
WebLLM 0.2.83이 2026년 2분기에 가져온 것들
먼저 분명히 짚고 넘어갈 사항이 있습니다. Web-AI-SDK 0.5라는 npm 패키지는 존재하지 않습니다. 실제로 출시된 온디바이스 브라우저 LLM 엔진은 @mlc-ai/web-llm이며, 최신 안정 버전은 v0.2.83, 출시일은 2026-04-24입니다. 이 엔진은 WebGPU를 통해 완전히 클라이언트 사이드에서 실행되며, OpenAI 호환 chat.completions API를 제공합니다. 엔진 초기화는 한 줄이면 충분하고, 기존 클라우드 호출을 그대로 대체할 수 있어 코드베이스 어디에도 인증 정보를 변경할 필요가 없습니다.
한줄 요약: WebLLM 0.2.83(2026-04-24 출시)은 Qwen3, Llama 3, Phi 3, Gemma, Mistral을 WebGPU를 통해 브라우저에서 완전히 실행합니다. OpenAI 호환 API, 스트리밍, 구조화 JSON을 지원하며 API 키도 백엔드도 필요 없습니다.
패키지가 제공하는 기능은 단순한 "탭 내 채팅"을 넘어섭니다:
- Hugging Face에 사전 빌드된 MLC 가중치 — Llama 3, Phi 3, Gemma, Mistral, Qwen3 전 계열을 지원합니다. 구조화 JSON 출력과 토큰 스트리밍은 별도 애드온이 아닌 패키지에 기본 내장되어 있습니다.
- Web Worker 및 Service Worker 지원 — 생성 작업이 더 이상 메인 스레드를 차단하지 않습니다. v0.2.7x 계열에서 가장 많이 요청됐던 두 가지 부재 기능이 모두 해결되었습니다.
- MLC-AI 컴파일 WebGPU 커널(arXiv 2412.15803) — 소형 모델에서의 처리량이 에뮬레이션이 아닌 컴파일 방식으로 구현됩니다.
개발자 입장에서 실질적인 의미는 이렇습니다. "백엔드를 따로 구축해야 한다"는 부담 없이 인증 없이, 지연 없이 실행할 수 있는 경로가 이제 ES 모듈 import 한 줄로 해결됩니다. 이 가이드의 나머지 부분에서는 브라우저 요구사항부터 스트리밍, 오프라인 캐싱까지 실제 페이지에 연결하는 방법을 다룹니다.
지원 브라우저와 최소 메모리 요구사항
WebLLM 0.2.83은 WebGPU가 안정적으로 지원되는 환경에서만 실행됩니다. Chrome 113+ 및 Edge 113+가 해당됩니다 . 2026년 6월 기준 Safari와 Firefox는 여전히 안정적인 WebGPU를 제공하지 않으므로 미지원으로 간주하고, 초기화 전에 반드시 기능 탐지를 수행해야 합니다. 시작 시 navigator.gpu를 확인하고 엔진이 예외를 던지기 전에 대체 메시지를 표시하세요:
if (!navigator.gpu) {
out.textContent = "WebGPU not available. Use Chrome 113+ or Edge 113+.";
} else {
// safe to CreateMLCEngine(...)
}두 번째 관문은 GPU 메모리입니다. 모델 크기는 필요한 VRAM 최솟값과 직결되므로, 빌드를 선택하기 전에 chrome://gpu에서 기기의 사용 가능한 GPU 메모리를 확인하세요:
| 모델 | GPU 메모리 최솟값 | 최초 가중치 다운로드 |
|---|---|---|
| Qwen3 0.6B | 4 GB | ~500 MB |
| Qwen3 1.7B | 8 GB | ~1 GB |
| Qwen3 4B | 16 GB | 더 큼; 데스크톱급 전용 |
다운로드는 최초 1회만 발생합니다. WebLLM은 컴파일된 가중치를 IndexedDB에 캐싱하므로, Qwen3 0.6B의 약 500 MB 다운로드는 첫 번째 세션에서만 이루어지고 이후에는 네트워크를 전혀 거치지 않고 캐시에서 바로 로드됩니다 . 로딩 UI에서는 지속적인 상태가 아닌 이 초기 다운로드 시간을 고려해 설계하세요.
