
Google DeepMind의 오픈 웨이트 패밀리에 이번 달 새로운 중간 모델이 추가됐습니다. 주목할 점은 파라미터 수가 아니라, 아키텍처에서 빠진 것입니다.
Gemma 4 12B의 인코더 없는 통합 체크포인트 한눈에
Gemma 4 12B는 Google DeepMind가 2026년 6월 3일 허용적인 Apache 2.0 라이선스로 출시한 인코더 없는 통합 멀티모달 모델입니다. 48개 레이어에 걸쳐 119.5억 개의 파라미터를 탑재하며 컨텍스트 윈도우는 256K 토큰으로, 4B급 엣지 모델과 먼저 출시된 26B A4B 및 31B 혼합 전문가(MoE) 모델 사이에 위치합니다.
가장 큰 변화는 별도로 덧붙인 구성 요소가 없다는 점입니다. 전용 비전·오디오 타워 대신, 원시 입력이 LLM 임베딩 공간으로 직접 투영됩니다. 비전은 48×48 패치를 처리하는 약 3,500만 파라미터 임베딩 모듈을 거치고, 16 kHz 오디오는 640개 부동소수점으로 구성된 40 ms 프레임으로 슬라이싱됩니다 — 별도의 컨포머 오디오 인코더는 없습니다. 덕분에 네이티브 오디오 입력을 지원하는 첫 중간 규모 Gemma 모델이 됐습니다.
- 입력: 텍스트, 이미지(70/140/280/560/1120 토큰 예산 설정 가능), 최대 30초 오디오, 약 1fps로 최대 60초 동영상; 출력은 텍스트 전용 .
- 어텐션: 로컬 슬라이딩 윈도우(1,024 토큰)와 글로벌 어텐션을 인터리빙하는 하이브리드 레이아웃, 온디바이스 효율을 위한 Proportional RoPE 및 Per-Layer Embeddings 적용 .
- 지식 컷오프: 사전학습 데이터는 2025년 1월까지로, 사실 관련 답변이 오래됐을 수 있어 도구 보강이 필요합니다.
다운로드 전 확인할 RAM·VRAM·의존성 요구사항
웨이트를 내려받기 전에 실행할 양자화 수준에 맞게 하드웨어를 확인하세요. 사용 가능한 메모리가 디스크의 양자화 파일 크기를 초과해야 로드 시 프로세스가 종료되지 않습니다. Unsloth에 따르면 12B 모델은 4비트 기준 약 7~8 GB, 8비트 기준 약 13~14 GB가 필요하며, 전체 FP16 인스트럭션 튜닝 체크포인트는 약 24 GB에 달합니다 . 흔히 인용되는 "16 GB 노트북에서 실행 가능"이라는 수치는 Apple Silicon 통합 메모리나 개별 GPU에서 적당한 컨텍스트 길이로 양자화 IT 체크포인트를 실행할 때를 기준으로 한 것입니다 — 대용량 배치로 256K 컨텍스트를 사용하면 이를 훨씬 초과합니다 .
| 양자화 | 대략적인 메모리 | 비고 |
|---|---|---|
| UD-Q4_K_XL (동적 4비트) | ~7–8 GB | 권장; 16 GB에 최적 |
| Q8_0 | ~13–14 GB | 높은 정밀도, 여유 공간 적음 |
| FP16 IT 체크포인트 | ~24 GB | 대형 GPU 또는 분산 실행 필요 |
Transformers 경로를 이용하려면 Python 3.9 이상과 pip install transformers torch accelerate가 필요하며, 이미지·오디오·동영상 입력을 원한다면 torchvision librosa도 설치해야 합니다 . 처음 사용 시 반드시 거쳐야 할 단계가 있습니다. google/gemma-4-12B-it는 게이티드 저장소이므로 Hugging Face 또는 Kaggle에 로그인한 상태에서 Google 이용 약관에 동의해야 하며, 그렇지 않으면 다운로드가 바로 실패합니다 .
