
3년간 AI 코딩 도구 구매자들이 던진 질문은 단순했다. 자동완성이 얼마나 빠른가? Gartner의 2026년 재정의는 조용히 그 질문을 폐기했다 — 하지만 대부분의 구매 평가표는 아직 따라오지 못했다.
어시스턴트에서 에이전트로: Gartner가 이제 측정하는 것
Gartner는 코딩 도구 평가 범위를 자동완성에서 자율성으로 재설정했다. 이 회사는 'Magic Quadrant for AI Code Assistants'(문서 번호 6948266)를 'Magic Quadrant for Enterprise AI Coding Agents'(문서 번호 7879277)로 개명해 2026년 5월 20일 발행했다 . 새로운 기준은 코드 한 줄 자동완성이 아니다 — 도구가 다단계 구현을 계획하고, 자체적으로 테스트를 실행하고, 오류를 디버깅하고, 사람이 검토할 풀 리퀘스트를 생성할 수 있는지 여부다.
이 이름 변경은 화장품 수준의 변화가 아니라 의도적인 범위 확장이다. 이전 판은 사용자가 타이핑할 때 코드를 제안하는 에디터 내 어시스턴트를 측정했다. 2026년 판은 워크플로 전반에 걸쳐 작동하는 에이전트를 측정한다 — 낯선 코드베이스를 읽고, 개발자 도구를 사용하고, 변경 사항을 적용하고, 테스트를 실행하고, PR 중심 작업을 준비하는 에이전트를 . Gartner의 해석은 시장 자체가 이동했다는 것이다: 가치의 단위가 제안에서 완성되고 검토 가능한 작업으로 전환됐다.
자금은 재정의를 따른다. 보고서와 함께 인용된 2차 애널리스트 추정치는 2026년 4월 기준 연간 환산 시장 규모를 약 98억~110억 달러로 산정했다 — 벤더 포지셔닝이 실제 구매 결정에 영향을 줄 만큼 충분히 큰 카테고리다.
벤더 평가를 진행하는 사람에게 직접적인 함의가 있다: 자동완성 지연 시간이나 제안 수락률을 기준으로 설계된 RFP는 이제 잘못된 축을 측정하고 있다. 평가표가 에이전트가 티켓을 분해하고, 테스트 스위트를 실행하고, 빌드 실패에서 복구하고, 깔끔한 diff를 반환할 수 있는지 검증하지 않는다면, 그것은 이전 세대 도구를 채점하는 것이다. 이 시리즈의 나머지 부분은 그 전환이 드러내는 것을 파고든다 — 즉시 맞닥뜨릴 문제부터 시작해서: 리더 명단 전체를 실제로 볼 수 없어 어떤 것도 검증할 수 없다는 점이다.
한 가지 주의할 점: Gartner는 자사 출판물이 사실 진술이 아니라 의견임을 명시한다. 기초 그래픽은 클라이언트 유료 장벽 뒤에 있다. 재정의 자체는 실재한다. 이어지는 구체적인 위치 배치는 확인해야 할 주장으로 취급하고, 확정된 기록으로 보지 말라.
검증 문제: 전체 리더 명단을 볼 수 없는 이유
전체 리더 명단은 공개적으로 검증할 수 없다. 접근 제한이 없는 유일한 Gartner 텍스트가 헤드라인과 모순되기 때문이다. gartner.com/en/documents/6948266에서 여전히 볼 수 있는 초록은 'Magic Quadrant for AI Code Assistants'라는 제목으로 2025년 9월 15일 발행됐으며 갱신일은 2026년 5월 20일이고, 공개된 14개 벤더 목록에 OpenAI는 포함되어 있지 않다 . 따라서 벤더 검토에서 'OpenAI는 Gartner 리더'라고 인용하기 전에, 비구독자가 읽을 수 있는 기본 문서가 더 좁은 내용을 담고 있음을 알아야 한다.
공개 목록은 다음과 같다: Alibaba Cloud, Amazon, Anysphere (Cursor), Augment Code, Cognition (Windsurf), GitHub, GitLab, Google Cloud, Harness, IBM, JetBrains, Qodo, Tabnine, Tencent Cloud . 동반 Critical Capabilities 초록(문서 번호 6953766)에도 같은 14개 이름이 있으며 마찬가지로 OpenAI를 제외한다 .