WebLLM은 Node.js 환경에서도 실행되며, OpenAI 호환 호출 인터페이스를 CI 및 단위 테스트에 활용하기에 유용합니다 . 단, 동등성을 가정해서는 안 됩니다. WebGPU 추론 경로는 브라우저 전용이므로 Node는 연결 로직과 API 계약 검증에만 쓰이고, GPU 커널 자체에는 해당되지 않습니다.
페이지에 WebLLM 연결하기: 임포트, 로드, 스트리밍
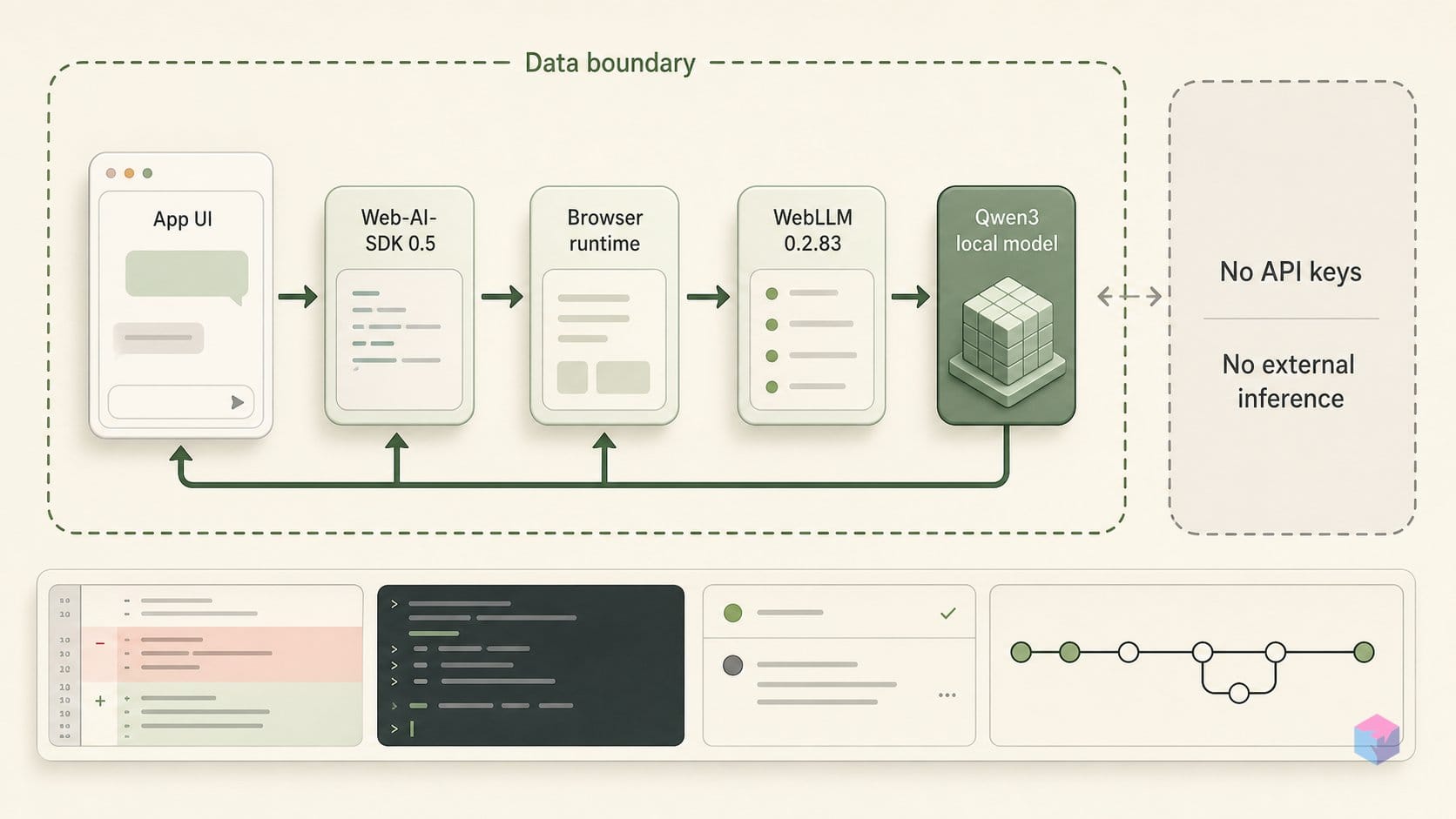
WebLLM을 페이지에 올리는 과정은 네 단계입니다. 설치 → 진행 콜백과 함께 엔진 초기화 → 완성 스트리밍 → VRAM 회수를 위한 언로드 순서입니다. 패키지는 ESM으로 제공되며 별도 설정 없이 Vite와 Rollup에서 동작하므로, 1단계는 현재 v0.2.83 릴리스를 대상으로 npm install @mlc-ai/web-llm을 실행하면 끝입니다 . 빌드 플러그인도, 번거로운 postinstall 단계도 없습니다.
