
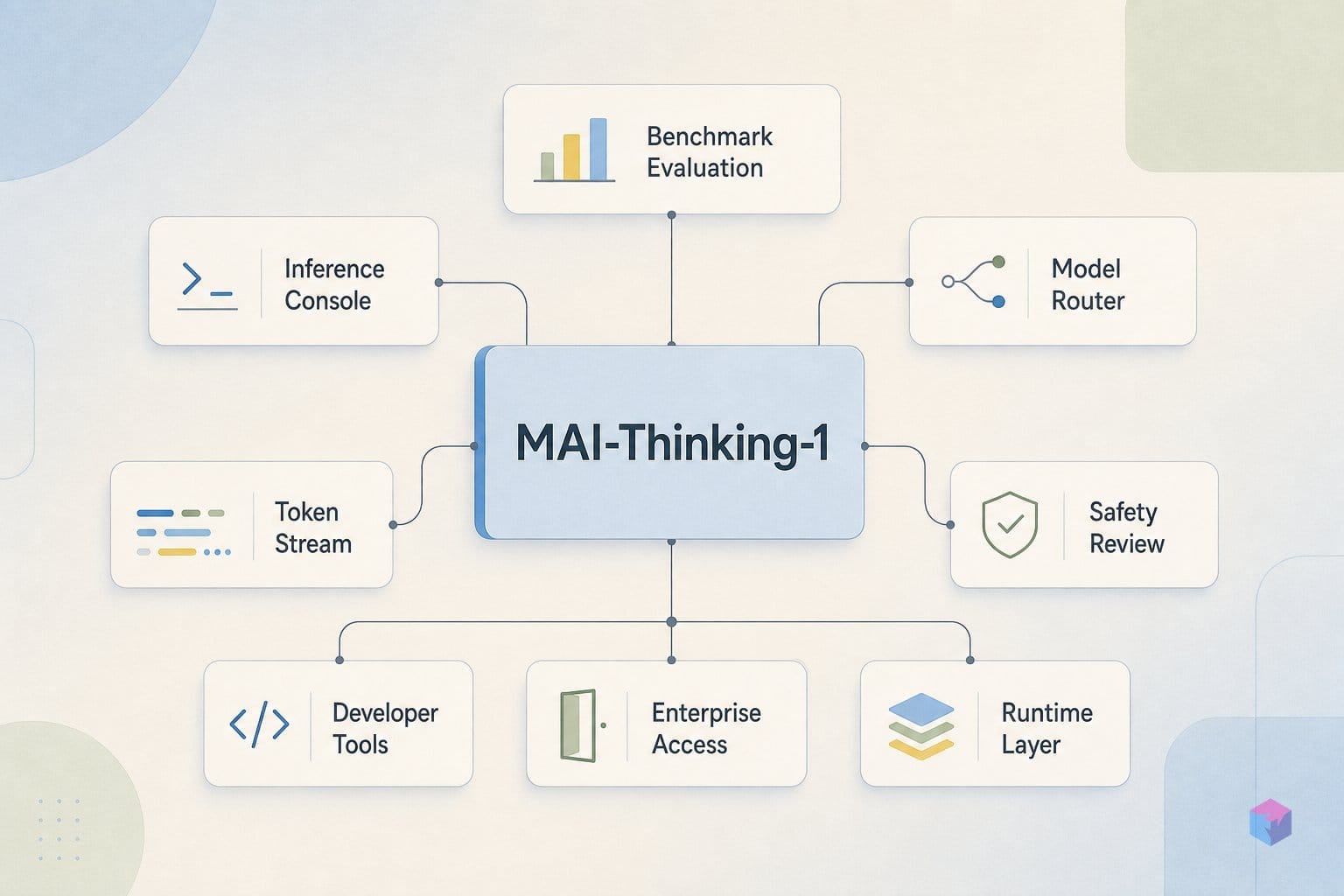
MAI-Thinking-1: Build 2026의 중심에 선 희소 MoE
MAI-Thinking-1은 Microsoft가 자체 개발한 첫 번째 플래그십 추론 모델로, 활성 파라미터 약 350억 개와 총 약 1조 개의 파라미터를 갖춘 중형 희소 Mixture-of-Experts 디코더입니다. Microsoft 운영 Azure 인프라에서 처음부터 학습되었으며 , 6월 2일 기조연설의 핵심을 장식했습니다. 이날 단 하나가 아닌 총 7개의 모델이 공개되었고, 이는 Microsoft AI(MAI) 팀이 파트너사의 모델을 래핑하는 방식에서 벗어나 자체 스택으로 멀티모달 경쟁에 직접 나서겠다는 신호입니다 .