가장 그럴듯한 조화는 모순이 아니라 타이밍의 문제다. 별도의 문서 번호 7879277이 'Enterprise AI Coding Agents'로 개명된 판에 존재하며, 이는 클라이언트 전용 게이트 콘텐츠다 . 공개 초록이 단순히 게이트된 2026년 5월 20일 갱신 이전 버전이라면, 재범위화된 쿼드런트와 OpenAI 배치는 유료 장벽 뒤에만 존재하고, 무제한 접근 페이지는 이전 보고서의 오래된 스냅샷이다. 이것은 증거에 부합하지만 추론이지 확인이 아니다.
실질적으로 이것이 의미하는 바: OpenAI가 리더라는 모든 주장은 OpenAI 자체 발표와 그 이후 기술 언론 요약으로 거슬러 올라간다 . 기초 그래픽, 축 기준과 그 가중치, 전체 리더 명단은 Gartner 구독 없이는 검증할 수 없다. 벤더가 자신의 순위에 대한 유일한 출처일 때, 그 격차는 중요하다.
Gartner는 이 부분의 인식론을 명시한다. 표준 면책 조항에 따르면 자사의 연구 출판물은 "Gartner 연구 조직의 의견으로 구성되며 사실 진술로 해석되어서는 안 된다" . 그 주의사항을 염두에 두고 읽으면, 이 인정은 분석된 벤더에 상당 부분 기반한 방어 가능한 애널리스트 의견이다 — 유용한 신호이지 확정된 기록이 아니다. 이어지는 배치는 확인해야 할 주장으로 취급하라.
2026 쿼드런트 해석: 선정된 리더·비저너리와 빠진 것들
2026년 쿼드런트에서 보고된 포지션은 네 개 벤더를 중심으로 형성됩니다. GitHub Copilot, OpenAI Codex, Cursor는 리더 영역을 공유하고, Tabnine은 한 단계 아래 비저너리에 자리합니다. 이 정보는 공개 요약본에 나와 있지 않으므로, 아래 각 포지션은 유료 가트너 그래픽이 아닌 벤더 게시물과 2차 기술 언론의 재구성을 출처로 합니다 — 방향 파악에는 유용하지만 확인 수단으로 쓰기엔 한계가 있습니다.
GitHub Copilot은 실행 역량(Ability to Execute) 축에서 가장 높은 순위를 기록한 것으로 보고되는데, 이 축은 가트너가 제품 납품력과 시장 견인력을 측정하는 데 사용하며, 최대 설치 기반·가장 넓은 IDE 커버리지·높은 엔터프라이즈 고객 밀도가 반영된 결과입니다 . OpenAI Codex는 나란히 리더로 선정되었으며, 가트너는 Codex의 에이전틱 소프트웨어 개발, OS 수준 샌드박싱, 엔터프라이즈 거버넌스를 높이 평가한 것으로 전해집니다 . Cursor(Anysphere)는 비전 완성도(Completeness of Vision) 축에서 가장 강세를 보이는 포지션으로, 가장 빠르게 성장 중인 독립 툴이자 설계상 모델 무관(model-agnostic) 방식을 채택했으며, 독립적인 풀 리퀘스트 연구에서도 높은 수용률을 기록합니다 — 2026년 2월 arXiv에 게재된 7,156건의 PR 분석 결과, 모든 태스크 유형에서 압도적으로 우위를 점한 단일 에이전트는 없었습니다 . Tabnine은 리더가 아닌 비저너리에 위치하며, 규제 산업을 위한 온프레미스 및 에어갭 배포로 차별화합니다 .