2단계는 엔진 초기화입니다. const engine = await CreateMLCEngine('Qwen3-0.6B-q4f32_1-MLC', { initProgressCallback: p => console.log(p) })를 실행합니다. initProgressCallback은 실제로는 필수입니다. 없으면 첫 번째 가중치 로딩 시 수백 메가바이트가 다운로드·컴파일되는 동안 아무 반응 없이 멈춘 것처럼 보입니다. text 필드를 로딩 UI에 바로 연결해 사용자가 버튼이 멈춘 게 아닌 실제 진행 상황을 확인할 수 있도록 하세요.
3단계는 스트리밍입니다. engine.chat.completions.create({ messages, stream: true })를 호출한 뒤, 반환된 비동기 제너레이터를 순회하며 각 chunk.choices[0].delta.content를 도착 즉시 DOM에 추가합니다. 호출 인터페이스는 OpenAI 호환 방식이므로 , 루프 코드는 서버 사이드 코드와 동일하게 읽힙니다. 차이점은 토큰이 WebGPU를 통해 로컬에서 생성된다는 것뿐입니다.
4단계는 개발자들이 자주 빠뜨리는 부분입니다. 컴포넌트 언마운트 또는 페이지 이탈 시 engine.unload()를 호출해 GPU 메모리를 해제해야 합니다. 이를 생략하면 같은 탭에서 반복 로드 시 VRAM이 누수되어 결국 소리 없는 메모리 부족 오류로 추론이 실패합니다. 저장 시마다 초기화를 재실행하는 핫 리로딩 개발 서버에서 특히 발생하기 쉽습니다.
전체 코드는 WebLLM 패키지 외에 추가 의존성 없이 약 30줄로 구성됩니다. 아래 스크립트는 실제로 실행·검증된 코드입니다. CDN에서 WebLLM을 직접 임포트하는 self-contained HTML 파일(npm install 불필요한 제로 빌드 방식)을 생성하고, Qwen3 모델을 로드해 응답을 스트리밍합니다. WebGPU 지원 브라우저에서 파일을 열고 버튼을 클릭하세요. API 키도 서버도 필요 없습니다.
