
NVIDIA가 역대 최대 규모의 오픈 웨이트 모델을 출시했습니다. 가중치는 무료로 다운로드할 수 있지만, 직접 구동하는 것은 주말 프로젝트가 아닌 데이터센터 수준의 작업입니다.
Nemotron 3 Ultra: 6월 4일 무엇이 등장했나
Nemotron 3 Ultra는 텍스트 전용 오픈 웨이트 혼합 전문가(MoE) 모델로, 총 5,500억 개의 파라미터를 갖추고 있으며 토큰당 550억 개가 활성화됩니다(레이블상 "550B-A55B"). 2026년 6월 4일 Hugging Face를 통해 공개되었습니다 . 표준 트랜스포머 스택이 아니라, "LatentMoE" 라우팅을 적용한 하이브리드 Mamba-Attention 설계를 사용합니다. 레이어 수 108개, 모델 차원 8192, 레이어당 512개 전문가 중 상위 22개가 활성화됩니다 .
라이선스는 아키텍처만큼 중요합니다. Ultra는 리눅스 재단의 허용적 OpenMDW-1.1 라이선스로 출시되며, 가중치·아키텍처·학습 데이터·레시피 전부를 포함하고, 출력 제한이나 사용료 조항이 없습니다 . 네 가지 체크포인트가 공개됩니다: BF16 베이스, BF16 포스트 트레이닝, NVFP4 포스트 트레이닝, RLHF용 GenRM 보상 모델 . 현실적인 셀프 호스팅 경로는 NVFP4입니다.
20조 토큰으로 사전 학습되었으며(데이터 컷오프 2025년 9월, 포스트 트레이닝 컷오프 2026년 5월), 투기적 디코딩을 위한 네이티브 멀티 토큰 예측 레이어와 1,048,576 토큰 컨텍스트 창을 갖추고 있습니다. 다만 해당 1M 컨텍스트 창에는 뒤에서 다룰 서빙 조건이 따릅니다 .
컨테이너를 내려받기 전에

이 모델은 워크스테이션용이 아닌 데이터센터급 하드웨어를 요구합니다. 4비트 양자화 환경에서도 소비자용 GPU 한 장으로 Nemotron 3 Ultra를 셀프 호스팅하는 경로는 없습니다. BF16 프로파일은 두 노드에 걸친 H100 16장 또는 단일 노드의 H200 8장이 필요하며, 더 작은 NVFP4 풋프린트도 H100 8장, H200 4~8장, 또는 B200/GB300 2장이 필요합니다 . GPU 수는 프로파일에 따라 달라지므로, 장비를 주문하기 전에 NIM 지원 매트릭스에서 본인의 구성을 반드시 확인하세요.
| 정밀도 | 최소 GPU 수 | 모델 캐시 디스크 |
|---|---|---|
| BF16 | H100 16장(두 노드) 또는 H200 8장 | ~1.1–1.7 TB |
| NVFP4 | H100 8장, H200 4~8장, 또는 B200/GB300 2장 | ~330 GB |
툴체인 최소 요구 사항은 다음과 같습니다: Ubuntu 22.04 LTS 이상, NVIDIA Container Toolkit 1.14.0+, CUDA SDK 12.9+, 드라이버 580+, Docker 24.0+ . 첫 번째 풀(pull) 전에 디스크 용량을 확보하세요. 컨테이너 이미지만 해도 위의 모델 캐시에 더해 약 38 GB에 달합니다. /opt/nim/.cache에 마운트된 전용 퍼시스턴트 볼륨을 미리 프로비저닝해 두면 반복 실행 시 수백 기가바이트를 재다운로드하지 않아도 됩니다 .