| 벤더 | 보고된 포지션 | 강점 축 | 핵심 차별점 |
|---|---|---|---|
| GitHub Copilot | 리더 | 실행 역량 (최상위) | 최대 설치 기반, 가장 넓은 IDE 커버리지, 높은 엔터프라이즈 고객 밀도 |
| OpenAI Codex | 리더 | 에이전틱 실행 + 거버넌스 | OS 수준 샌드박싱, RBAC, 승인 게이트 |
| Cursor (Anysphere) | 리더 | 비전 완성도 (최상위) | 모델 무관, 가장 빠르게 성장 중인 독립 툴 |
| Tabnine | 비저너리 | 배포 유연성 | 규제 산업을 위한 온프레미스/에어갭 배포 |
선정되지 않은 것이 선정된 것만큼 중요합니다. 독립 분석에 따르면 2026년 4월 기준 잠재 시장 규모는 연환산 약 98억~110억 달러에 달합니다 . 따라서 리더 명단 재편은 실질적인 예산 영향을 수반합니다 — 그러나 전체 리더 목록, 나머지 쿼드런트 티어, 이 포지션을 도출한 기준 가중치는 모두 유료 고객에게만 공개됩니다. 위의 네 포지션은 벤더와 2차 언론이 공개하기로 선택한 정보이며, 차트의 나머지 부분은 미확인 상태로 봐야 합니다.
샌드박싱·RBAC·승인 게이트: 새롭게 높아진 기준
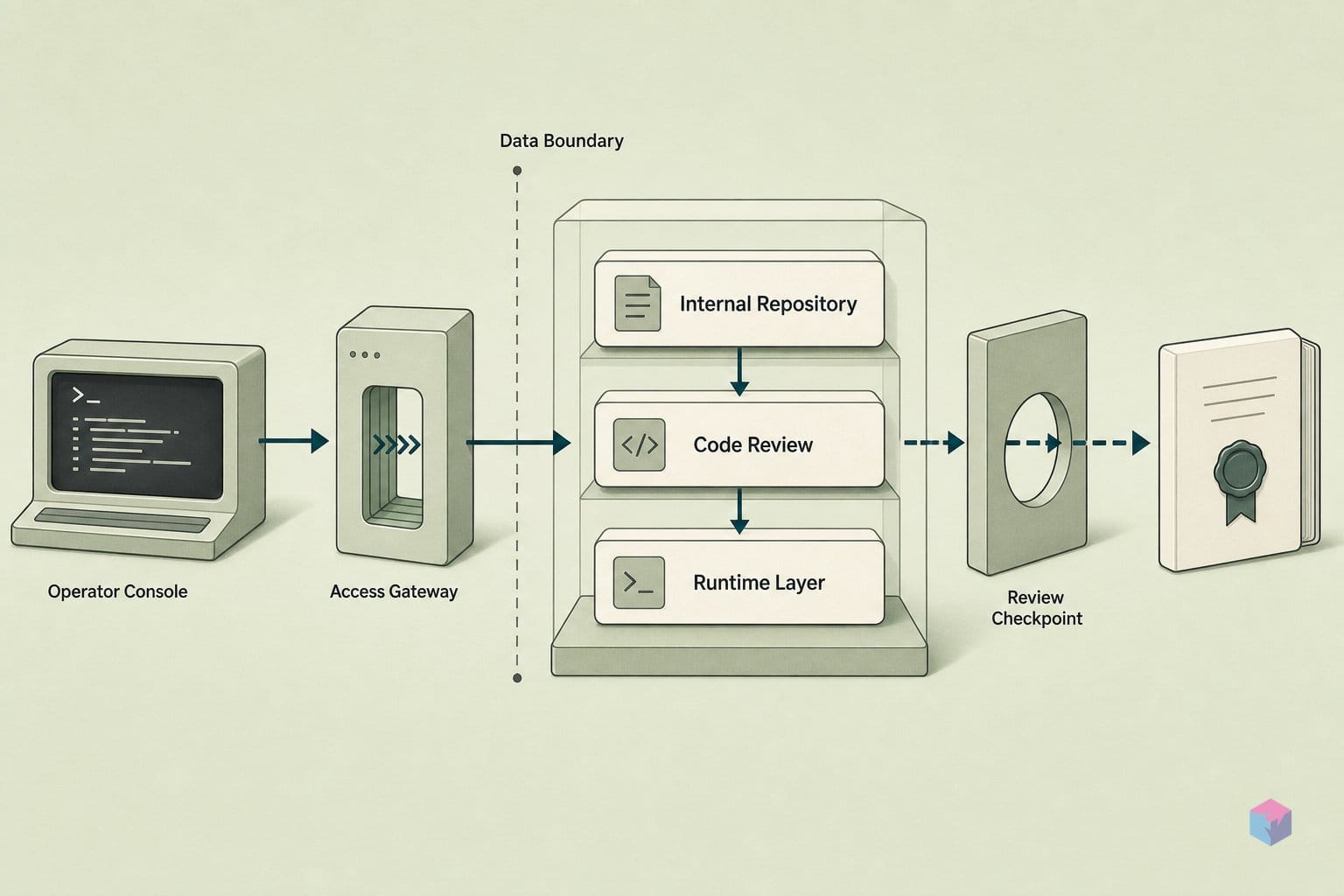
Codex가 리더로 선정된 배경에는 코드 생성 속도가 아닌 거버넌스 제어 기능이 있습니다. 가트너는 OS 수준 샌드박싱, 유연한 배포, 커스터마이즈 가능한 정책을 갖춘 역할 기반 접근 제어(RBAC), 감사 가능한 워크스페이스 거버넌스를 Codex의 강점으로 언급한 것으로 전해집니다 . 플랫폼 팀 입장에서 실질적 함의는 이렇습니다: 에이전트가 계획 수립, 편집, 테스트 실행, 풀 리퀘스트 생성을 자율적으로 수행할 수 있게 되면, 평가의 무게중심은 그 자율성을 얼마나 엄격하게 제어하고 감사할 수 있는지로 이동합니다.