요약: Build 2026(6월 2~3일)에서 Microsoft는 자체 개발 첫 플래그십 추론 모델인 MAI-Thinking-1을 공개했습니다. 활성 파라미터 약 350억 개, 총 약 1조 개의 파라미터를 갖춘 희소 Mixture-of-Experts 디코더입니다. Microsoft가 발표한 SWE-Bench Pro 점수는 52.8%로, Anthropic의 Claude Opus 4.6과 동급으로 제시됩니다. 현재 Microsoft Foundry에서 비공개 프리뷰 중입니다.
6월 2~3일 Microsoft AI에서 자체 개발해 발표한 7개의 모델은 추론, 코딩, 이미지, 전사, 음성 등 다양한 영역을 아우릅니다 :
- MAI-Thinking-1 — 플래그십 추론 모델
- MAI-Code-1-Flash — GitHub Copilot을 겨냥한 에이전틱 코딩 모델
- MAI-Image-2.5 및 MAI-Image-2.5-Flash — 텍스트-이미지 변환 및 이미지 편집
- MAI-Transcribe-1.5 — 43개 언어 음성-텍스트 변환
- MAI-Voice-2 및 MAI-Voice-2-Flash(후자는 출시 예정) — 텍스트-음성 변환
전략적 의도는 명확했습니다. Microsoft는 이 모델들을 "처음부터 학습된" 모델로 표현하며, 장기적인 자립성을 확보하고 외부 공급업체, 특히 OpenAI에 대한 의존도를 줄이겠다는 방향을 분명히 했습니다. 아울러 MAI를 소비자용 Copilot 레이어가 아닌 Microsoft Foundry 내 기업 지향 자체 멀티모달 스택으로 자리매김하려는 전략입니다 .
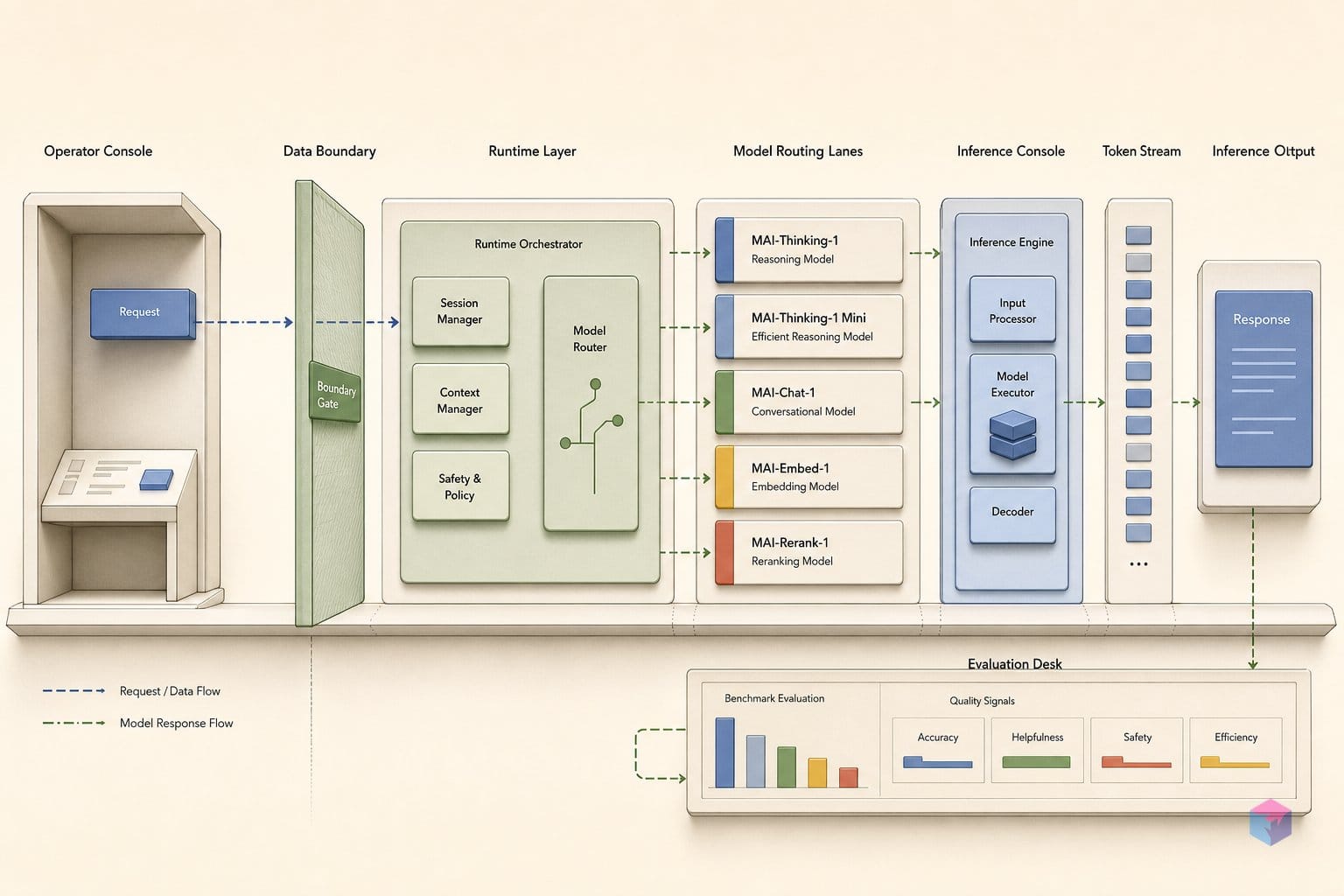
현재 접근은 제한적입니다. MAI-Thinking-1은 Microsoft Foundry에서 비공개 프리뷰 중이며, 공개 MAI Playground 프리뷰도 곧 제공될 예정이라고 밝혔습니다. OpenRouter, Fireworks AI, Baseten을 통한 배포도 예정되어 있습니다 . 이어지는 섹션에서는 아키텍처, 데이터 계보 선택, 그리고 Microsoft의 자체 벤치마크 수치를 어느 정도로 신뢰해야 하는지를 상세히 살펴봅니다.
