
NVIDIA's Parakeet speech models used to mean a Python stack: NeMo, PyTorch, and a GPU you kept warm. A new C++ port collapses that to one binary and one file.
From NeMo to GGUF: What the Port Covers
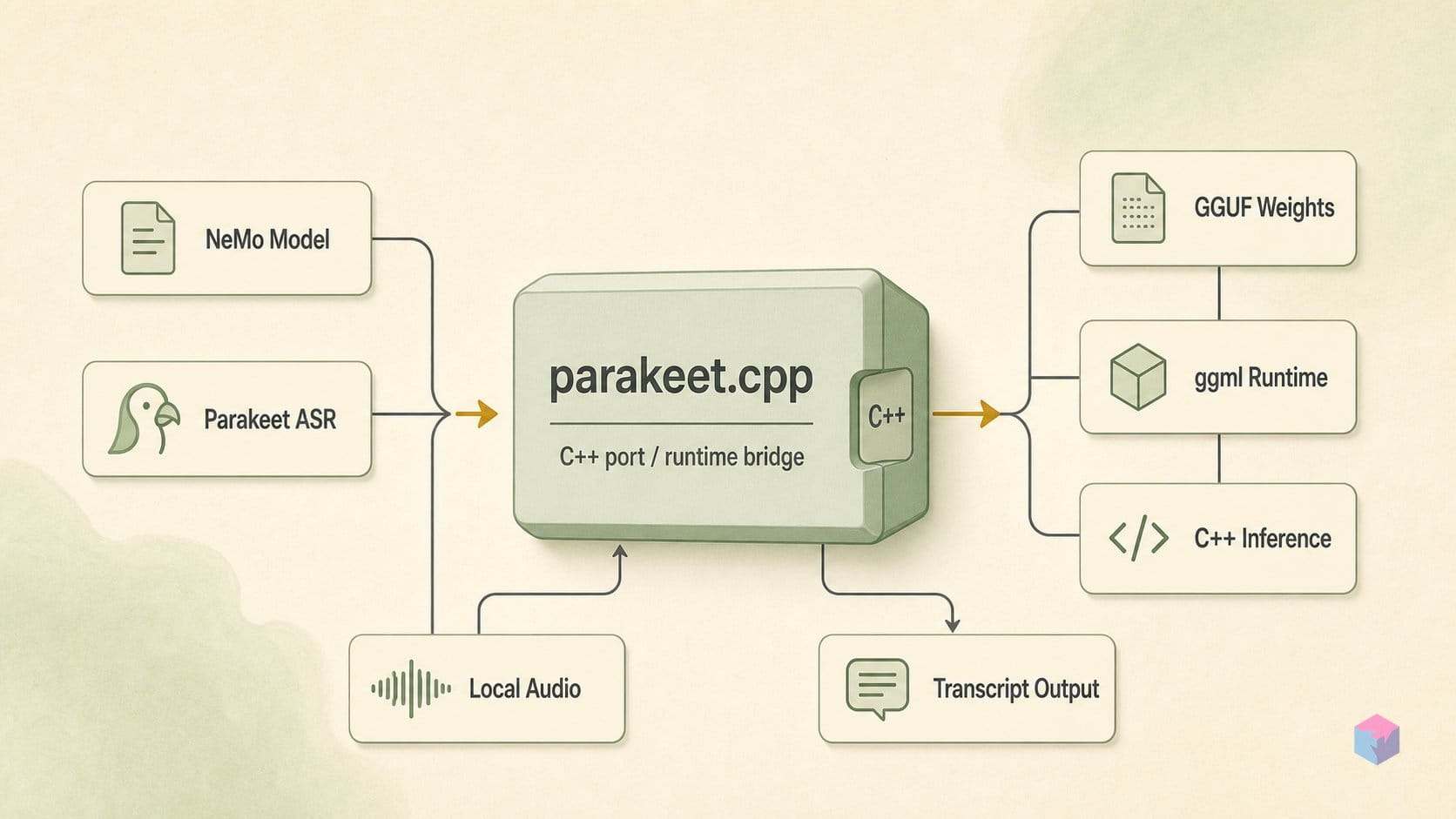
parakeet.cpp is a C++17 inference port that runs NVIDIA's Parakeet automatic speech recognition (ASR) models on the ggml tensor library — the same engine behind whisper.cpp and llama.cpp — with no Python, no NeMo, and no ONNX at inference time. The project is maintained by Ettore Di Giacinto (@mudler), author of LocalAI, and its first tagged release, v0.1.0, landed on May 30, 2026 . The code is MIT-licensed; the model weights keep their original NVIDIA Parakeet licenses. This is a community project, not an official NVIDIA release.