빠른 시작: 호스팅 및 셀프 호스팅 NIM
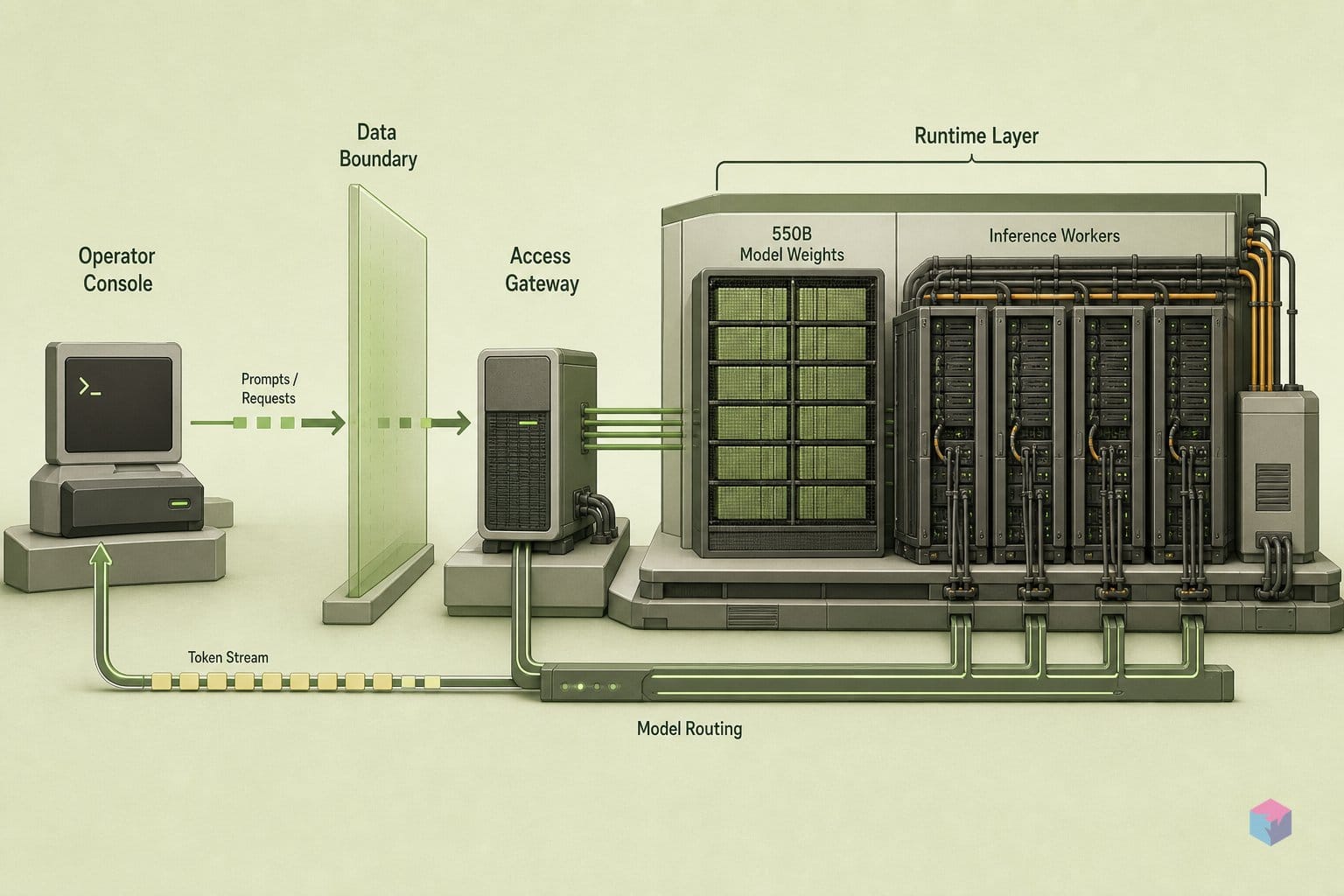
GPU를 한 장도 준비하지 않고 지금 당장 Nemotron 3 Ultra를 호출하려면 NVIDIA의 호스팅 NIM API를 이용하세요. OpenAI 프로토콜을 사용하므로 기존 클라이언트에서 변경해야 할 것은 base URL과 모델 이름뿐입니다. build.nvidia.com에서 API 키를 생성한 후, OpenAI SDK의 base URL을 https://integrate.api.nvidia.com/v1으로 설정하고 nvidia/nemotron-3-ultra-550b-a55b를 호출하면 됩니다 .
pip install openai
from openai import OpenAI
client = OpenAI(
base_url="https://integrate.api.nvidia.com/v1",
api_key="$NVIDIA_API_KEY",
)
resp = client.chat.completions.create(
model="nvidia/nemotron-3-ultra-550b-a55b",
messages=[{"role": "user", "content": "Plan a 3-step refactor."}],
temperature=1, top_p=0.95, max_tokens=16384,
extra_body={
"chat_template_kwargs": {"enable_thinking": True},
"thinking": {"type": "enabled", "budget_tokens": 10000},
},
)
print(resp.choices[0].message.content)Temperature 1, top_p 0.95, max_tokens 16384는 NVIDIA의 레퍼런스 설정이며, 추론은 최상위 필드가 아닌 extra_body를 통해 활성화됩니다 . budget_tokens 값은 모델이 답변 전 '생각'하는 양을 제한하며, 지연 시간과 응답 깊이를 조절하는 레버 역할을 합니다.