78개 레이어, 512개 전문가, GB200 GPU 8,000개: MAI-Base-1 사양 한눈에
MAI-Base-1은 MAI-Thinking-1의 기반 모델입니다. 밀집 블록과 Mixture-of-Experts 피드포워드 블록이 교차 배치된 디코더 전용 Transformer로, 78개 레이어에 토큰당 512개 전문가 중 8개를 활성화하는 라우팅 구조를 갖습니다 . 기본 구성에서 활성 파라미터는 약 347억 개, 총 파라미터는 약 9,620억 개로, 희소 설계 특성상 임의의 토큰에 대해 네트워크의 일부만 실행됩니다 . 이 위에 구축된 추론 모델 MAI-Thinking-1은 활성 파라미터 약 350억 개, 총 약 1조 개의 파라미터에 256K 토큰 컨텍스트 창을 제공합니다 .
Microsoft에 따르면, 이 모델은 Microsoft 운영 Azure 클러스터에서 NVIDIA GB200 GPU 8,000개를 활용해 처음부터 사전 학습되었으며, 30조 개의 사전 학습 토큰과 3.55조 개의 중간 학습 토큰을 사용했습니다 . 특히 학습 데이터에는 합성 언어 모델 생성 콘텐츠를 배제하고 공개 가용 및 라이선스 취득 인간 저작 소스만 포함했는데, 이 선택에 대해서는 다음 섹션에서 자세히 살펴봅니다 .
| 사양 | MAI-Base-1 (기본) | MAI-Thinking-1 (추론) |
|---|---|---|
| 아키텍처 | 디코더 전용 Transformer, 밀집 + MoE 블록 | 희소 MoE |
| 레이어 | 78 | — |
| 전문가 라우팅 | 토큰당 512개 중 8개 | 토큰당 512개 중 8개 |
| 활성 파라미터 | ~34.7B | ~35B |
| 총 파라미터 | ~962B | ~1T |
| 컨텍스트 창 | — | 256K tokens |
| 학습 하드웨어 | 8,000 NVIDIA GB200 (Azure) | 기반 모델 상속 |
| 학습 토큰 | 30T 사전 학습 + 3.55T 중간 학습 | 기반 모델 상속 |
개발자 인터페이스 측면에서 MAI-Thinking-1은 함수 호출, 계층형 개발자 지시문, Chat Completions API를 지원하므로, 해당 스키마에 맞춰진 기존 도구를 최소한의 수정으로 연결할 수 있습니다 .