배포 범위는 넓습니다. Codex는 데스크톱 및 웹 앱(macOS·Windows), IDE 확장, CLI, SDK 형태로 제공되며, 클라우드 기반 오케스트레이션과 Amazon Bedrock 배포도 지원합니다. OpenAI는 HIPAA 준수 사용 옵션도 제공한다고 밝히고 있습니다 . 엔터프라이즈 제어 기능으로는 승인 게이트, RBAC, 커스터마이즈 가능한 정책, Compliance API를 통해 감사 가능한 워크스페이스 거버넌스가 포함됩니다 . 이는 벤더가 직접 공개한 내용으로, OpenAI가 부각하기로 선택한 차별점이며 독립 감사 결과가 아닙니다.
주목할 구조적 세부사항은 승인 게이트입니다. Codex는 풀 리퀘스트 지향 작업을 자동 커밋하지 않고 인간 검토 단계로 올리도록 설계되어 있어, 사람 개입 핸드오프가 사후 고려사항이 아닌 평가 대상 기능으로 자리 잡습니다 . 에이전트가 diff를 준비하고 테스트를 실행한 뒤 변경 사항을 제안하면, 최종 병합은 사람이 수행합니다.
개발자들이 가장 자주 묻는 컴플라이언스 질문에 대해: OpenAI는 비즈니스·엔터프라이즈·Edu·API 플랜의 입출력 데이터는 기본적으로 모델 개선에 사용되지 않는다고 밝힙니다 — 소비자 티어 기본값은 다르므로 정확한 적용 범위를 확인해야 합니다 .
"Cisco는 Codex를 활용해 AI Defense 보안 플랫폼을 구축하여 개발 기간을 수개월에서 수주로 단축했습니다" — OpenAI, 선정 발표문 중 (source: OpenAI).
주간 활성 사용자 500만 명, 그 중 20%는 비엔지니어링 직군
Codex의 도달 범위는 OpenAI가 공식 기록으로 남긴 성장 지표 중 가장 명확한 신호이며, 그 궤적은 가파르다. 2026년 6월 2일 발표된 "Codex for every role, tool, and workflow"에서 OpenAI는 주간 사용자 수가 500만 명을 넘어섰다고 밝혔다 — 5월 20일 Gartner 인정 당시 언급된 400만 명 이상의 수치에서 증가한 것이다 . 약 2주 간격의 이 변화는 현재 공개된 가장 최신 채택 수치이며, 의도된 메시지로 읽힌다: Codex는 더 이상 개발자 전용 도구가 아니라는 것이다.