The port covers the offline Parakeet families — CTC, RNNT, TDT and hybrid TDT-CTC — in 110M, 0.6B and 1.1B sizes, plus a streaming 120M model with end-of-utterance detection . Two checkpoints anchor most use: parakeet-tdt-0.6b-v2, the English default that reports 6.05% average WER on the Hugging Face Open ASR Leaderboard and was released 05/01/2025 , and parakeet-tdt-0.6b-v3, which extends the same 600M FastConformer-TDT architecture to 25 European languages with automatic language detection, released 08/14/2025 .
Inference runs on CPU, CUDA, HIP (AMD ROCm), Vulkan and Metal (Apple Silicon) — the same ggml backend matrix as whisper.cpp and llama.cpp — so deployment reduces to one binary plus one GGUF file .
The hard part was mapping Parakeet's RNNT/TDT decoders onto a static-graph tensor library. An earlier work-in-progress port surfaced on Hacker News in mid-2025, where the author flagged how far there was to go:
"The GGML build is roughly 1000x slower than the MLX Python version" — jason-ni, reporting an early Parakeet-on-ggml experiment (source: Hacker News, 2025; see also the jason-ni port).
The mudler release is the matured answer to that decoder-on-static-graph problem, and as of June 2026 Parakeet is not yet merged into mainline whisper.cpp — an open feature request (issue #3118) still tracks it, so parakeet.cpp remains the route.
What to Gather Before Compiling
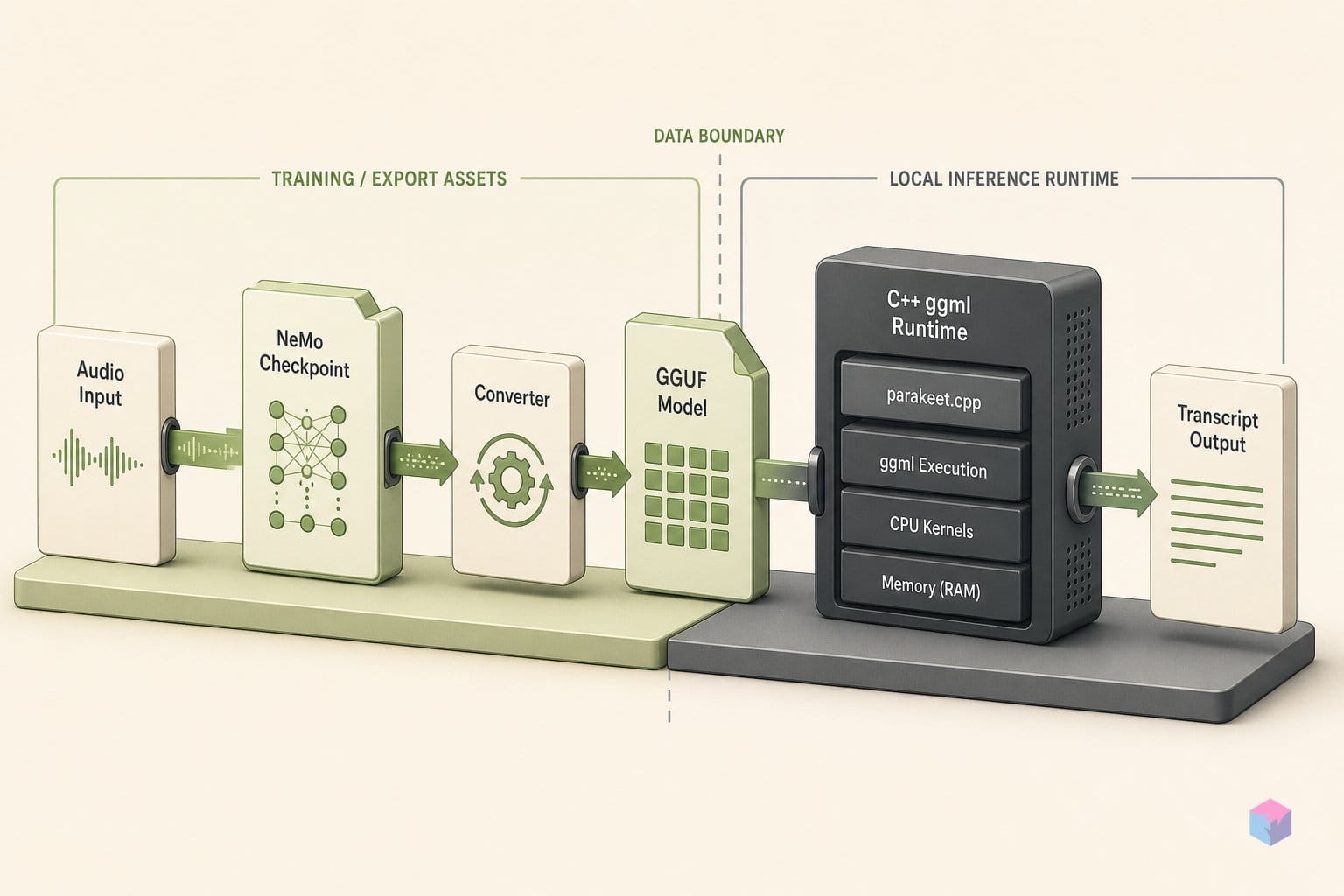
parakeet.cpp builds with a standard C++ toolchain and nothing exotic: CMake (3.x), a C++17 compiler (gcc, clang, or MSVC), and git with submodule support, since ggml is pulled in as a submodule during the recursive clone . The CPU path needs no further dependencies. GPU support is opt-in at compile time — CUDA toolkit for CUDA, ROCm for HIP, the Vulkan SDK for Vulkan, and the Xcode command-line tools for Metal — so you only install the stack for the backend you actually target .
Python is not part of the inference path. You need it (with NeMo 2.7.3, the validated version) only if you are converting a custom .nemo checkpoint to GGUF; the pre-converted weights already cover all 10 published offline checkpoints, and transcription itself is pure C++ .