이 수치들을 확정적 사실로 받아들이기 전에 짚고 넘어갈 출처 관련 유의사항이 있습니다. Microsoft는 2026년 6월 2일 출시와 함께 전체 기술 보고서를 공개했지만, arXiv나 독립적인 동료 심사 매체에는 제출되지 않았습니다 . 일반적인 모델 카드보다 풍부한 상세 자체 공개 자료로 읽되, 벤더가 작성했고 외부 검증을 거치지 않았다는 점을 감안해야 합니다. 파라미터 수, 레이어 깊이, 전문가 구성은 모두 Microsoft 자체 집계로, 경쟁 모델 대비 규모 파악에는 유용하지만 제3자의 확인은 아직 이루어지지 않았습니다.
제로 증류와 클린 IP — 마이크로소프트가 이 트레이드오프를 선택한 이유
MAI-Base-1의 데이터 이면에는 단순한 기술적 주석이 아닌, 의도된 IP 출처 논거가 담겨 있습니다. 마이크로소프트는 웹 텍스트, 공개 GitHub 코드, 도서, 학술 논문, 뉴스, 다국어 코퍼스, 도메인 자료 등 공개 소스와 라이선스가 부여된 인간 생성 자료만으로 모델을 사전 학습했으며, 합성 데이터나 언어 모델이 생성한 콘텐츠는 명시적으로 제외했다고 밝혔습니다 . 이 "제로 증류" 입장은 다른 벤더의 시스템 출력물을 일절 계승하지 않는다는 의미이며, 바로 그 점을 마이크로소프트는 기업 고객에게 강조합니다.
학습 데이터 계보를 우려해 본 사람이라면 그 이유는 자명합니다. 경쟁사 모델에서 증류하면 해당 모델의 출력물에서 비롯된 저작권 노출 위험과 합성 파이프라인의 오염이 따라오는데, 이는 사후 감사가 어렵습니다. 문서화된 인간 소스에서 처음부터 학습함으로써 마이크로소프트는 가중치에 대한 더 명확한 관리 연속성을 주장할 수 있으며, 이는 규제가 엄격한 조달 환경에서 몇 가지 벤치마크 수치보다 훨씬 중요합니다 .
첫 번째로 명시된 적용 사례가 이 논리를 구체화합니다. Mayo Clinic과 함께 MAI 인프라 위에 구축한 의료 특화 모델이 그것으로, 데이터 계보의 명확성이 규제·법적 책임 리스크를 직접적으로 줄여주는 도메인입니다 . HIPAA식 심사가 적용되는 환경에서는 "이 모델의 지식은 어디서 왔는가"라는 질문에 조달 팀이 반드시 답해야 하며, "경쟁사의 합성 출력물이 없다"는 답변은 오늘날 대부분의 파운데이션 모델이 제시할 수 있는 것보다 훨씬 명확합니다.
마이크로소프트는 소유권 측면을 직설적으로 표현합니다. Build 기조연설에서 MAI 팀은 "RLE와 그 안에서 구축하는 모델이 여러분의 해자가 된다"고 주장했습니다 — 공유 인텔리전스를 빌리는 것이 아니라, 고객이 직접 파인튜닝해 행동을 소유한다는 것이 핵심 제안입니다 .
트레이드오프는 비용입니다. 합성 데이터를 배제하고 처음부터 학습하는 것은 증류보다 비쌉니다. 이것이 마이크로소프트가 자체 개발한 Maia 200 실리콘에 의존한 이유 중 하나이기도 하며, 범용 GPU 클러스터 대비 약 1.4배의 효율 향상을 주장합니다 . 이 효율성 주장은 일반 출시 가격이 확정될 경우 MAI-Thinking-1을 경쟁력 있는 가격에 제공할 수 있는 지렛대가 될 수 있습니다 — 아직 발표되지 않은 수치입니다.