Gemma 4 12B 로컬 실행: Ollama, Transformers, llama.cpp 한눈에
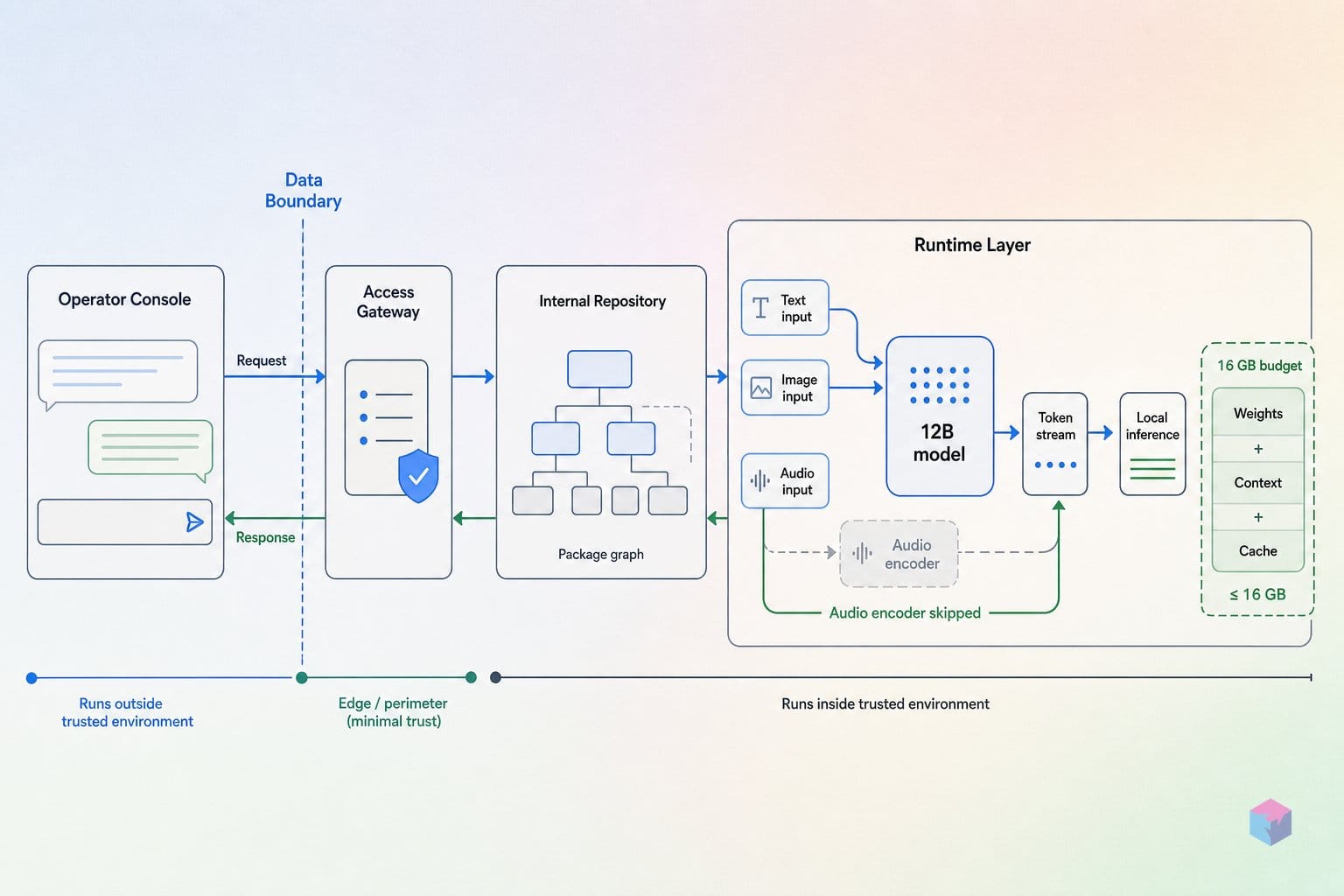
라이선스에 동의했다면, 네 가지 실행 환경이 거의 모든 로컬 설정을 커버하며 각각 한두 개의 명령으로 사용 가능한 엔드포인트를 띄울 수 있습니다. Ollama는 채팅 서버를 가장 빠르게 구성하는 경로이고, Transformers는 Python에서 완전한 멀티모달 제어를 제공하며, Unsloth GGUF를 통한 llama.cpp는 메모리를 가장 적게 씁니다. LiteRT-LM은 Linux, macOS, Windows, Raspberry Pi에서 OpenAI 호환 API를 노출합니다. 모든 환경에서 인스트럭션 튜닝된 google/gemma-4-12B-it 체크포인트를 사용하세요 — 베이스 모델은 채팅 및 멀티모달 용도에 적합하지 않습니다.
Ollama. ollama run gemma4:12b를 실행하면 Q4 태그를 내려받습니다 — 용량은 7.6 GB이며 256K 컨텍스트 윈도우를 지원합니다 — 그리고 OpenAI 호환 채팅 엔드포인트가 시작됩니다. Ollama 라이브러리는 이 태그에 텍스트와 이미지 입력을 지원한다고 명시합니다 . 오디오 입력은 Transformers/HF 경로에서만 공식 지원되므로, 이를 기반으로 무언가를 만들기 전에 설치된 Ollama 버전에서 직접 확인하세요 .
