
The mainstream LLM inference stack is built for throughput — pack many requests into a batch, keep the GPU busy. But when a single coding agent has to emit tens of thousands of serial tokens, that design hits a wall most engineers never measure: the cost of launching kernels.
The kernel-launch tax: ~1,125 µs per token, measured
The kernel-launch tax is the fixed CPU-side overhead paid every time the GPU is told to run an operation, and Kog AI's measurements put it at the center of why batch-size-one decode is slow. On a single node of 8× AMD Instinct MI300X, Kog measured launch-plus-cleanup overhead at roughly 4.5 µs per kernel . With about ten kernels per Transformer layer across roughly 25 layers — about 250 launches per generated token — that is approximately 1,125 µs of pure overhead before any arithmetic runs .
Quick Answer: Kog AI collapsed the entire token-decode path into one persistent GPU "monokernel," eliminating the per-operation kernel launches that cost ~4.5 µs each — about 1,125 µs of overhead per token. The result, announced May 28, 2026: ~3,000 output tokens/s per request on 8× AMD MI300X, batch size 1, FP16, no speculative decoding.
That overhead sets a hard ceiling. A target of 3,000 tokens/s implies a per-token budget near 333 µs, so spending 1,125 µs purely on dispatch is incoherent with the goal. Kog's simplified arithmetic shows the launch tax alone caps batch=1 decode near ~890 tokens/s — regardless of how much memory bandwidth (the MI300X offers 5.3 TB/s) or compute the hardware actually has . The bottleneck is structural, not silicon.
This is not a flaw in vLLM, SGLang, or TensorRT-LLM — it is the trade-off they were designed around. Those frameworks are architected on per-operation kernel dispatch because that flexibility lets a scheduler interleave many requests and keep utilization high under batched serving . For high-concurrency chat, where aggregate throughput and cost per million tokens dominate, that is the correct call. For a single agent generating one long serial stream, every kernel boundary is dead time on the critical path.
Kog's answer is to delete the dispatch loop entirely, folding model execution, communication, synchronization, prefetch, and token sampling into one resident GPU program . The cost is portability: the founder concedes the work is hand-written, "tedious," and must be redone per model and per GPU generation . The sections that follow trace exactly how that single kernel reclaims the headroom the launch tax leaves on the table.
Inside the monokernel: one persistent GPU program that never yields
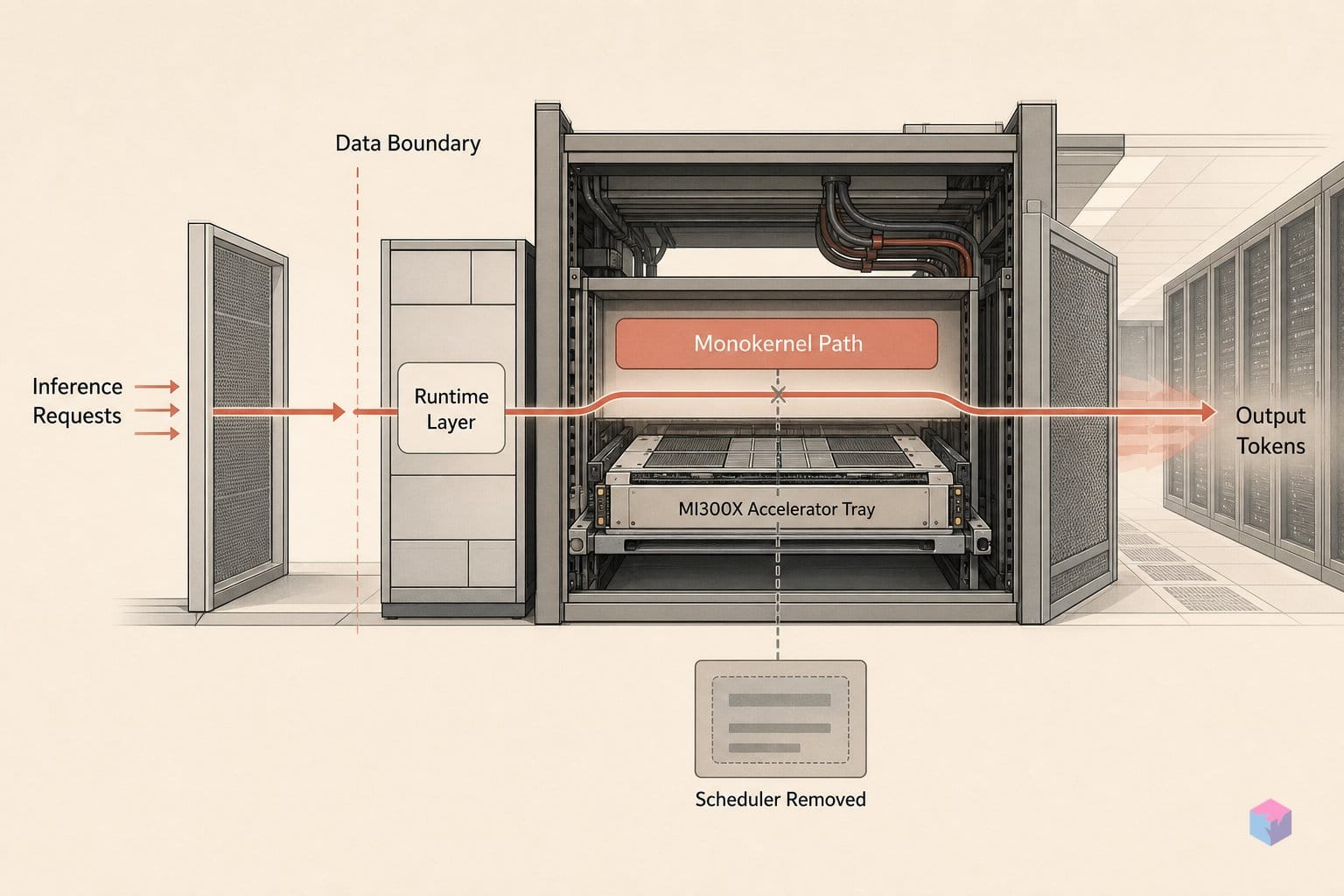
The monokernel is a single GPU-resident program that runs the entire token-decode loop without ever returning control to the host. Instead of relaunching kernels between tokens, Kog dispatches one persistent grid — gridDim=(256,), blockDim=(64,8) — and holds it on the device for the full decode loop, mapping one logical block to each active compute unit . That occupies 256 of the MI300X's 304 CUs , leaving the rest idle but eliminating the per-token launch-and-cleanup tax described earlier. There is no kernel re-launch between tokens and no CPU wake-up between decode steps.