숫자보다 구성이 더 중요하다. OpenAI에 따르면 비개발자가 Codex 사용자의 약 20%를 차지하며, 이 집단은 개발자 세그먼트보다 3배 이상 빠르게 성장하고 있다 . Gartner의 "엔터프라이즈 AI 코딩 에이전트" 카테고리에 포지셔닝된 제품으로서는 주목할 만한 변화다 — 코드 작성과 전혀 무관한 워크플로우 쪽으로 에이전트가 끌려가고 있는 것이다.
6월 2일 확장은 이 수요를 흡수하도록 설계됐다. 데이터 분석, 크리에이티브 제작, 영업, 제품 디자인, 상장 주식 투자, 투자 은행 등 직무별 플러그인 6가지가 새롭게 도입됐으며, 62개 앱과 110개 스킬이 번들로 제공된다 . 이와 함께 OpenAI는 Business 및 Enterprise 고객을 위한 Sites 미리보기를 출시해 Codex가 워크스페이스 내부 앱과 웹사이트를 생성하고 호스팅할 수 있게 했다. 공식 에코시스템 파트너로는 Vercel, Wix, Figma, Replit, Lovable이 명시됐다 .
Codex를 평가하는 개발자 입장에서 시사점은 두 가지다: 엔지니어링에 표준화한 거버넌스 체계가 이제 내부 도구를 구축하는 재무 분석가와 영업 팀에까지 확장된다 — 이는 앞서 다룬 RBAC 및 감사 통제의 중요성을 낮추는 게 아니라 오히려 높인다.
9가지 태스크 유형별 PR 수락률: 압도적인 단일 도구는 없다

모든 태스크 카테고리를 지배하는 단일 코딩 에이전트는 존재하지 않는다 — 표준화하는 리더보드 순위가 실제 작업 큐와 맞지 않을 수 있다. 2026년 2월 arXiv 연구는 OpenAI Codex, GitHub Copilot, Devin, Cursor, Claude Code를 대상으로 7,156개의 풀 리퀘스트를 분석했으며, 9가지 태스크 카테고리 전반에서 Codex의 수락률이 59.6%에서 88.6% 범위에 분포한다고 보고했다 . 동일 분석에서 9가지 모두를 선도하는 에이전트는 없었다: Claude Code가 문서화 및 기능 태스크를 선도했고, Cursor가 수정 태스크를 선도했다 .
이 편차가 중요한 이유는 수락률이 태스크 조건에 따라 달라지는 값이지 전체 점수가 아니기 때문이다. 수정 태스크에서 선두인 에이전트가 문서화에서는 뒤처질 수 있고, 그 반대도 마찬가지다. 연구 자체의 결론 — 리더십이 카테고리별로 순환한다 — 은 특정 벤더의 Gartner 포지션이 도구 선택을 확정지어준다는 생각을 약화시킨다.
| 태스크 유형 | 보고된 카테고리 리더 | 근거 신호 |
|---|---|---|
| 문서화 | Claude Code | 해당 카테고리 최고 수락률 |
| 기능 작업 | Claude Code | 해당 카테고리 최고 수락률 |
| 수정 작업 | Cursor | 해당 카테고리 최고 수락률 |
| 기타 여러 카테고리 | OpenAI Codex | 59.6%–88.6% 수락률 구간 내 |
규모가 이 발견에 무게를 더한다. 관련 AIDev 데이터셋 논문은 116,211개 리포지토리와 72,189명의 개발자에 걸쳐 동일한 5개 에이전트를 대상으로 한 932,791개의 에이전트 작성 풀 리퀘스트를 보고했다 — 현재 기준으로 공개된 가장 큰 크로스 에이전트 PR 코퍼스다 . 이는 벤더 벤치마크가 아닌 실제 리포지토리의 관찰 데이터로, Gartner 인정에 수반된 마케팅성 역량 주장의 유용한 반증 자료가 된다.