셀프 호스팅은 이전 섹션의 하드웨어와 디스크가 갖춰진 후 두 단계로 진행됩니다. 먼저 접근 설정: NVIDIA 개발자 프로그램에 가입하고, NGC 개인 API 키를 발급받아 모델의 NGC 약관에 동의한 다음, 리터럴 사용자 이름 $oauthtoken과 NGC 키를 비밀번호로 사용해 Docker 인증을 진행합니다 :
echo "$NGC_API_KEY" | docker login nvcr.io --username '$oauthtoken' --password-stdin
docker pull nvcr.io/nim/nvidia/nemotron-3-ultra-550b-a55b:2.0.5-variant
docker run --gpus=all -e NGC_API_KEY \
-v /opt/nim/.cache:/opt/nim/.cache \
-p 8000:8000 \
nvcr.io/nim/nvidia/nemotron-3-ultra-550b-a55b:2.0.5-variant \
--reasoning-parser nemotron_v3NIM 2.0.5는 vLLM 0.20.2 기반으로 빌드되었습니다 . --reasoning-parser nemotron_v3 플래그는 서버 측에서 thinking 제어를 활성화하며, 없으면 enable_thinking이 무시됩니다. 도구 호출에는 두 가지 추가 실행 플래그가 필요합니다: --enable-auto-tool-choice와 --tool-call-parser qwen3_coder . 한 가지 주의할 점: 컨테이너 자체는 MCP 서버에 연결되지 않으므로, MCP 기반 에이전트를 실행하는 경우 요청이 NIM에 도달하기 전에 클라이언트에서 MCP 도구 스키마를 OpenAI 도구 형식으로 변환해야 합니다.
주의사항: 공식 문서가 알려주지 않는 것들

실행 플래그 외에도, NVIDIA 마케팅과 자체 기술 문서 사이에는 실제 운영에서 문제가 될 수 있는 네 가지 불일치가 있습니다. 먼저 파라미터 수를 확인하세요. Hugging Face 파일 메타데이터는 BF16 아티팩트를 561B 파라미터로 표기하고 있으며 , 마케팅에서 내세우는 550B-A55B와는 다릅니다. 심각한 문제는 아니지만, 하드웨어 규모를 산정하거나 스펙을 인용할 때는 보도자료 수치가 아닌 모델 카드의 수치를 사용하세요.
두 번째 함정은 컨텍스트 윈도우입니다. NIM의 기본 서빙 한도는 262,144 토큰이며, 광고된 1,048,576 토큰(1M) 컨텍스트를 사용하려면 VLLM_ALLOW_LONG_MAX_MODEL_LEN=1과 --max-model-len 1048576을 설정해 실행해야 합니다 . NVIDIA는 이 설정이 동시 처리 성능을 저하시키며 품질 검증이 필요하다고 명시적으로 경고합니다. 누군가에게 1M 컨텍스트를 보장하기 전에, 실제 요청 조합으로 반드시 테스트하세요.
세 번째로, 추론 예산에는 측정 가능한 품질 급락 지점이 있습니다. NIM 2.0.5 릴리스 노트에 따르면 MTP는 오픈소스 vLLM 대비 채팅 처리량 약 17%, SWE 처리량 약 26% 향상을 제공하지만, 최대 추론 예산 설정 시 GPQA 정확도가 약 5퍼센트포인트 하락합니다 . 운영 환경에서는 모델이 무제한으로 추론하도록 두지 말고 thinking_token_budget에 상한을 두세요.
마지막으로, 헤드라인 수치는 비판적으로 바라보세요. 독립적인 테스트 결과가 중요합니다. Artificial Analysis는 출시 리뷰에서 다음과 같이 말했습니다:
"Nemotron 3 Ultra는 Artificial Analysis Intelligence Index에서 47.7점을 기록했습니다. 미국 오픈 웨이트 모델 중 선두로 gpt-oss-120b를 앞서지만, 53.9점의 Kimi K2.6에는 아직 미치지 못합니다," — Artificial Analysis (source: Artificial Analysis).
한편 NVIDIA의 "5.9배 처리량" 주장은 GLM-5.1 대비 8k 입력/64k 출력 설정에서의 내부 측정값으로 , 유리한 조건을 전제로 하며 독립적으로 검증된 수치가 아닙니다. 그 수치를 신뢰하기 전에 자신의 워크로드로 직접 벤치마크해보세요.