Everything the runtime needs lives inside that resident program. Model execution, token sampling, tensor-parallel all-reduce, weight prefetch, and inter-CU synchronization all run on the GPU itself, with no host-side scheduler and no CPU-side sampling in the loop . The synchronization primitive is hand-tuned for the device: Kog reports a topology-aware barrier near 600 ns , and its deep dive measures 0.80–0.93 µs for its synchronization method against 7.59–7.88 µs for a naive approach in a 256-CU, 2048-byte-published-buffer test .
The math kernels are rewritten for the batch-size-one regime. At batch=1 every matrix multiply is really a GEMV, and the MI300X's matrix cores sit underutilized because the tiles they are built for never fill — so Kog drops them and issues scalar/vector ALU dot-product instructions (VDOT/SDOT) directly . Weights are streamed non-temporally into LDS and registers rather than cached, matching the memory-bound nature of single-request decode.
Layered on top is a set of fusions and offline precomputations that shrink the work done per token:
- RMSNorm folding — the normalization is folded into adjacent operations rather than run as a standalone pass.
- Offline QKV repacking — query, key, and value projections are repacked ahead of time so the runtime reads them in a layout it can stream cleanly.
- RoPE precomputation — rotary position embeddings are computed offline instead of recomputed each step.
- Attention recomputation — attention is recomputed locally rather than cached and exchanged across I/O dies, trading a little arithmetic to cut cross-die traffic .
The combined effect is a decode path that almost never touches DRAM round-trips it can avoid and never crosses the PCIe boundary mid-token. The trade-off, again, is generality: this is HIP and assembly-level work that the founder describes as tedious and re-done per model and per GPU generation . The next section looks at why the physical die layout makes that hand-tuning necessary.
MI300X die topology and how Kog maps 256 CUs to I/O dies
The hand-tuning is necessary because the MI300X is not one monolithic die — it is a package of chiplets, and where data physically lives determines how fast a kernel can reach it. AMD's specs describe the accelerator as a CDNA3 design with 192 GB of HBM3 at 5.3 TB/s peak bandwidth, 304 compute units, 256 MB of last-level cache, and a 750 W peak board power . Underneath, the MI300 series stacks up to 8 XCD compute chiplets, 8 HBM3 stacks, and 4 I/O dies, with 8 OAM modules per node wired together over Infinity Fabric . Crossing between those I/O dies costs bandwidth, so a kernel that ignores the layout pays for it on every token.
