
NVIDIA의 Parakeet 음성 모델을 쓰려면 예전엔 Python 스택이 필요했습니다: NeMo, PyTorch, 그리고 항상 켜두어야 할 GPU까지. 새로운 C++ 포트는 이 모든 것을 바이너리 하나와 파일 하나로 압축합니다.
NeMo에서 GGUF로: 포트가 담은 것들
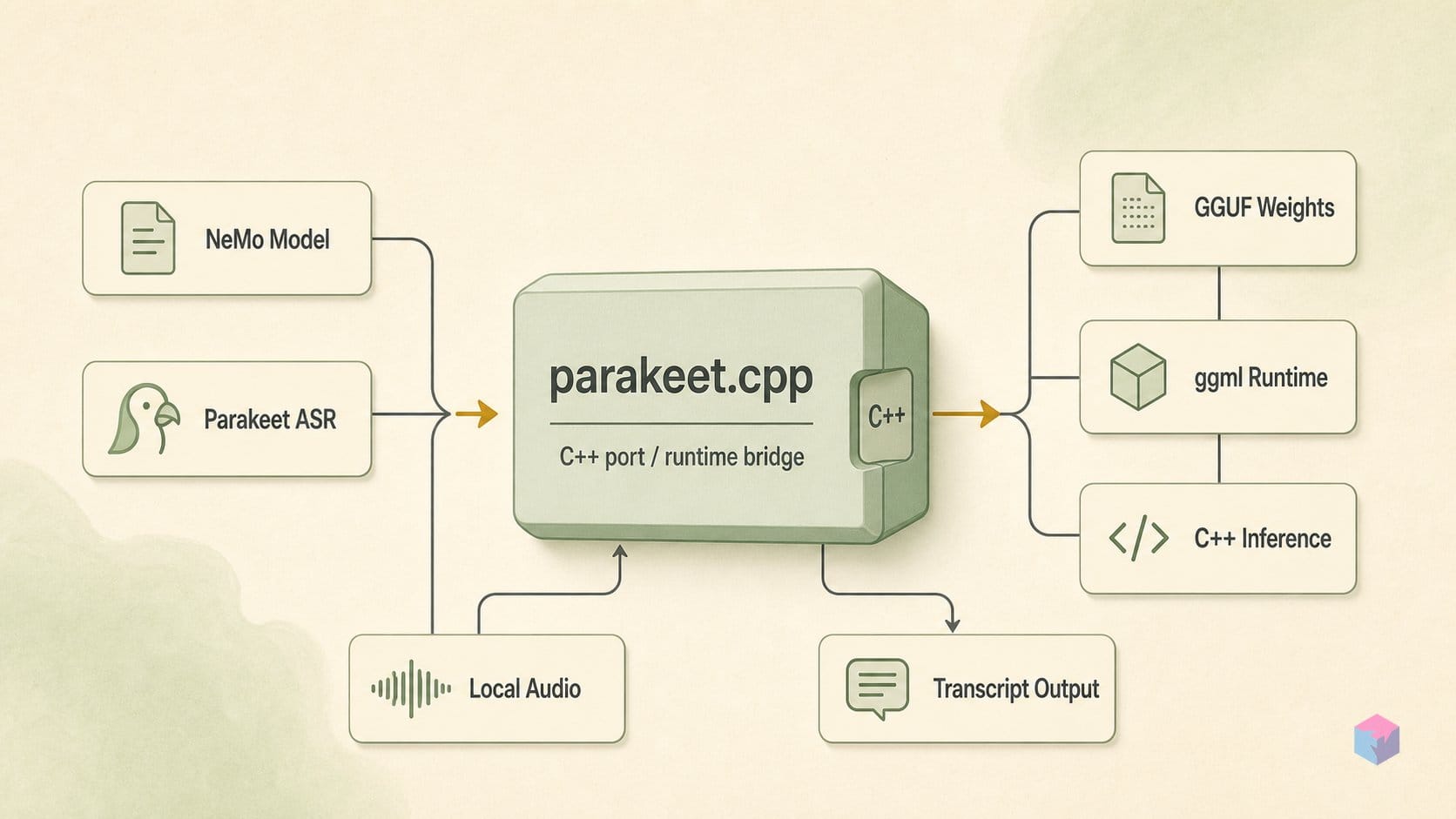
parakeet.cpp는 NVIDIA의 Parakeet 자동 음성 인식(ASR) 모델을 ggml 텐서 라이브러리 위에서 실행하는 C++17 추론 포트입니다 — whisper.cpp와 llama.cpp를 구동하는 바로 그 엔진이며, 추론 시점에 Python도, NeMo도, ONNX도 필요하지 않습니다. 이 프로젝트는 LocalAI 제작자인 Ettore Di Giacinto(@mudler)가 관리하며, 첫 태그 릴리스 v0.1.0은 2026년 5월 30일에 공개됐습니다 . 코드는 MIT 라이선스이며, 모델 가중치는 원래의 NVIDIA Parakeet 라이선스를 유지합니다. 이는 커뮤니티 프로젝트로, NVIDIA의 공식 릴리스가 아닙니다.