SWE-Bench Pro 52.8% — 마이크로소프트의 수치, 외부 검증을 기다리며
현재까지 MAI-Thinking-1의 주요 벤치마크는 모두 중립적인 리더보드가 아닌 마이크로소프트 자체 평가 시스템에서 나온 것입니다. 보고된 점수는 SWE-Bench Pro 52.8%, AIME 2025 97.0%, AIME 2026 94.5%, LiveCodeBench v6 87.7%입니다 . 마이크로소프트는 SWE-Bench Pro 수치를 Anthropic의 Claude Opus 4.6과 동등한 수준으로 제시합니다 . 외부 검증이 나오기 전까지는 벤더 주장으로 간주하십시오.
| 벤치마크 | MAI-Thinking-1 (벤더 발표) | 출처 |
|---|---|---|
| SWE-Bench Pro | 52.8% | 마이크로소프트 평가 시스템 |
| AIME 2025 | 97.0% | 마이크로소프트 평가 시스템 |
| AIME 2026 | 94.5% | 마이크로소프트 평가 시스템 |
| LiveCodeBench v6 | 87.7% | 마이크로소프트 평가 시스템 |
마이크로소프트는 데이터 벤더 Surge를 통해 1,276개의 단일·다중 턴 작업을 아우르는 인간 선호도 연구도 진행했으며, 블라인드 평가자들이 나란히 비교 시 MAI-Thinking-1을 Claude Sonnet 4.6보다 선호했다고 밝혔습니다 . 블라인드·다중 턴·대규모 샘플이라는 방법론은 단일 정적 벤치마크보다 엄격합니다. 그러나 이 연구는 마이크로소프트가 의뢰하고 진행했으므로, 자동화된 점수와 마찬가지로 이해 충돌 문제를 안고 있습니다. 블라인드 프로토콜은 평가자 편향을 통제하지만, 작업을 선택한 주체가 누구인지는 통제하지 않습니다.
마이크로소프트의 공을 인정하자면, 이 수치에 과적합 방지 주장을 덧붙이고 있습니다:
"[이 점수들은] 특정 벤치마크를 의도적으로 겨냥하지 않고 달성되었습니다." — Microsoft AI, MAI 기조연설, Build 2026 (source: microsoft.ai)
이는 중요한 의미가 있습니다. 벤치마크 목표 학습은 SWE-Bench 및 AIME 수치를 부풀리는 잘 알려진 방법이기 때문입니다. 사실이라면, 모델이 실제 과제가 아닌 테스트에 맞춰 조정되었다는 우려 하나가 줄어듭니다. 그러나 이것이 독립적인 재현을 대체하지는 않으며, 벤더 수치를 신뢰할 수 있는 수치로 바꾸는 유일한 방법은 독립적인 재현뿐입니다.
그렇다면 외부 검증은 어떤 모습이어야 할까요? 추적할 가치가 있는 세 가지 신호가 있습니다. 첫째, LMSYS Chatbot Arena 제출 — 의뢰받은 패널이 아닌 공개 모집단에서 인간 선호도 Elo를 확인할 수 있습니다. 둘째, Artificial Analysis 평가 — 마이크로소프트는 이미 MAI-Transcribe-1.5의 단어 오류율 순위에 해당 플랫폼을 인용하고 있으므로 , 그 추론 인덱스가 여기서 자연스러운 교차 검증 수단이 됩니다. 셋째, 커뮤니티 주도 SWE-Bench Pro 제출 — 독립적인 평가 시스템이 52.8% 수치를 확인하거나 반박할 수 있습니다. 2026년 6월 7일 현재, 이러한 외부 데이터 포인트는 아직 발표되지 않았습니다 — 비공개 미리 보기 출시로 인해 모델을 실행할 수 있는 대상이 제한적입니다. 외부 검증이 나오기 전까지, MAI-Thinking-1의 점수는 '신뢰할 만하지만 미검증' 상태로 읽는 것이 솔직한 평가입니다.
저렴한 코딩 특화 모델: MAI-Code-1-Flash, GitHub Copilot에 합류
MAI-Code-1-Flash는 새 MAI 패밀리 중 오늘 정식 출시가 확인된 유일한 모델입니다. MAI-Thinking-1은 Foundry 비공개 프리뷰에서 초대 전용으로 머무르는 반면, 코딩 특화 형제 모델은 이미 GitHub Copilot 안에서 서비스 중입니다. 활성 파라미터 약 50억 개 규모의 에이전틱 코딩 모델로, Microsoft는 동일한 작업을 최대 60% 적은 토큰으로 처리한다고 밝혔습니다. 프런티어 추론 모델이 아닌, 경량·비용 효율 옵션으로 포지셔닝한 것입니다 . Copilot Free·Student·Pro·Pro+·Max 사용자 대상 VS Code 롤아웃은 2026년 6월 2일 시작되었으며, 제한된 인원부터 시작해 이후 수 주에 걸쳐 확대됩니다 .