Kog's monokernel maps directly onto that physical floor plan. It launches with gridDim=(256,) and blockDim=(64,8), using 256 of the 304 CUs and pinning one logical block per active CU, then groups that work around I/O-die locality and duplicates buffers per I/O die to cut cross-die traffic . To place buffers correctly, Kog says it reverse-engineered the physical-address-to-IOD mapping — undocumented behavior — so that data a given CU touches stays on its own die rather than hopping the fabric mid-token .
The payoff shows up most clearly in synchronization. Inside a persistent kernel the 256 blocks still have to agree on a barrier each step, and a naive cross-die barrier is expensive. In a 256-CU test publishing a 2048-byte buffer, Kog reports a barrier latency of 0.80–0.93 µs for its topology-aware method against 7.59–7.88 µs for the naive approach — roughly a 9× faster round-trip . The headline post puts the production barrier at about 600 ns .
| Barrier method (256 CUs, 2048 B buffer) | Latency |
|---|---|
| Naive cross-die barrier | 7.59–7.88 µs |
| Kog topology-aware (test) | 0.80–0.93 µs |
| Kog topology-aware (production, reported) | ~600 ns |
At a ~333 µs per-token budget, shaving ~7 µs off every barrier — and avoiding cross-die buffer reads entirely — is the difference between hitting 3,000 tok/s and stalling well short of it. That is also why the work does not generalize cheaply: the address-to-die mapping is specific to this package, so the same effort has to be redone for the next GPU generation .
Delayed TP: how Kog hides all-reduce overhead at batch=1
Delayed Tensor Parallelism (DTP) is Kog's technique for taking the tensor-parallel all-reduce off the decode critical path by deferring it so it overlaps with later weight streaming or downstream compute. At batch size 1 this matters more than it does in batched serving: with many concurrent requests, the cost of synchronizing partial results across GPUs is amortized across the batch, but a single request has nothing to hide behind, so every all-reduce stalls the one token in flight until all eight GPUs agree on the result (source: Kog, 2026-05).
An 8× MI300X node splits each layer's weights across all eight accelerators, which communicate over AMD's Infinity Fabric. In its July 2025 MI300X benchmarks Kog measured roughly 4 µs cross-GPU latency at TP=8 — small in isolation, but the all-reduce after every attention and FFN block recurs ten-plus times per layer across ~25 layers, and at a per-token budget near 333 µs those serialized collectives accumulate into a meaningful slice of the critical path.
DTP restructures the dependency graph so the all-reduce no longer blocks the next operation. Instead of forcing each block to wait for the collective to finish before proceeding, Kog delays the reduction and lets it run concurrently with the prefetch of the following block's weights or with compute that does not yet depend on the reduced tensor. The reduction still happens; it just no longer sits on the wire while the GPU idles. Combined with the topology-aware barrier and FFN weight prefetching during attention described earlier, this keeps the device busy through what would otherwise be communication stalls.
The cost is generality. DTP is not a portable abstraction you drop into an existing framework — it has to be re-implemented for each model architecture and re-tuned for each GPU generation, and the founder frames this as deliberate engineering debt the team accepts in exchange for batch-1 latency (source: Hacker News discussion, 2026-05). That trade-off — hand-tuned overlap scheduling per model, per chip — is the same constraint that shapes everything in Kog's stack.
The 2B demo vs. frontier-scale: what Kog has and hasn't shown
The 3,000 tok/s headline rests on a small, deliberately stripped-down workload: a 2-billion-parameter Laneformer coding model that scores 50% on HumanEval, run at batch size 1 and a 4096-token sequence length with no quantization, no speculative decoding, no pruning, no early exit, and no KV-cache compression . That is the right way to isolate the kernel-overhead win — nothing else is helping the number — but it is also a 2B model, not a frontier one, and the gap between those regimes is where Kog's own caveats live.