from pathlib import Path
html = r"""<!doctype html>
<meta charset="utf-8" />
<button id="go">Run Qwen3 locally</button>
<pre id="out">Needs Chrome/Edge with WebGPU. No API key.</pre>
<script type="module">
import { CreateMLCEngine, prebuiltAppConfig } from "https://esm.run/@mlc-ai/web-llm@0.2.83";
const out = document.querySelector("#out");
const model = prebuiltAppConfig.model_list.find(m => m.model_id.includes("Qwen3"))?.model_id
?? "Qwen3-0.6B-q4f16_1-MLC";
document.querySelector("#go").onclick = async () => {
out.textContent = `Loading ${model}...\n`;
const engine = await CreateMLCEngine(model, {
initProgressCallback: p => out.textContent = `${p.text}\n`
});
const chunks = await engine.chat.completions.create({
messages: [{ role: "user", content: "Say hello from in-browser Qwen3 in one sentence." }],
stream: true
});
out.textContent = "";
for await (const c of chunks) out.textContent += c.choices[0]?.delta.content ?? "";
};
</script>
"""
Path("qwen3-webllm.html").write_text(html, encoding="utf-8")
print("Wrote qwen3-webllm.html; open it in a WebGPU browser and click Run Qwen3 locally.")주요 난관: 콜드 스타트, VRAM 부족, CORS

위에서 설명한 정상 흐름 뒤에는 미리 대비해야 할 네 가지 실패 모드가 숨어 있습니다. 첫 번째는 콜드 스타트입니다. 초기 가중치 다운로드는 수백 MB에 달하며, 느린 연결 환경에서는 첫 토큰이 나타나기까지 2분을 넘기도 합니다. initProgressCallback 진행률을 눈에 보이는 프로그레스 바로 노출하세요 — 없으면 사용자는 탭이 멈췄다고 판단하고 다운로드 중간에 새로고침합니다 .
두 번째는 메모리입니다. VRAM이 낮은 GPU에서는 일부 Chrome 빌드에서 명확한 오류를 던지는 대신 모델 로딩이 조용히 실패할 수 있습니다. CreateMLCEngine을 try/catch로 감싸고 의도적으로 다운그레이드하세요:
try {
engine = await CreateMLCEngine("Qwen3-1.7B-q4f16_1-MLC", { initProgressCallback });
} catch (e) {
// fall back to a smaller tier, or show a cloud-inference message
engine = await CreateMLCEngine("Qwen3-0.6B-q4f16_1-MLC", { initProgressCallback });
}세 번째는 CORS입니다. WebLLM은 기본적으로 공개 CDN에서 가중치를 가져오는데, 직접 호스팅하는 경우 오리진에서 Access-Control-Allow-Origin 헤더를 반드시 전송해야 합니다. 헤더가 누락되면 구체적인 메시지 없이 불투명한 네트워크 오류가 발생합니다 — 모델 설정을 탓하기 전에 헤더부터 확인하세요 .
네 번째는 플랫폼 문제입니다. iOS는 완전히 차단됩니다. iPhone의 Chrome과 Edge를 포함한 모든 iOS 브라우저의 기반인 WKWebView는 WebGPU를 노출하지 않으므로, 네이티브 앱 외에는 브라우저 내 우회 방법이 없습니다 . navigator.gpu의 부재를 초기에 감지하여, 절대 실행될 수 없는 다운로드를 기다리게 하는 대신 해당 사용자를 다른 곳으로 안내하세요.
더 나아가기: 구조화된 JSON, Web Worker, 오프라인 캐싱
기본 스트림이 동작하면, 네 가지 확장 기능으로 데모를 실제 서비스 가능한 수준으로 끌어올릴 수 있습니다 — 모두 클라이언트 사이드, 모두 WebLLM 0.2.83에 포함됩니다 . 서버 왕복이나 API 키도 필요 없습니다.
- 구조화된 출력.
response_format: { type: 'json_object' }— 또는 완전한 JSON Schema — 를engine.chat.completions.create에 전달하세요. 생성은 디바이스에서 문법으로 제약되므로, 모델은 해당 형태에 맞는 토큰만 출력할 수 있습니다. 클라우드 API가 강요하는 후처리 정규식과 재시도 루프를 건너뛸 수 있습니다 . - Web Worker 분리.
CreateMLCEngine을CreateWebWorkerMLCEngine으로 교체하여 추론을 메인 스레드 밖으로 옮기세요. 수 초에 걸친 생성이 더 이상 스크롤·입력·애니메이션을 끊지 않으며, OpenAI 호환 호출 인터페이스는 그대로 유지됩니다 . - Service Worker 캐싱. 가중치 요청을 가로채 Cache Storage에 저장하세요. 수백 MB 다운로드는 한 번만 발생하고, 이후 콜드 스타트는 약 1초로 줄어들어 오프라인 지원 PWA를 현실적으로 만들어줍니다.