다음 단계
Ultra 서빙이 시작되면, 다음은 워크로드에 맞게 모델을 조정하는 단계입니다. 파인튜닝을 위해서는 nvcr.io/nvidia/nemo-automodel:26.04.00을 받아 NeMo Automodel LoRA PEFT 레시피를 실행하세요. 4× GB200(GPU 16개) 환경에서 검증되었으며, ep_size 32 설정의 H100 지향 4×8 변형도 문서화되어 있습니다 . 선호도 정렬을 수행하는 경우, 공개된 GenRM 리워드 모델 체크포인트를 NeMo Megatron Bridge 또는 github.com/NVIDIA-NeMo/Nemotron의 GRPO 및 GRPO-LoRA 레시피를 통해 RLHF 사후 훈련에 바로 적용할 수 있습니다 .
에이전트 측면에서는 CrewAI, LangChain Deep Agents, Hermes Agent, OpenCode 모두 OpenAI 호환 채팅 인터페이스를 통해 연결됩니다. base_url과 model만 교체하면 되며, SDK 추가 변경은 필요 없습니다 . 핵심은 이렇습니다: 호스팅 엔드포인트에서 시작해 워크로드를 검증한 뒤, 자체 호스팅의 수십만 달러에 달하는 GPU 비용을 감수하며 모델 가중치를 직접 보유할 가치가 있는지 결정하세요.
자주 묻는 질문
Nemotron 3 Ultra 셀프 호스팅에 필요한 최소 하드웨어 사양은?
현실적인 선택지는 NVFP4 체크포인트로, NIM 지원 매트릭스 기준 8× H100, 4–8× H200, 또는 최소 2× B200/GB300으로 실행 가능합니다 . BF16은 훨씬 무거워 16× H100(노드 2개) 또는 8× H200이 필요합니다 . 요구 사항은 프로필에 따라 다르며 정밀도와 카드 세대에 따라 달라지므로, 모델 카드의 개략적인 수치보다 지원 매트릭스와 선택한 정밀도를 기준으로 삼으세요.
호스팅 API는 무료인가요? 요청 제한은 어떻게 되나요?
build.nvidia.com은 파트너 엔드포인트 및 다운로드 옵션과 함께 무료 엔드포인트 티어를 제공하므로 , GPU 비용 없이 프로토타이핑할 수 있습니다. 정확한 쿼터와 토큰당 가격은 검토된 소스에 문서화되어 있지 않으며 엔드포인트별로 다르고 대부분 공개되지 않았습니다. 프로덕션 처리량이 필요하다면 파트너 엔드포인트를 직접 확인하세요. 지속적인 에이전트 부하 하에서도 무료 티어의 제한이 유지될 것이라고 가정하지 마세요.
NIM에서 1M 토큰 컨텍스트 윈도우는 실제로 어떻게 작동하나요?
NIM의 기본 컨텍스트는 262,144 토큰이며, 전체 1,048,576 토큰 윈도우를 사용하려면 VLLM_ALLOW_LONG_MAX_MODEL_LEN=1을 설정하고 --max-model-len 1048576으로 실행해야 합니다 . NVIDIA는 이 경우 동시성이 줄어든다고 경고하며 프로덕션 투입 전 장문 컨텍스트 출력의 품질 검증을 권장합니다. 모델 자체는 1M에서 RULER 기준 약 94.7%를 기록하지만 , 실질적 제약은 모델 성능이 아닌 서빙 용량에 있습니다.
구조화 출력과 도구 호출을 기본으로 지원하나요?
둘 다 작동하지만 기본적으로 활성화되어 있지 않습니다. tool_choice auto로 도구 호출을 사용하려면 NIM 실행 시 --enable-auto-tool-choice와 --tool-call-parser qwen3_coder가 필요합니다 . 구조화 출력은 response_format type json_object를 사용하며 스키마 유효성 검사는 클라이언트 측에서 처리됩니다 . 네이티브 MCP 커넥터는 없으므로 NIM 컨테이너에서 MCP 서버로 직접 연결되지 않습니다. 클라이언트에서 MCP 스키마를 OpenAI 스타일 도구로 먼저 변환해야 합니다.
독립 평가에서 Nemotron 3 Ultra는 Kimi K2·Qwen 3와 어떻게 비교되나요?
Artificial Analysis Intelligence Index에서 Ultra는 47.7점으로, 미국산 오픈 웨이트 모델 중 선두이며 Nemotron 3 Super(36.0)와 gpt-oss-120b(33.3)를 앞섰지만, Kimi K2.6(53.9)에는 뒤처집니다 . 즉, 미국 호스팅 공개 웨이트 중에서는 1위이지만 글로벌 최고의 오픈 웨이트 모델에는 미치지 못합니다. NVIDIA 자체 처리량 수치(예: GLM-5.1 대비 5.9배)는 특정 8k 입력/64k 출력 설정에 의존하므로 , 독립적으로 재현될 때까지는 방향성 지표로만 활용하세요.