One input constraint to plan for: audio must be 16 kHz mono WAV or FLAC . Anything else — stereo, MP3, 44.1 kHz — should be down-converted first with ffmpeg before you hand it to the transcriber.
Compile, Download Weights, and Transcribe in Three Commands
Once your audio is 16 kHz mono, the working path from source to transcript is three commands: clone-and-build, download a GGUF, and run the CLI. The default build is CPU-only and pulls in no Python, NeMo, or ONNX at runtime — just CMake, a C++17 compiler, and the bundled ggml submodule .
Step 1 — Clone and compile. The --recursive flag matters; ggml is vendored as a submodule.
git clone --recursive https://github.com/mudler/parakeet.cpp
cd parakeet.cpp
cmake -B build -DPARAKEET_BUILD_CLI=ON && cmake --build build -jFor GPU, add one backend flag: -DPARAKEET_GGML_CUDA=ON (NVIDIA), -DPARAKEET_GGML_METAL=ON (Apple Silicon), -DPARAKEET_GGML_HIP=ON (AMD), or -DPARAKEET_GGML_VULKAN=ON. Use -DGGML_NATIVE=OFF for portable or CI builds that must run on hardware other than the build host .
Step 2 — Download weights. Pre-converted GGUF files live at mudler/parakeet-cpp-gguf. F16 is the recommended default — same accuracy as F32, roughly 1.7x faster on modern CPUs, and 57% of F32 size .
huggingface-cli download mudler/parakeet-cpp-gguf tdt-0.6b-v2-f16.gguf --local-dir models/| Variant (tdt-0.6b-v2) | Size | Notes |
|---|---|---|
| F16 | 1404 MB | Recommended default |
| Q8_0 | 904 MB | Near-lossless |
| Q4_K | 638 MB | Small monotonic accuracy cost |
| v3 F16 (multilingual) | 1441 MB | 25 European languages |
Sizes per the model card .
Step 3 — Transcribe. Add --timestamps for per-word timing and confidence, and --json for structured output.
build/examples/cli/parakeet-cli transcribe \
--model models/tdt-0.6b-v2-f16.gguf \
--input audio.wav --timestamps --jsonForce a decoder head with --decoder tdt or --decoder ctc; for real-time captioning, run the 120M end-of-utterance model with --stream . Inspect any file before loading with parakeet-cli info model.gguf, and re-quantize an F32 GGUF locally with parakeet-cli quantize m.gguf m_q4k.gguf q4_k — supported formats are q4_0, q5_0, q8_0, q4_k, q5_k and q6_k. Quantization is selective: only the large linear weights hit by ggml_mul_mat are compressed, while conv kernels, norms, the LSTM prediction net, and embeddings stay F32 .
