Calibration Gap: What the Public Record Does Not Include
The calibration gap is the absence of any published evidence that the full desk-rejection rule was validated against the population it judged. As of June 9, 2026, the public NeurIPS post contains no raw distribution of rejected-paper Pangram scores, no ground-truth validation set drawn from actual 2026 Position Paper submissions, no confidence intervals, no calibration curves, and no analysis of PDF parsing artifacts . What is missing is not the detector's reported accuracy but a demonstration that the compound procedure behaves as intended on this specific corpus.
That distinction matters because the published false-positive rates describe Pangram's classifier in isolation, not the decision rule built on top of it. The 3.3 model card reports an Academic Writing (English) FPR of 0.02% (N=62,971) and a Biomedical Research Papers FPR of 0.01% (N=65,053) , and a September 2025 NBER working paper (w34223) found Pangram was the only evaluated detector meeting a strict FPR ≤0.005 cap without losing accuracy . None of those figures characterize the actual rule used here — detector output combined with the AI-use attestation and author-level heuristics. The error rate of that combined procedure is undisclosed.
The same model card warns that references, technical manuals, templated writing, dense equations, and parsing artifacts raise false-positive risk — exactly the textual features that saturate formal position papers. Pangram set the bar for its own tooling in a November 2025 analysis:
"A nonzero false-positive rate creates a responsibility to quantify reliability before recommending discrete paper-fate decisions such as desk rejection," — Pangram, November 2025 analysis (source: Pangram).
The chairs' procedure did not clear that bar publicly. Their validation rested on 10 generated position papers and 10 selected FAccT 2022 text windows tested across 12 AI-use scenarios, alongside comparator venues such as FAccT 2022, FAccT 2025, and NeurIPS Datasets & Benchmarks 2025 . A 2026 arXiv study found that strong in-domain detector performance can collapse under cross-domain and cross-generator evaluation, because models lean on dataset-specific stylistic cues rather than a stable signal. A 10-sample synthetic experiment and out-of-venue comparators do not constitute distribution-matched validation for the NeurIPS 2026 Position Paper population — which is the population that absorbed 178 no-appeal rejections.
What Critics Said About the Procedure

Critics of the procedure attacked two distinct weaknesses: a logical circularity in how decisions were reached, and the claim that ordinary human writing reliably trips the detector. Affected author Sergey Berezin argued on June 3, 2026 that because the materials weighed for rejection were Pangram's output combined with each author's AI-use attestation, the attestation was effectively being judged by the detector itself — a circularity, since a denial of AI use carries no weight against a high score . He also held that FAccT controls and chair-generated synthetic papers cannot establish a false-positive rate on real NeurIPS 2026 submissions under distribution shift.
To illustrate, Berezin reported running Pangram on recent 2026 papers by the track chairs themselves and observing scores of 69%, 45%, 36% and 24% — while explicitly not alleging AI authorship, the point being that nonzero scores appear on writing presumed human .
Other researchers pointed at stylistic confounds. Pasquale Minervini of UCL NLP said he was roughly "80% sure" his largely human drafts would be flagged, citing habits such as frequent em-dashes . Panos Ipeirotis warned that using an LLM for grammar checking now reads as "AI-written" under detectors like Pangram, penalizing a workflow the Main Track explicitly permits. Jessica Hullman framed the deeper category error directly.
"Detectors measure who strung the words together, not the substantive human contribution to the ideas," — Jessica Hullman, summarizing the critics' objection (source: Startup Fortune).
The wider tooling record supports caution. OpenAI discontinued its own AI-text classifier on July 20, 2023, citing low accuracy and warning it should not serve as a primary decision-making tool . Turnitin's official guidance likewise states that AI-detection output should not be the sole basis for adverse action . Against that backdrop, anchoring 178 no-appeal rejections substantially on a single detector's score runs counter to how the vendors of detection themselves recommend the technology be used .