벤치마크 비교 기준은 Anthropic의 플래그십이 아닌 소형 모델입니다. Microsoft 자체 프로덕션 환경에서 MAI-Code-1-Flash는 SWE-Bench Verified·SWE-Bench Pro·SWE-Bench Multilingual·Terminal Bench 2 모두에서 Claude Haiku 4.5를 앞섰으며, SWE-Bench Pro에서는 51.2% 대 35.2%를 기록했습니다. Microsoft의 186문항·34카테고리 적대적 추론 벤치마크에서는 조정 정확도 85.8%를 달성했습니다 . Microsoft는 한 가지 약점도 공개했습니다. 친숙하지만 틀린 풀이 경로에 저항하는 Einstellung 함정 정확도가 50% 미만이라는 것입니다 . 이는 벤더 자체 측정 수치이므로 "외부 검증 대기 중"이라는 단서가 동일하게 적용되지만, 공개된 실패 사례는 깔끔한 성적표보다 훨씬 유용한 신호입니다.
개발자가 지금 당장 활용할 수 있는 부분은 가격입니다. 포함 AI 크레딧 한도 초과 시, GitHub는 MAI-Code-1-Flash를 정식 출시·경량 모델로 분류하며 다음과 같은 100만 토큰당 요금을 공개했습니다 :
| 토큰 유형 | 100만 토큰당 가격 |
|---|---|
| 입력 | $0.75 |
| 캐시 입력 | $0.075 |
| 출력 | $4.50 |
60% 토큰 절감 효과와 결합하면, 작업당 실질 비용이 핵심 논거가 됩니다. 토큰을 적게 소비하는 소형 모델은 고정 단가에 곱해져 대용량 에이전틱 루프에서 체감 비용을 의미 있는 수준으로 낮춥니다. 현재로서는 Copilot 트래픽을 직접 라우팅하고 결과를 측정할 수 있는 유일한 MAI 모델입니다. Microsoft 자체 스택이 키노트 슬라이드 밖에서도 실력을 발휘하는지 검증하는 실질적인 출발점이 바로 여기에 있습니다.
이미지·음성·전사: 나머지 MAI 모델들
추론·코딩 모델 너머로, Microsoft는 이미지·음성·음성 인식 영역까지 MAI 스택을 확장하는 멀티모달 모델 4종을 출시했으며, 그 중 여럿은 프리뷰가 아닌 프로덕션 서비스에 이미 반영되어 있습니다. MAI-Image-2.5는 텍스트→이미지 생성과 이미지→이미지 편집을 모두 지원하며, Microsoft에 따르면 2026년 6월 기준 Arena 이미지 편집 리더보드 2위, 텍스트→이미지 부문 3위를 기록했습니다 . 같은 발표자료에서는 MAI-Image-2 대비 Arena 점수 전체 +75 상승을 주장하며, 대부분의 이미지 모델이 어려움을 겪는 텍스트 렌더링 부문에서만 +107을 달성했다고 밝혔습니다 .
가격은 공개되어 있으며, 이미지 생성을 대량으로 처리한다면 꼼꼼히 확인할 만합니다. MAI-Image-2.5는 텍스트 입력 100만 토큰당 $5, 이미지 입력 100만 토큰당 $8, 이미지 출력 100만 토큰당 $47이며, Flash 변형은 각각 $1.75·$1.75·$19.50으로 낮아집니다 . Microsoft Learn은 두 이미지 모델 모두 버전 2026-06-02 기준으로 West Central US·East US·West US·West Europe·Sweden Central·South India·UAE North의 Global Standard 배포를 지원하며, PNG 출력과 최대 1,048,576픽셀 출력 면적을 제공한다고 명시합니다 . 두 모델 모두 PowerPoint에 적용되었으며 OneDrive 롤아웃도 진행 중입니다 .