Caveats: Own-Harness WER, Quantization Tradeoffs, and the whisper.cpp Gap

Treat parakeet.cpp's parity claim as a regression test, not a production guarantee. The project reports that all ten published offline checkpoints (v2, v3, CTC, RNNT, TDT and hybrid) validate at WER 0.0 against NeMo 2.7.3 — but that figure was measured on a single 7.4-second LibriSpeech fixture . It confirms the C++ decoder matches NeMo for that harness; it says nothing about noise, speaker variation, domain shift, or all 25 languages in v3. Validate on your own audio before shipping.
The performance numbers carry the same asterisk. On the project's own suite — a 20-core host, batch size 1, 100 LibriSpeech test-clean utterances — NeMo CPU measured RTFx 22.4 versus parakeet.cpp f32 at 32.4 and q8_0 at 34.7, with resident memory of 5,499 MB for NeMo against 2,545 MB for the f32 port . These are the port's own figures; reproduce them on target hardware before committing to a latency SLA.
"Transcript parity for this harness is not a guarantee of identical real-world WER across domains, speakers, noise or languages," — parakeet.cpp parity report (source: mudler/parakeet.cpp).
Two ecosystem facts shape your choice. Parakeet is not merged into mainline whisper.cpp as of June 2026; issue #3118 tracks the parakeet-tdt-0.6b-v2 request, so parakeet.cpp remains the only supported ggml path . For SLA-backed serving with diarization, NVIDIA's ASR NIM packages the same models in TensorRT/Triton but requires a compute-capability 8.0+ GPU with at least 16 GB VRAM . The takeaway: ship NIM when you need enterprise support and have the GPU; reach for the GGUF route for CPU, edge, or privacy-sensitive on-device transcription where a Python runtime is a liability.
Frequently asked questions
Does parakeet.cpp support GPU acceleration?
Yes. parakeet.cpp ships ggml backends for CUDA (NVIDIA), HIP (AMD/ROCm), Vulkan, and Metal (Apple Silicon), each toggled at compile time with a CMake flag such as -DPARAKEET_GGML_CUDA=ON or -DPARAKEET_GGML_METAL=ON (mudler/parakeet.cpp). The CPU path needs no GPU flag and works out of the box; set PARAKEET_DEVICE=cpu to force it. The project reports GPU speedups up to 4.3x on large TDT/hybrid models, but reproduce that on your own hardware before relying on it.
Do I need Python or NeMo installed to use parakeet.cpp in production?
No. Inference is pure C++ with no Python, NeMo, or ONNX runtime dependency. Python and NeMo 2.7.3 are needed only once, to convert a custom .nemo checkpoint to GGUF. All 10 published offline checkpoints already have pre-converted GGUF weights on Hugging Face at mudler/parakeet-cpp-gguf, so a typical deployment is one binary plus one model file (mudler/parakeet.cpp).
How does parakeet.cpp accuracy compare to whisper.cpp large-v3-turbo on English?
The English default, parakeet-tdt-0.6b-v2, reports 6.05% average WER on the Hugging Face Open ASR Leaderboard . Whisper large-v3-turbo is a multilingual model measured under different noise and domain conditions, so the two numbers are not directly comparable. For a valid result, run both on your own audio — leaderboard WER is a starting signal, not a guarantee for your domain.
Which GGUF quantization format should I use?
F16 is the recommended default: it matches F32 accuracy, runs about 1.7x faster on modern CPUs via ggml's F32xF16 matmul path, and is roughly 57% of F32 size . Q8_0 is about 37% of F32 size with minimal accuracy loss, and Q4_K is about 26% with a small, monotonic accuracy cost — reach for Q4_K only when memory is the hard constraint.
Can parakeet.cpp handle languages other than English?
Yes. parakeet-tdt-0.6b-v3 extends the same 600M FastConformer-TDT architecture to 25 European languages with automatic language detection, released on Hugging Face on 2025-08-14 . Its GGUF is 1441 MB at F16 and handles up to 3 hours of audio with local attention on an A100 80GB . The v2 family is English-only (1404 MB at F16).