Where 2026 Venue Policy Is Heading
The NeurIPS episode lands in a year where venues are diverging sharply on what "AI-assisted writing" even means. ICLR 2026 adopted a harder line than NeurIPS: undisclosed LLM use draws immediate rejection, a stricter posture than the NeurIPS 2026 Main Program, which lets authors use any tool to prepare and write papers and requires no documentation for spell-checking, grammar, editing aid, or basic code assistance . Two committees at the same conference reached opposite operating defaults in the same cycle.
The instruments differ as much as the policies. GPTZero separately claimed to have found roughly 100 hallucinations in accepted NeurIPS 2025 papers — a different tool, a different target (factual errors in the accepted mainstream rather than authorship in a single track), and a different implicit claim about how AI is already woven into published work. Detection of fabricated content and detection of who "strung the words together" are not the same measurement, and conflating them muddies the policy debate.
The pivot was also abrupt. The inaugural 2025 Position Paper Track screened desk rejections entirely by hand and used no AI in the process ; the 2026 track moved to automated enforcement in one cycle, with no published comparative accuracy data between the two approaches .
The concrete takeaway: when one venue allows any writing tool with no paperwork while a sibling track at the same venue desk-rejects on a detector score, the gap is not a detail to reconcile later — it is the unresolved question. Until conferences agree on whether they are policing fabrication, disclosure, or human authorship, expect more single-cycle reversals, and read each venue's actual handbook before you submit rather than assuming a shared standard exists.
Frequently asked questions
What is a desk rejection, and why is there no appeal for affected NeurIPS authors?
A desk rejection is an administrative rejection issued before a paper reaches peer review — a screening decision, not a reviewer verdict. NeurIPS used it here as a policy-enforcement mechanism for the Position Paper Track, issuing 178 such rejections (18.4% of the track) without ordinary appeal . The reason there is no appeal is structural: peer-review appeal channels cover review outcomes, and the chairs did not open a separate appeal path for these pre-review administrative decisions. The 123 "conditional" cases (12.7%) are the only group offered a remediation route, and that route is an evidence submission, not an appeal .
What does a 100% Pangram AI rating actually mean for a submitted paper?
A 100% Pangram AI score means every text window the tool segmented was flagged — each assigned an AI probability above 0.75 — not that 100% of the words were written by AI . Pangram splits a document into windows, scores each one, flags those above 0.75, and reports the score as the percentage of flagged windows. Because the metric is window-level, the rating depends entirely on how large those windows are — a parameter authors were never shown. Under default windowing, 28.2% of Position Paper submissions returned a 100% score .
Why does chunk size change the flagging rate so dramatically?
Window size changes the rate because shorter windows capture more local stylistic variation, making it harder for any single window to look uniformly AI-generated, while larger windows average across more text so one AI-like passage can dominate the window's probability. NeurIPS documented the effect directly: switching from default ~250–350-word windows to a "medium" ~100-word strategy dropped the ≥0.9 rate from 42.7% to 12.7% and the 100% rate from 28.2% to 2.16% — roughly a 30-point swing on a setting authors never saw .
What must the 123 conditional-group authors submit by June 15, 2026?
Conditional-group authors — those with a Pangram score ≥0.8 and <0.9 and no additional considerations — must submit provenance evidence by June 15, 2026, or be rejected with no further review . Specifically, that means version history identifying pre-AI, post-AI, and final manuscript checkpoints, plus an analysis of whether AI edits introduced new substantive content. This is a documentation burden placed on the author to rebut a detector score, not an appeal of the underlying decision.
Does Pangram itself recommend using its tool as the sole basis for paper rejection?
No. In a November 2025 analysis, Pangram argued that its nonzero false-positive rate creates a responsibility to quantify reliability before recommending discrete paper-fate decisions such as desk rejection . This aligns with broader detector guidance: OpenAI discontinued its own classifier on July 20, 2023 for low accuracy and warned against using it as a primary decision-making tool, and Turnitin's official guidance states AI-detection output should not be the sole basis for adverse action . The NeurIPS chairs acknowledged the tension but proceeded with the automated procedure anyway .