포트는 오프라인 Parakeet 계열 — CTC, RNNT, TDT, 하이브리드 TDT-CTC — 을 110M, 0.6B, 1.1B 크기로 지원하며, 발화 종료 감지 기능을 갖춘 스트리밍 120M 모델도 포함합니다 . 대부분의 사용 사례를 담당하는 체크포인트는 두 가지입니다: Hugging Face Open ASR 리더보드에서 평균 WER 6.05%를 기록한 영어 기본 모델 parakeet-tdt-0.6b-v2(2025년 5월 1일 출시) , 그리고 동일한 600M FastConformer-TDT 아키텍처를 자동 언어 감지와 함께 유럽 25개 언어로 확장한 parakeet-tdt-0.6b-v3(2025년 8월 14일 출시)입니다 .
추론은 CPU, CUDA, HIP(AMD ROCm), Vulkan, Metal(Apple Silicon)에서 동작합니다 — whisper.cpp, llama.cpp와 동일한 ggml 백엔드 매트릭스 — 따라서 배포는 바이너리 하나와 GGUF 파일 하나로 끝납니다 .
가장 어려운 부분은 Parakeet의 RNNT/TDT 디코더를 정적 그래프 텐서 라이브러리에 매핑하는 작업이었습니다. 초기 작업 중인 포트가 2025년 중반 Hacker News에 올라왔을 때, 작성자는 남은 길이 얼마나 먼지 솔직히 밝혔습니다:
"GGML 빌드는 MLX Python 버전보다 대략 1000배 느립니다" — jason-ni, 초기 Parakeet-on-ggml 실험 보고 (source: Hacker News, 2025; jason-ni 포트도 참고).
mudler 릴리스는 그 디코더-온-정적-그래프 문제에 대한 성숙한 해답입니다. 2026년 6월 현재 Parakeet는 아직 whisper.cpp 메인라인에 병합되지 않았으며 — 이를 추적하는 기능 요청(issue #3118)이 열려 있어 — 현재로서는 parakeet.cpp가 유일한 경로입니다.
컴파일 전에 준비할 것들
parakeet.cpp는 표준 C++ 툴체인으로 빌드되며 특별한 것은 없습니다: CMake(3.x), C++17 컴파일러(gcc, clang, 또는 MSVC), 그리고 서브모듈 지원이 되는 git — ggml은 재귀 클론 중에 서브모듈로 가져오기 때문입니다 . CPU 경로에는 추가 의존성이 없습니다. GPU 지원은 컴파일 시 선택 사항으로, CUDA는 CUDA 툴킷, HIP는 ROCm, Vulkan은 Vulkan SDK, Metal은 Xcode 커맨드라인 툴이 필요합니다 — 실제로 사용할 백엔드에 맞는 스택만 설치하면 됩니다 .