Start with the ceiling. Kog's bandwidth analysis estimates roughly 33.6 TB/s of practical aggregate memory bandwidth across the 8× MI300X node, which puts a speed-of-light bound near 8,400 tok/s for a ~4 GB FP16 active-weight 2B model . At ~3,000 tok/s the monokernel is using about 36% of that theoretical maximum — fast for a launch-bound decode loop, but far from saturating the hardware, which leaves room for both further tuning and for larger models to claw back the headroom.
| Dimension | 2B preview (measured) | ~49B class (Kog projection) |
|---|---|---|
| Per-request decode | ~3,000 tok/s on 8× MI300X | ~1,000 tok/s on next-gen GPUs |
| Status | Benchmarked, batch=1 | Estimate / upper bound, not yet run |
| Bandwidth ceiling used | ~36% of ~8,400 tok/s bound | Dependent on KV-cache traffic, routing, collectives |
The projection itself is the tell. Kog estimates only ~1,000 tok/s for a ~49B-class model on next-generation GPUs, and frames that figure as a ballpark that depends on KV-cache traffic, expert routing, synchronization, collective communication, quantization, and batching . Those costs balloon with scale in ways a 2B, single-stream decode never exercises — larger KV caches add memory traffic per token, mixture-of-experts routing breaks the clean per-CU mapping, and cross-die exchange grows with model width.
"We haven't benchmarked a large model — the bigger numbers are upper bounds, and how they hold up depends on KV-cache traffic, routing, and synchronization." — paraphrase of Kog's founder, Hacker News discussion (source: Hacker News, 2026-05).
As of early June 2026, Kog has published no large-model benchmark; the primary, citable result is anchored at the 2B demo . The widely shared "3,300 tok/s" figure is a community and aggregator headline framed as an upper-bound case (batch 1, no speculative decoding, no quantization), not the wording Kog uses in its own posts . Treat 3,000 as the documented number and 3,300 as the optimistic edge — and treat anything frontier-scale as unproven until Kog ships a benchmark on a production-size model.
Groq, Taalas, and Cerebras: the comparisons Kog didn't make
Kog's 3,000 tok/s sits inside a crowded field of fast-decode claims, and most of the obvious rivals were absent from its benchmarks. Critics on Hacker News flagged three in particular — Taalas, Cerebras, and Groq — each of which reaches comparable or higher numbers through a different trade-off, so none is a clean head-to-head with Kog's FP16, batch-1, no-quantization result on MI300X . Reading them side by side is the only way to judge what 3,000 tok/s on a 2B model actually buys.
Taalas reportedly hits roughly 15,000 tok/s at batch size 1, but does it with 3-bit quantization that roughly halves the memory footprint a decode loop has to stream . That is a precision-for-speed bargain Kog explicitly declined; comparing it to Kog's FP16 figure compares two different problems.
Cerebras is the sharpest contrast because the headline number is identical. Cerebras officially advertises 3,000 tok/s for gpt-oss-120B on its wafer-scale hardware . The same throughput at 120B versus Kog's 2B is an order-of-magnitude harder problem — more active weights to stream per token — which is exactly the scaling gap left open in the previous section.
Groq belongs in a separate category. Its LPU is purpose-built deterministic silicon for serial decode, not a software optimization layered on a general-purpose GPU . Kog does not claim to beat Groq, and a software-vs-custom-hardware matchup would not be a fair one.
| System | Reported tok/s (batch=1) | Precision | Model size | Approach |
|---|---|---|---|---|
| Kog (MI300X) | ~3,000 | FP16 | 2B | GPU monokernel |
| Cerebras | ~3,000 | — | 120B (gpt-oss) | Wafer-scale hardware |
| Taalas | ~15,000 | 3-bit | — | Quantized custom stack |
| Groq | high (serial) | — | — | Custom LPU silicon |
Kog's earlier evidence has its own caveats. Its July 2025 AMD-hosted post claimed up to 3.5× faster token generation than vLLM and TensorRT-LLM on MI300X for 1B–32B active-parameter models, at batch size 1 and TP=8 . The methodology, though, was a single benchmark iteration after 10 warmups, and AMD attached a disclaimer that the content is Kog's opinion and not necessarily endorsed by AMD — worth weighing before treating the multiplier as settled.
Before you commit: what Kog hasn't yet proven at scale
If you run single-request, long-generation workloads on datacenter MI300X or H200 nodes, the Kog Inference Engine is worth a latency test today; for everything else, the case is unproven as of June 2026. The engine is proprietary and hand-written at the HIP/assembly level, and founder commentary on Hacker News concedes the optimization is tedious and must be redone per model and per GPU generation, with no general-purpose shortcut . No source release accompanies the tech preview, so the headline ~3,000 tok/s on 8× MI300X is documented by Kog but not independently reproducible from code .