음성 인식 측면에서 MAI-Transcribe-1.5는 지원 언어를 25개에서 43개로 확대하고, FLEURS 단어 오류율 최고 수준을 주장하며 Artificial Analysis에서 WER 2.4%로 3위를 기록했다고 밝혔습니다 . 도메인 용어를 위한 키워드·콘텐츠 바이어싱을 추가해 FLEURS WER을 최대 30% 줄인다고 주장하며, 장시간 오디오 전사 속도가 경쟁 모델 대비 최대 5배 빠르다고도 언급하지만, 두 수치 모두 벤더 자체 보고 수치입니다 .
MAI-Voice-2는 Foundry의 텍스트→음성 모델로 패밀리를 완성하며, VS Code와 Dynamics 365 Contact Center에 통합되고 있습니다. 15개 언어를 지원하고, 5~60초 분량의 참조 오디오로 제로샷 음성 프롬프팅, 감정 태그, 명시적 동의 가이드라인을 갖추었습니다. Microsoft는 나란히 비교한 테스트에서 평가자 72%가 MAI-Voice-1보다 MAI-Voice-2를 선호했다고 밝혔습니다 . 저비용 버전인 MAI-Voice-2-Flash는 출시 예정으로 안내되어 있습니다 .
이를 관통하는 논리는 기술보다 비즈니스에 가깝습니다. Microsoft가 Build 키노트에서 제시한 핵심은 "달러당 시장 최고의 품질"이며, "RLE와 그 안에서 구축한 모델이 당신의 해자가 된다"는 비전입니다. 공유된 인텔리전스를 빌리는 대신 고객이 직접 미세 조정하고 동작을 소유한다는 것입니다 . 공개된 모달리티별 가격과 PowerPoint 같은 내장 서비스는 이 주장을 직접 검증할 수 있게 해줍니다. 여전히 비공개 프리뷰에 머물러 있는 추론 플래그십과는 대조적입니다.
Microsoft가 MAI-Thinking-1에 대해 아직 공개하지 않은 것들
MAI-Thinking-1을 평가하는 개발자에게 가장 큰 미지수는 아키텍처가 아닌 상업적 부분입니다. Microsoft는 추론 플래그십 모델의 토큰당 가격을 공개하지 않았습니다. 같은 계열의 두 모델은 2026년 6월 2일자 공개 가격표와 함께 출시되었는데도 말입니다. MAI-Code-1-Flash는 입력 $0.75, 캐시 입력 $0.075, 출력 $4.50(100만 토큰당)으로 책정되어 있고 , MAI-Image-2.5는 텍스트 입력 $5, 이미지 입력 $8, 이미지 출력 $47(100만 토큰당)을 공시하고 있습니다 . Microsoft가 품질을 가장 강하게 홍보하는 모델이 정작 비용은 비공개 상태입니다.
접근 조건도 마찬가지로 부실합니다. MAI-Thinking-1은 Microsoft Foundry에서 비공개 프리뷰 중이지만 , 속도 제한·동시 요청 한도·SLA 조건은 공개 문서화되어 있지 않으며, Microsoft는 개발자가 초대를 받을 수 있는 기준도 명시하지 않았습니다. MAI Playground는 날짜 없이 '공개 프리뷰 곧 출시'로만 안내되고 있으며, 저비용 변형인 MAI-Voice-2-Flash도 일정 없이 '곧 출시'로만 표기되어 있습니다 . 정식 출시 일정은 확정되지 않았으며, 최종 API 조건도 미정입니다.
벤치마크 현황도 같은 단서를 달아야 합니다. 주요 수치—SWE-Bench Pro 52.8%(Claude Opus 4.6 대비), AIME 2025 97.0%, LiveCodeBench v6 87.7%—는 모두 벤더 자체 발표 수치이며, 1,276개 과제에 걸쳐 Claude Sonnet 4.6을 앞선 Surge 인간 선호도 결과도 마찬가지입니다 . 이 중 독립적으로 재현된 것은 아직 없습니다. Microsoft가 주장하는 SWE-Bench Pro 동등 성능과 외부 검증 사이의 간극은, 이 모델을 기반으로 구축할지 결정하는 이들에게 가장 중요한 미해결 질문입니다.
명확한 결론: MAI-Code-1-Flash와 MAI-Image-2.5는 지금 당장 평가 가능한 모델로 취급하십시오. 가격과 테스트 가능한 벤치마크가 모두 공개되어 있기 때문입니다. MAI-Thinking-1은 신뢰할 만하지만 가격 미공개 프리뷰로 보십시오—액세스를 요청하고 직접 벤치마킹해볼 가치는 있지만, 비용·한도·서드파티 점수가 나오기 전까지는 프로덕션 로드맵에 확정적으로 포함시킬 단계가 아닙니다.