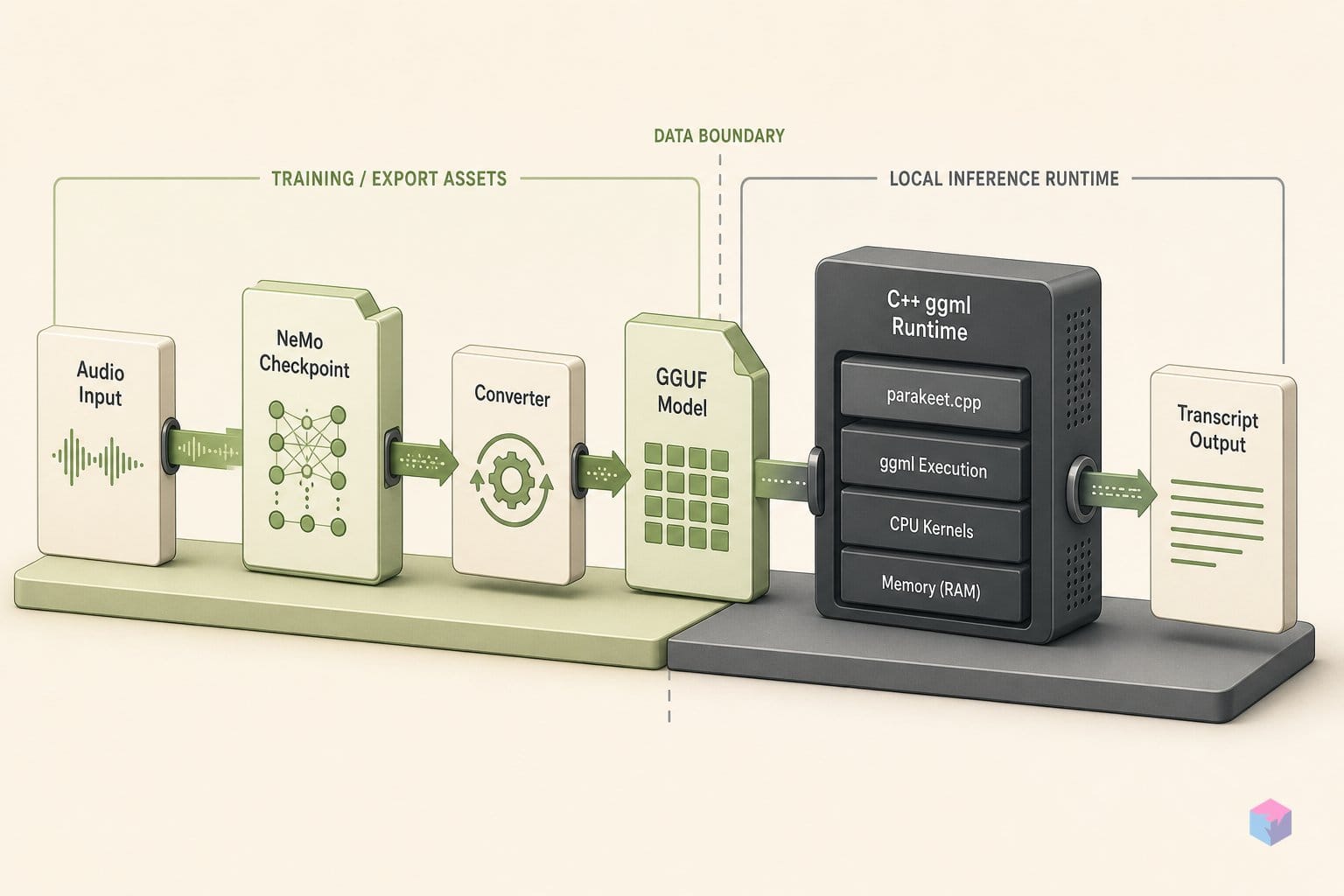
Python은 추론 경로에 포함되지 않습니다. 커스텀 .nemo 체크포인트를 GGUF로 변환할 때만 필요하며(검증된 버전인 NeMo 2.7.3 사용), 사전 변환된 가중치가 공개된 오프라인 체크포인트 10개를 모두 커버하므로 트랜스크립션 자체는 순수 C++입니다 .
입력 제약도 미리 파악해두어야 합니다: 오디오는 반드시 16kHz 모노 WAV 또는 FLAC이어야 합니다 . 스테레오, MP3, 44.1kHz 등 다른 형식은 트랜스크라이버에 전달하기 전에 먼저 ffmpeg으로 다운 변환해야 합니다.
세 가지 명령으로 컴파일, 가중치 다운로드, 전사까지
오디오를 16 kHz 모노로 준비했다면, 소스에서 전사본까지의 작업 경로는 세 가지 명령으로 완성됩니다: clone-and-build, GGUF 다운로드, CLI 실행. 기본 빌드는 CPU 전용이며 런타임에 Python, NeMo, ONNX를 일절 요구하지 않습니다 — CMake, C++17 컴파일러, 그리고 번들된 ggml 서브모듈만 있으면 됩니다 .