엔지니어링 팀에 대한 실질적 시사점은 구체적이다: 작업 큐의 태스크 카테고리 구성이 전체 리더보드 순위보다 중요하다. 주로 버그 수정을 출시하는 팀과 그린필드 기능을 작성하거나 문서를 마이그레이션하는 팀의 가중치는 다르다. 작업량이 충분하다면, 수정·기능·문서를 각 카테고리 선두 에이전트로 라우팅하는 폴리글롯 설정이 단일 벤더 표준화를 능가할 수 있다 — 단, 거버넌스 체계(앞서 다룬 RBAC 및 승인 게이트)가 감사 추적을 단편화하지 않고 복수의 에이전트에 걸쳐 작동해야 한다.
자동완성보다 거버넌스가 우선일 때, 벤더 고르기
단일 에이전트를 표준화할 때는 원시 PR 수락률보다 거버넌스 체계 — 샌드박싱, RBAC, 승인 게이트, 감사 가능성 — 를 우선시하라. Gartner의 "AI 코드 어시스턴트"에서 "엔터프라이즈 AI 코딩 에이전트"로의 명칭 변경이 바로 그 신호다: 이제 기관의 기준은 에이전트의 자동완성이 얼마나 자주 수락되느냐가 아니라, 통제 하에 다단계 작업을 위임받을 수 있느냐다. 수락률 퍼센티지는 누가 코드를 잘 짜는지 알려주고, 거버넌스는 실제로 배포할 수 있는지 알려준다.
배포 방식은 최종 후보군이 가장 크게 갈리는 지점이다. HIPAA나 FedRAMP 제약을 고려하는 규제 환경에서는 세 Leader가 의미 있게 다른 답을 제시한다: Codex는 HIPAA 준수 사용 옵션과 Amazon Bedrock을 통한 배포를 제공하며 , Tabnine은 온프레미스 및 에어갭 설치를 겨냥하고, GitLab은 셀프 호스팅 통제에 의존한다. 기능을 비교하기 전에 포지셔닝을 컴플라이언스 경계에 맞추라.
컴플라이언스 제약이 느슨하고 개발자 경험이 우선이라면, Cursor의 모델 불가지론적 접근과 Windsurf의 강한 비전 완성도 포지셔닝을 평가할 가치가 있다 . 특정 공급자에 고착되지 않은 팀에게는 모델 라우팅의 유연성이 더 중요하다.
주목할 만한 조달 변화가 있다: 비개발자가 이제 Codex 사용자의 약 20%를 차지하고 직무별 플러그인이 영업, 재무, 제품 분야에 닿으면서, 평가는 더 이상 엔지니어링만의 영역이 아니다. IT 및 조달 담당자가 공동 평가자가 된다.
구체적인 시사점: 컴플라이언스 경계에서 안쪽으로 최종 후보 목록을 작성하라 — 포지셔닝 먼저, 거버넌스 두 번째, 벤치마크 세 번째 — 그리고 계약 체결 전에 조달 팀을 같은 자리에 불러라.
자주 묻는 질문
OpenAI는 실제로 엔터프라이즈 AI 코딩 에이전트 Gartner Magic Quadrant의 리더로 선정되었나요?
네, OpenAI의 공식 발표와 후속 기술 언론 보도에 따르면 그렇습니다 — 다만 Gartner 라이선스 없이는 독립적으로 확인할 수 없습니다. OpenAI는 Codex와 연계된 형태로, 2026년 5월 20일 발행된 최초의 엔터프라이즈 AI 코딩 에이전트 Gartner Magic Quadrant에서 리더로 선정되었다고 밝혔습니다. 단, 실제 Gartner 그래픽은 클라이언트 전용 유료 콘텐츠입니다. 공개된 초록은 여전히 "AI 코드 어시스턴트 Magic Quadrant"라는 제목이며, 14개 벤더 — Alibaba Cloud, Amazon, Anysphere(Cursor), Augment Code, Cognition(Windsurf), GitHub, GitLab, Google Cloud, Harness, IBM, JetBrains, Qodo, Tabnine, Tencent Cloud — 를 열거하며 OpenAI는 포함되어 있지 않습니다. 가장 합리적인 해석은 이 초록이 유료 업데이트 이전 버전이라는 것이며, OpenAI의 위치는 라이선스 보고서에만 존재합니다. 따라서 리더 주장은 비벤더 1차 텍스트가 아닌 벤더 게시물에 근거합니다.