HuggingFace Transformers. AutoModelForMultimodalLM.from_pretrained('google/gemma-4-12B-it', dtype='auto', device_map='auto')로 로드합니다. 표준 system/user/assistant 역할로 messages를 구성하세요 — Gemma 4는 기존 Gemma 턴 형식을 폐기했습니다 . processor.apply_chat_template(..., add_generation_prompt=True, enable_thinking=False)를 호출하고, model.generate를 실행하여 새로 생성된 토큰만 디코딩한 뒤 processor.parse_response(...)로 마무리합니다 .
llama.cpp (Unsloth GGUF). 동적 4비트 양자화가 권장 기본값입니다:
export LLAMA_CACHE="unsloth/gemma-4-12B-it-GGUF"
./llama.cpp/llama-cli -hf unsloth/gemma-4-12b-it-GGUF:UD-Q4_K_XL \
--temp 1.0 --top-p 0.95 --top-k 64이 명령은 IT GGUF를 내려받고 모델 카드에서 권장하는 샘플링 설정으로 실행합니다 .
LiteRT-LM은 채팅, 멀티모달 첨부 파일, 함수 호출, 상태 비저장 프리픽스 캐싱을 갖춘 로컬 OpenAI 호환 API를 구축하는 가장 깔끔한 방법입니다:
litert-lm import --from-huggingface-repo=litert-community/gemma-4-12B-it-litert-lm \
gemma-4-12B-it.litertlm gemma4-12b
litert-lm serve"LM Studio, Ollama, AI Edge Gallery, LiteRT-LM CLI 등에서 클릭 몇 번으로 Gemma 4 12B를 바로 사용해볼 수 있습니다" — Google DeepMind, Gemma 4 12B 개발자 가이드 (source: developers.googleblog.com).
권장 샘플링 값은 모든 백엔드에서 동일합니다: temperature=1.0, top_p=0.95, top_k=64 . 이는 모델 카드 값입니다 — 명확한 평가 기준 없이 조정하지 마세요. "설정을 바꿨더니 모델이 나빠졌다"는 문제의 흔한 원인이 바로 이 값의 변경입니다.
16GB는 보장이 아니며, 오디오 지원은 환경마다 다르고, 수치는 자체 보고 기준입니다

16GB 목표치는 적당한 컨텍스트 길이에서 4비트 인스트럭션 튜닝 체크포인트를 실행하기 위한 최솟값이지, 모든 워크로드의 상한선이 아닙니다. Unsloth에 따르면 양자화 가중치는 4비트 기준 약 7~8 GB, 8비트 기준 13~14 GB이며, 여유 메모리가 파일 크기를 초과해야 한다고 권고합니다 . 256K 컨텍스트 전체를 사용하거나 배치 크기를 늘리거나 BF16 가중치를 로드하면 16GB를 금세 초과합니다. Google이 제시한 1GB 모바일 풋프린트는 E2B 수치로만 참고하세요 — 12B 모델에는 적용되지 않습니다 .
오디오 입력은 Transformers/HF 경로의 스펙으로 명시되어 있지만, 출시 시점에는 Ollama나 llama.cpp GGUF 실행 환경에서 일관되게 지원되지 않습니다 — 일부 GGUF 경로에서는 이미지 입력조차 과거에 실패한 사례가 있으므로, 사용 중인 런타임에서 멀티모달 지원을 직접 확인하세요 . 오디오 의존 기능을 구현하기 전에 선택한 런타임에서 간단한 오디오 입력 테스트를 먼저 실행해보세요.
주요 수치 — AIME 2026 77.5%, LiveCodeBench v6 72.0%, GPQA Diamond 78.8% — 는 모두 2026년 6월 기준 Google 모델 카드 결과이며, 서드파티 리더보드 등재는 아직 적습니다 . 모델 카드에는 12B가 AIME 2026에서 Gemma 3 27B(no-think)를 앞선다고 나와 있습니다 (77.5% vs 20.8%), LiveCodeBench v6에서도 마찬가지입니다 (72.0% vs 29.1%) — 독립적인 재현을 통과한다면 의미 있는 차이입니다. InfoQ는 커뮤니티 반응이 엇갈린다고 보도했습니다: "단순 코딩과 버그 수정에는 강하지만 모호하고 복잡한 추론 문제에서는 의문스럽다"는 평가이며, Qwen 같은 특화 모델을 대체할 위치는 아니라고 합니다 — InfoQ, 2026년 6월 (source: InfoQ). Open LLM Leaderboard에 새 등재가 생기면 주시하세요.