Step 1 — Clone 및 컴파일. --recursive 플래그가 중요합니다. ggml이 서브모듈로 벤더링되어 있기 때문입니다.
git clone --recursive https://github.com/mudler/parakeet.cpp
cd parakeet.cpp
cmake -B build -DPARAKEET_BUILD_CLI=ON && cmake --build build -jGPU를 사용하려면 백엔드 플래그를 하나 추가하세요: -DPARAKEET_GGML_CUDA=ON (NVIDIA), -DPARAKEET_GGML_METAL=ON (Apple Silicon), -DPARAKEET_GGML_HIP=ON (AMD), 또는 -DPARAKEET_GGML_VULKAN=ON. 빌드 호스트가 아닌 다른 하드웨어에서도 실행해야 하는 이식성 빌드나 CI 빌드에는 -DGGML_NATIVE=OFF를 사용하세요 .
Step 2 — 가중치 다운로드. 사전 변환된 GGUF 파일은 mudler/parakeet-cpp-gguf에 있습니다. F16이 권장 기본값입니다 — F32와 동일한 정확도를 유지하면서 최신 CPU에서 약 1.7배 빠르고, 용량은 F32의 57%에 불과합니다 .
huggingface-cli download mudler/parakeet-cpp-gguf tdt-0.6b-v2-f16.gguf --local-dir models/| 변형 (tdt-0.6b-v2) | 크기 | 비고 |
|---|---|---|
| F16 | 1404 MB | 권장 기본값 |
| Q8_0 | 904 MB | 무손실에 가까움 |
| Q4_K | 638 MB | 소폭의 단조 정확도 손실 |
| v3 F16 (다국어) | 1441 MB | 유럽 언어 25개 지원 |
크기는 모델 카드 기준 .
Step 3 — 전사. 단어별 타이밍과 신뢰도를 얻으려면 --timestamps를, 구조화된 출력을 원하면 --json을 추가하세요.
build/examples/cli/parakeet-cli transcribe \
--model models/tdt-0.6b-v2-f16.gguf \
--input audio.wav --timestamps --json디코더 헤드는 --decoder tdt 또는 --decoder ctc로 강제 지정할 수 있으며, 실시간 자막이 필요하다면 --stream과 함께 120M 발화 종료 모델을 실행하세요 . 파일을 로드하기 전에 parakeet-cli info model.gguf로 내용을 확인할 수 있고, parakeet-cli quantize m.gguf m_q4k.gguf q4_k로 F32 GGUF를 로컬에서 재양자화할 수 있습니다 — 지원 형식은 q4_0, q5_0, q8_0, q4_k, q5_k, q6_k입니다. 양자화는 선택적으로 적용됩니다: ggml_mul_mat가 처리하는 대형 선형 가중치만 압축되며, conv 커널, 정규화 레이어, LSTM 예측 네트, 임베딩은 F32를 유지합니다 .
주의 사항: 자체 하네스 WER, 양자화 트레이드오프, whisper.cpp와의 격차

parakeet.cpp의 동등성 주장은 프로덕션 보증이 아닌 회귀 테스트로 받아들이세요. 이 프로젝트는 공개된 오프라인 체크포인트 10개(v2, v3, CTC, RNNT, TDT, 하이브리드) 전부가 NeMo 2.7.3 대비 WER 0.0으로 검증되었다고 보고하지만, 그 수치는 단 하나의 7.4초짜리 LibriSpeech 픽스처에서 측정된 것입니다 . 이는 C++ 디코더가 해당 하네스에서 NeMo와 일치함을 확인할 뿐이며, 잡음, 화자 변이, 도메인 이동, v3의 25개 언어 전체에 대해서는 아무것도 말해주지 않습니다. 실제 서비스에 적용하기 전에 반드시 자체 오디오로 검증하세요.
성능 수치에도 동일한 단서가 붙습니다. 프로젝트 자체 벤치마크 — 20코어 호스트, 배치 크기 1, LibriSpeech test-clean 발화 100개 — 에서 NeMo CPU의 RTFx는 22.4, parakeet.cpp f32는 32.4, q8_0은 34.7이었으며, 상주 메모리는 NeMo 5,499 MB 대 f32 포트 2,545 MB였습니다 . 이는 포트 자체의 수치이므로, 레이턴시 SLA를 확정하기 전에 반드시 대상 하드웨어에서 재현해 보세요.
"이 하네스에서의 전사 동등성은 도메인, 화자, 잡음, 언어 전반에 걸쳐 동일한 실제 WER을 보장하지 않습니다" — parakeet.cpp 동등성 보고서 (source: mudler/parakeet.cpp).