자주 묻는 질문
MAI-Thinking-1이란 무엇이며 GPT-4o, Claude와 어떻게 다른가요?
MAI-Thinking-1은 Microsoft가 자체 개발한 첫 번째 플래그십 추론 모델입니다. 활성 파라미터 350억 개, 총 파라미터 약 1조 개 규모의 희소 Mixture-of-Experts 설계로, 다른 LLM에서 증류 없이 처음부터 학습되었습니다 . GPT-4o(OpenAI)나 Claude Sonnet 4.6(Anthropic)과 유사한 Chat Completions API를 제공하므로 통합 비용은 비슷합니다. 진짜 차이는 소유권과 데이터 계보입니다. Microsoft의 핵심 주장은 공급업체 독립성과 깨끗한 IP 출처—합성 학습 데이터 완전 배제—이지, 결정적인 벤치마크 우위가 아닙니다 . 점수만으로 선택하는 바로 대체재가 아닌 전략적 대안으로 바라보십시오.
MAI-Thinking-1에 지금 어떻게 액세스할 수 있나요?
2026년 6월 기준, MAI-Thinking-1은 Microsoft Foundry에서 초대 필요 비공개 프리뷰 상태입니다 . 조기 체험을 원하는 개발자는 서드파티 배포를 통해서도 접근할 수 있습니다. OpenRouter, Fireworks AI, Baseten에 등재되어 있습니다 . MAI Playground 공개 프리뷰는 '곧 출시'로 안내되고 있지만, Microsoft는 날짜를 확정하지 않았으며 정식 출시 조건도 아직 미정입니다 .
MAI-Code-1-Flash는 지금 Copilot에서 사용할 수 있나요?
네. MAI-Code-1-Flash는 2026년 6월 2일 GitHub Copilot에 롤아웃을 시작했으며, 일부 VS Code 사용자를 시작으로 이후 몇 주에 걸쳐 Free·Student·Pro·Pro+·Max 구독자에게 확대됩니다 . GitHub 가격 페이지에는 정식 출시·경량 모델로 명시되어 있으며, AI 크레딧 포함분 소진 후 입력 100만 토큰당 $0.75, 캐시 입력 $0.075, 출력 100만 토큰당 $4.50이 부과됩니다 . 플래그십 추론 모델과 달리, 지금 바로 평가할 수 있는 가격과 벤치마크가 공개되어 있습니다.
Microsoft의 MAI-Thinking-1 벤치마크 점수를 신뢰해도 될까요?
확정적 결론이 아닌 유력한 사전 정보로 취급하십시오. 주요 수치—SWE-Bench Pro 52.8%, AIME 2025 97.0%, LiveCodeBench v6 87.7%—는 모두 Microsoft 자체 평가 환경에서 나온 것이며, Claude Sonnet 4.6을 앞선 인간 선호도 결과는 Microsoft가 의뢰한 Surge 평가단의 1,276개 과제 연구에서 비롯되었습니다 . 2026년 6월 7일 기준, LMSYS·Artificial Analysis·커뮤니티 SWE-Bench에 이 모델의 독립 제출 결과는 존재하지 않습니다. 벤더 발표 수치를 바탕으로 프로덕션 결정을 내리기 전에 해당 리더보드를 지켜보십시오.
'제로 증류(zero distillation)'란 무엇이며 기업 활용에 왜 중요한가요?
'제로 증류'는 Microsoft가 사전 학습에서 LLM이 생성한 합성 텍스트를 일체 배제했음을 의미합니다. 30조 개의 사전 학습 토큰(및 3.55조 개의 중간 학습 토큰) 전부가 공개 및 라이선스된 인간 생성 출처—웹, 공개 GitHub 코드, 책, 학술 논문, 뉴스, 다국어 텍스트—에서 가져온 것입니다 . 실질적 함의는 출처 투명성입니다. 다른 모델 출력물에서 비롯된 저작권·IP 노출이 없습니다 . 의료·금융·법률 같은 규제 산업에서 이 깨끗한 데이터 계보는 증류 모델이 안고 있는 컴플라이언스·IP 리스크의 한 범주를 줄여줍니다.