Treat the "drop-in, vLLM-compatible replacement" framing as Kog's own marketing language, found on the company site rather than in a third-party report . No independent compatibility verification or replication has been published. The same caution applies to the multiplier in the July 2025 AMD-hosted post: AMD attached a disclaimer that the content is Kog's opinion and not necessarily endorsed by AMD .
The fit question is about workload regime, not raw speed. The engine targets batch-size-one serial decode, where one request emits tens of thousands of tokens in sequence and wall-clock task time is the bottleneck — AI coding jobs and extended reasoning runs are the clearest match. High-concurrency chat serving is a different problem, dominated by batching, queueing, time-to-first-token, and cost per million tokens, where batch-throughput-tuned frameworks already do the heavy lifting.
A decision rule:
- Buy signal: you own datacenter MI300X or H200 capacity and a meaningful share of jobs are single-request, long-generation. The untapped batch=1 decode headroom is real, and the live playground at playground.kog.ai lets you measure latency before committing .
- Skip for now: time-to-first-token or cost per million tokens dominates your SLA, you serve high concurrency, or you need frontier-scale models — Kog projected only ~1,000 tok/s for a ~49B-class model on next-gen GPUs and had not benchmarked one .
As one Hacker News commenter put it, extrapolating from the 2B demo to large models is like "assuming 256 cores gives 256× speedup" from a 4-core measurement . The kernel-launch insight is sound and well documented; the production-scale promise is not. Benchmark your own workload, weigh the lock-in of a closed, per-model-tuned stack, and let measured latency — not the 3,000 figure — drive the call.
Frequently asked questions
What is a monokernel (or megakernel) in GPU LLM decoding?
A monokernel is a single, persistent GPU-resident program that runs the entire token-decode path without exiting between tokens. Conventional stacks launch a separate kernel for each operation — GEMV, all-reduce, normalization, sampling — and pay a fixed cost at every boundary. Kog measured MI300X launch-plus-cleanup overhead at roughly 4.5 µs per kernel, which across ~10 kernels per layer over ~25 layers implies about 1,125 µs of pure overhead per token. The monokernel keeps model execution, communication, synchronization, prefetch, and sampling inside one resident program, removing CPU-side scheduling and that per-step launch tax.
Does Kog's 3,000 tok/s result apply to large LLMs like 70B or 405B?
Not yet demonstrated. The published headline of 3,000 output tokens/s per request on 8× MI300X is for a 2-billion-parameter coding model at batch size 1 in FP16, with no quantization or speculative decoding. Kog's own projection for a ~49B-class model is only about 1,000 tok/s on next-generation GPUs, and it had not benchmarked a large model. KV-cache traffic, synchronization overhead, and collective costs scale with model size in ways the 2B demo does not capture, so frontier-scale performance remains an upper-bound estimate.
How does the monokernel approach differ from speculative decoding?
They attack different bottlenecks. Speculative decoding reduces the total number of decode iterations by proposing multiple tokens per step with a draft model, then verifying them. The monokernel instead removes per-step kernel-launch and CPU-scheduling overhead within each iteration. The two are potentially complementary rather than competing, though Kog's benchmarks use neither speculative decoding nor any multi-token method, running vanilla autoregressive decoding at 4096 sequence length. Speculative and multi-token approaches also shift the bottleneck away from the memory-bound batch=1 regime the monokernel targets.
Is Kog's inference engine open source or publicly accessible?
It is proprietary. A live playground is available at playground.kog.ai for latency testing, and Kog markets the engine as a vLLM-compatible drop-in replacement — a vendor claim, not an independently verified one. The implementation is hand-optimized HIP/assembly-level code that, per the founder, must be redone per model and per GPU generation. Source is not public, so independent replication from code is not possible today. The tech preview launched May 28, 2026.
When does single-request decode speed matter more than aggregate serving capacity?
It matters when a single request generates tens of thousands of serial tokens and wall-clock task time is the bottleneck — AI coding agents, long reasoning chains, and autonomous task loops. There, batch-size-one decode speed directly controls how long a job takes. High-concurrency chat serving is a different regime: it is dominated by batching, queueing, time-to-first-token, and cost per million tokens, where a batch=1 optimization offers little advantage. As Kog frames it, batch-throughput-tuned frameworks like vLLM, SGLang, and TensorRT-LLM leave substantial single-request headroom on the table.