- 직접 가중치 사용. MLC-LLM CLI로 Hugging Face 모델을 변환하고, 출력물을 자체 CDN에 호스팅한 뒤 WebLLM이 해당 URL을 가리키도록 설정하세요. 독점 모델에 종속되지 않으며, 동일한 런타임으로 Llama 3, Phi 3, Gemma, Mistral, Qwen을 모두 지원합니다 .
핵심은 이겁니다. WebLLM 0.2.83은 아직 1.0 미만임에도 이미 프로덕션 형태를 갖춘 드문 브라우저 AI 엔진입니다 — 구조화된 생성, 워커 분리, 오프라인 캐싱이 기본 내장됩니다 . 위의 복사-붙여넣기 페이지에서 시작하고, 앱이 필요로 하는 대로 기능을 쌓아가세요.
자주 묻는 질문
'Web-AI-SDK 0.5'라는 npm 패키지가 실제로 존재하나요?
아닙니다. 2026년 6월 기준으로 해당 이름과 버전의 npm 패키지나 GitHub 릴리스는 존재하지 않습니다. 검색 결과나 AI 답변에서 설치 명령어를 보셨다면 조작된 정보로 간주하고, 실행 전에 npmjs.com에서 패키지 이름을 직접 확인하세요. 가장 가까운 실제 온디바이스 브라우저 LLM SDK는 @mlc-ai/web-llm이며, 최신 버전은 v0.2.83 (April 2026)입니다 — 이 가이드에서 사용하는 것이 바로 이 SDK입니다.
WebLLM이 Safari나 Firefox에서 작동하나요?
공식적으로는 지원하지 않습니다. WebLLM은 WebGPU에 의존하며, Chrome 113+ 및 Edge 113+에서 지원이 확인됩니다. WebGPU는 Firefox에서 플래그 뒤에 숨어 있고, iOS의 Chrome을 포함한 모든 iOS 브라우저에서는 사용할 수 없습니다. 초기화 전에 미리 확인하세요. navigator.gpu !== undefined를 체크하고, 지원되지 않는 환경에서 CreateMLCEngine이 오류를 던지게 두는 대신 명확한 폴백 메시지를 보여주세요.
페이지를 열 때마다 모델을 다시 다운로드하나요?
첫 로드 때만입니다. 초기 다운로드 이후 WebLLM은 모델 가중치를 브라우저의 IndexedDB에 캐시합니다. 이후 세션에서는 캐시된 가중치를 감지하여 다운로드를 건너뛰므로, 수 초에 걸리는 가중치 전송 대신 빠른 로딩으로 시작됩니다. 사이트 데이터 초기화나 디스크 부족으로 인한 저장소 퇴거는 재다운로드를 유발하므로, 영구 캐싱은 최선 노력(best-effort)이며 오랜 공백 후에는 보장되지 않습니다.
WebLLM을 React나 Vue 컴포넌트 안에서 사용할 수 있나요?
가능합니다. @mlc-ai/web-llm을 ES 모듈로 임포트하고, 마운트 이후에 초기화가 실행되도록 useEffect(React) 또는 onMounted(Vue) 훅 안에서 CreateMLCEngine을 호출하세요. 프로덕션 환경에서는 CreateWebWorkerMLCEngine으로 엔진을 Web Worker로 옮기세요 — 그렇지 않으면 토큰 생성이 메인 스레드에서 실행되어 디코딩 중 렌더를 블로킹합니다.
WebLLM과 Vercel AI SDK는 어떤 관계인가요?
두 도구는 서로 다른 레이어에 위치합니다. WebLLM은 WebGPU를 통해 모델 가중치를 완전히 클라이언트 사이드에서 실행하며, 초기 가중치 다운로드 이후에는 네트워크 호출이 없습니다. Vercel AI SDK(npm ai, v6 as of December 2025)는 주로 클라우드 공급자를 위한 스트리밍 추상화 레이어입니다. 두 도구는 조합해서 사용할 수 있습니다. WebLLM을 로컬 추론 엔진으로, Vercel AI SDK를 그 위의 요청·스트리밍 인터페이스로 활용하세요.