Gartner가 쿼드런트 명칭을 "AI 코드 어시스턴트"에서 "엔터프라이즈 AI 코딩 에이전트"로 바꾸면서 무엇이 달라졌나요?
명칭 변경은 평가 범위를 재정의합니다. 이전 기준("AI 코드 어시스턴트", Gartner 문서 6948266)은 에디터 내 자동완성 및 단일 라인·블록 완성에 초점을 맞췄습니다. 2026년 판(문서 7879277)은 도구가 자율적으로 계획 수립, 구현, 테스트 실행, 디버깅, 코드 리뷰, 인간 승인을 위한 PR 준비까지 수행할 수 있는지로 기준을 높였습니다 . 벤더 평가 측면에서는 위임과 연결된 거버넌스 기능 — 샌드박싱, 승인 게이트, 역할 기반 접근 제어(RBAC), 감사 가능성 — 이 선택 사항에서 결정적 요소로 격상됩니다. 인라인 제안이 아닌 멀티스텝 엔지니어링 작업을 에이전트에 위임하는 시대이기 때문입니다.
2026년 보고서에서 실행 능력과 비전 완성도 측면의 선두 벤더는 어디인가요?
2차 보도에 따르면, GitHub Copilot이 실행 능력(Ability to Execute)에서 최고 순위를 기록했습니다 — 가장 넓은 설치 기반과 폭넓은 엔터프라이즈 침투율을 반영한 결과입니다. 비전 완성도(Completeness of Vision)에서는 Cursor(Anysphere)가 빠른 성장세, 모델 독립성, 아키텍처 유연성을 근거로 가장 강한 위치를 점했습니다 . OpenAI Codex 역시 리더로 선정되었으며, Tabnine은 비전가(Visionary)로 분류되었습니다. 단, 이는 2차 출처의 인용임을 유의하십시오. Gartner는 두 가지 표준 축으로 평가하지만, 기본 그래픽, 기준 가중치, 정확한 위치는 유료 콘텐츠로 비벤더 출처에서는 확인 불가합니다.
엔터프라이즈 AI 코딩 에이전트를 표준으로 도입할 때 엔지니어링 리더가 평가해야 할 거버넌스 기능은 무엇인가요?
컴플라이언스 경계를 기준으로 체크리스트를 구성하십시오: OS 수준 샌드박싱 세분성, RBAC 범위 및 커스터마이징 가능성, 승인 게이트 설정, 컴플라이언스 API를 통한 감사 가능성. 특히 입력 데이터가 모델 학습에 사용되는지 반드시 확인하십시오 — OpenAI는 Business, Enterprise, Edu 및 API의 입력·출력이 기본적으로 모델 개선에 사용되지 않는다고 명시합니다 . 규제 산업의 경우 HIPAA 준수 옵션과 Amazon Bedrock을 통한 사용 가능성이 실질적인 차별화 요소입니다 . Codex는 승인 게이트, RBAC, 커스터마이징 가능한 정책, 감사 가능한 워크스페이스 거버넌스를 제공하며, 컴플라이언스 API를 통해 사용할 수 있습니다.
OpenAI Codex는 소프트웨어 개발자만을 위한 도구인가요?
아닙니다. 그리고 그 구성 비율은 빠르게 변화하고 있습니다. 2026년 6월 2일 기준, OpenAI는 주간 Codex 사용자가 500만 명을 넘어섰으며 그 중 약 20%가 비개발자이고, 비개발자 사용량이 개발자 세그먼트보다 3배 이상 빠르게 증가하고 있다고 밝혔습니다 . 같은 발표에서는 역할별 6개 플러그인도 소개되었습니다 — 데이터 분석, 크리에이티브 프로덕션, 영업, 제품 디자인, 공개 주식 투자, 투자 은행 분야를 아우르며, 62개 앱과 110개 스킬을 포함하고 내부 앱 호스팅을 위한 Sites 미리보기도 제공합니다. 코드 작성 없이도 내부 대시보드와 자동화 워크플로우가 필요한 지식 근로자를 타깃으로 합니다.