선택에 영향을 주는 생태계 사실이 두 가지 있습니다. Parakeet는 2026년 6월 현재 whisper.cpp 메인라인에 병합되지 않았으며, 이슈 #3118이 parakeet-tdt-0.6b-v2 요청을 추적하고 있어 parakeet.cpp가 유일하게 지원되는 ggml 경로로 남아 있습니다 . SLA가 보장된 다이어리제이션 서빙이 필요하다면 NVIDIA의 ASR NIM이 동일한 모델을 TensorRT/Triton으로 패키징하지만, 컴퓨트 캐퍼빌리티 8.0 이상의 GPU와 최소 16 GB VRAM이 필요합니다 . 결론: 엔터프라이즈 지원이 필요하고 GPU를 보유하고 있다면 NIM을 선택하고, Python 런타임 자체가 부담이 되는 CPU, 엣지, 또는 프라이버시 민감 온디바이스 전사 환경에서는 GGUF 경로를 활용하세요.
자주 묻는 질문
parakeet.cpp는 GPU 가속을 지원하나요?
네. parakeet.cpp는 CUDA(NVIDIA), HIP(AMD/ROCm), Vulkan, Metal(Apple Silicon)용 ggml 백엔드를 제공하며, 각각 -DPARAKEET_GGML_CUDA=ON이나 -DPARAKEET_GGML_METAL=ON 같은 CMake 플래그로 컴파일 시 활성화합니다(mudler/parakeet.cpp). CPU 경로는 GPU 플래그 없이도 바로 동작하며, PARAKEET_DEVICE=cpu로 강제 지정할 수 있습니다. 프로젝트에서는 대형 TDT/하이브리드 모델에서 최대 4.3배 GPU 속도 향상을 보고하지만, 실제 하드웨어에서 직접 검증한 뒤 의존하세요.
프로덕션에서 parakeet.cpp를 사용하려면 Python이나 NeMo를 설치해야 하나요?
아니요. 추론은 순수 C++로 동작하며 Python, NeMo, ONNX 런타임 의존성이 없습니다. Python과 NeMo 2.7.3은 커스텀 .nemo 체크포인트를 GGUF로 변환할 때 딱 한 번만 필요합니다. 공개된 오프라인 체크포인트 10개는 이미 Hugging Face의 mudler/parakeet-cpp-gguf에 변환된 GGUF 가중치가 올라와 있으므로, 일반적인 배포는 바이너리 하나와 모델 파일 하나로 끝납니다(mudler/parakeet.cpp).
parakeet.cpp의 영어 정확도는 whisper.cpp large-v3-turbo와 어떻게 비교되나요?
영어 기본 모델 parakeet-tdt-0.6b-v2는 Hugging Face Open ASR 리더보드에서 평균 WER 6.05%를 기록합니다 . Whisper large-v3-turbo는 서로 다른 노이즈·도메인 조건에서 측정된 다국어 모델이므로 두 수치를 직접 비교할 수 없습니다. 정확한 결과를 얻으려면 자신의 오디오로 두 모델을 직접 실행해 보세요 — 리더보드 WER은 참고 지표일 뿐, 특정 도메인에서의 성능을 보장하지 않습니다.
어떤 GGUF 양자화 형식을 사용해야 하나요?
F16이 권장 기본값입니다. F32와 동일한 정확도를 유지하면서 ggml의 F32xF16 행렬 곱셈 경로를 통해 최신 CPU에서 약 1.7배 빠르게 동작하며, 크기는 F32의 약 57%입니다 . Q8_0은 F32 대비 약 37% 크기로 정확도 손실이 거의 없고, Q4_K는 약 26% 크기로 정확도가 소폭 단조 감소합니다 — 메모리가 절대적인 제약인 경우에만 Q4_K를 선택하세요.
parakeet.cpp는 영어 외의 언어도 처리할 수 있나요?
네. parakeet-tdt-0.6b-v3는 동일한 600M FastConformer-TDT 아키텍처를 자동 언어 감지 기능과 함께 25개 유럽 언어로 확장한 모델로, 2025년 8월 14일 Hugging Face에 출시됐습니다 . F16 기준 GGUF 크기는 1441 MB이며, A100 80GB에서 로컬 어텐션으로 최대 3시간 분량의 오디오를 처리할 수 있습니다 . v2 계열은 영어 전용입니다(F16 기준 1404 MB).