LoRA 파인튜닝과 MTP 드래프터 가속
인코더 없는 설계는 파인튜닝도 단순하게 만듭니다. 텍스트·이미지·오디오를 하나의 가중치 세트로 처리하므로, LoRA 어댑터 하나로 전체 멀티모달 루프를 한 번에 업데이트할 수 있습니다 — 별도의 인코더 가중치를 맞출 필요가 없어, 모달리티별로 엮인 어댑터 스택 대신 어댑터 하나만 관리하면 됩니다 . Unsloth는 전체 파라미터 학습 대비 약 2배 빠른 파인튜닝과 약 70% 적은 VRAM을 광고하며 , 현실적인 목표치는 16–24 GB이지만 절감 효과를 당연시하기 전에 자신의 태스크에서 기본 HF Trainer 실행과 비교 측정해 보세요.
추론 처리량 측면에서 12B는 MTP(Multi-Token Prediction) 드래프터를 탑재하며 드래프터 지원 모델로 등재되어 있습니다. Google은 추론 품질 저하 없이 최대 3배의 디코딩 속도 향상을 보고합니다 — 레이턴시가 중요할 때는 LiteRT-LM 또는 vLLM에서 활성화하세요. 모델은 MLX 및 SGLang과도 호환되며, Google은 프로덕션 규모 서빙을 위해 Cloud Run과 GKE를 제시하고 있습니다 .
핵심 요약: 체크포인트 하나, 어댑터 하나, OpenAI 호환 서버 하나. 16 GB에서 UD-Q4_K_XL 양자화로 시작하고, 런타임에서 오디오가 실제로 지원되는지 확인한 뒤, 자신의 워크로드에서 기준값을 측정한 후에야 MTP와 단일 LoRA 패스를 추가하세요.
자주 묻는 질문
Ollama에서 Gemma 4 12B가 오디오 입력을 지원하나요?
출시 시점에는 안정적으로 지원되지 않습니다. 오디오는 Gemma 4 12B의 공식 멀티모달 스펙에 포함됩니다 — 텍스트, 이미지, 최대 30초 오디오, 최대 60초 비디오 — 하지만 Ollama의 gemma4:12b 태그(7.6 GB, 256K 컨텍스트)는 텍스트와 이미지 입력만 나열합니다 . 이미지 입력 역시 일부 Ollama 및 HF GGUF 경로에서는 지원되지 않는 경우가 있었습니다 . 개발에 활용하기 전, 설치된 Ollama 버전에서 짧은 오디오 입력 테스트를 먼저 실행해 보세요.
Gemma 4 12B 실행에 실제로 필요한 RAM은 얼마인가요?
4비트 GGUF(UD-Q4_K_XL)에서 약 7–8 GB, 8비트에서는 약 13–14 GB이며, 여유 메모리는 양자화된 파일 크기를 초과해야 합니다 . 16 GB라는 수치는 Apple Silicon 통합 메모리 또는 개별 GPU에서 적당한 컨텍스트 길이로 instruction-tuned 체크포인트를 실행하는 기준입니다 . 최대 256K에 가까운 긴 컨텍스트나 더 큰 배치 크기는 16 GB를 초과합니다.
소비자용 GPU 하나로 Gemma 4 12B를 파인튜닝할 수 있나요?
네, Unsloth LoRA를 통해 가능합니다. 하나의 가중치 세트가 모든 모달리티를 처리하므로, LoRA 어댑터 하나로 전체 멀티모달 루프를 한 번에 업데이트할 수 있습니다 — 별도로 학습해야 할 비전이나 오디오 인코더가 없습니다 . Unsloth는 전체 파라미터 학습 대비 약 2배 빠른 파인튜닝과 약 70% 적은 VRAM을 광고합니다 . 현실적인 목표치는 VRAM 16–24 GB입니다.
Gemma 4 12B에서 thinking 모드를 활성화하는 방법은?
apply_chat_template에 enable_thinking=True를 전달하거나, 시스템 프롬프트 앞에 <|think|> 제어 토큰을 추가하세요 . 멀티턴 대화 기록에 이전의 숨겨진 thinking 블록을 저장하지 마세요 — 모델 카드에서 이를 잘못된 사용법으로 명시하고 있습니다 . 백엔드 전반에 걸쳐 권장 샘플링 설정은 temperature 1.0, top_p 0.95, top_k 64입니다.
Gemma 4 12B의 벤치마크 수치는 독립적으로 검증되었나요?
2026년 6월 기준으로는 아닙니다. MMLU-Pro 77.2%, AIME 2026 77.5%, LiveCodeBench v6 72.0% 등 주요 수치는 모두 Google 자체 모델 카드에서 나온 것으로, 이 시점에서 제3자 재현은 아직 드뭅니다 . 커뮤니티 반응은 간단한 코딩 및 버그 수정에서는 긍정적이지만, 모호하고 복잡한 추론 문제에서는 엇갈립니다 . 제3자 항목이 등장하는 대로 독립적인 리더보드를 확인하세요.