
At its Build 2026 developer conference on June 2, 2026, Microsoft did something it had not done before: it shipped a full, named first-party model family rather than a wrapper around someone else's. If you write code in VS Code, one of these models may already be answering your prompts — while the flagship sits behind a private preview gate.
What Microsoft's MAI Family Introduced on June 2
Microsoft AI introduced seven first-party "MAI" (Microsoft AI) models spanning five modalities — reasoning, coding, image, transcription, and voice — at Build 2026 on June 2, 2026 . This is the first time Microsoft has fielded a named in-house frontier model family distinct from its OpenAI partnership products, reducing its reliance on outside providers for some reasoning and coding workloads. Microsoft frames the effort as a "hill-climbing machine": a shared pre-training and infrastructure pipeline that lets it ship across modalities at once .
| Model | Modality | Status at launch |
|---|---|---|
| MAI-Thinking-1 | Reasoning (flagship) | Foundry private preview |
| MAI-Code-1-Flash | Agentic coding | Routing in GitHub Copilot / VS Code |
| MAI-Image-2.5 | Text-to-image / editing | Live (PowerPoint, Foundry) |
| MAI-Image-2.5-Flash | Image (low-cost) | Live |
| MAI-Transcribe-1.5 | Speech-to-text | Available |
| MAI-Voice-2 | Text-to-speech | Available |
| MAI-Voice-2-Flash | Text-to-speech (low-cost) | "Coming soon" |
The critical split is in availability. MAI-Code-1-Flash, a 5-billion-active-parameter agentic coding model, is already rolling out to GitHub Copilot individuals in VS Code through the model picker and Auto routing . The flagship MAI-Thinking-1 — a sparse mixture-of-experts model with 35B active parameters, roughly 1T total, and a 256K-token context window — remains gated to Azure/Microsoft Foundry private preview .
The most citable provenance fact comes from the technical report: MAI-Thinking-1's base, MAI-Base-1, was pre-trained from scratch on an 8K GB200 GPU Azure cluster using 30T pre-training tokens plus 3.55T mid-training tokens — 33.55T total — with no LLM-generated synthetic data during pre-training . The model card lists a July 2025 training cutoff .
MAI-Thinking-1: What the Technical Report Says vs. What Is Independently Verified
MAI-Thinking-1 is a sparse mixture-of-experts model with roughly 35 billion active parameters drawn from about 1 trillion total, a 256K-token context window, function calling, developer instructions, and Chat Completions API compatibility . That architecture matters for builders because the active-parameter count, not the trillion-parameter headline, drives inference cost — a mid-sized routing graph aimed at long-context reasoning and code generation at lower token spend. Every performance number attached to it, however, comes from Microsoft's own technical report rather than a neutral leaderboard, so the honest read is "vendor-reported pending independent replication."
The technical report lists the following scores, all self-measured:
| Benchmark | MAI-Thinking-1 (Microsoft-reported) | What it tests |
|---|---|---|
| AIME 2025 | 97.0% | Competition math reasoning |
| AIME 2026 | 94.5% | Competition math reasoning |
| LiveCodeBench v6 | 87.7% | Code generation |
| GPQA Diamond | 84.2% | Graduate-level science QA |
| SWE-bench Verified | 73.5% | Real-world software fixes |
| SWE-Bench Pro | 52.8% | Harder software engineering |
| Terminal-Bench 2.0 | 46.0% | Agentic terminal tasks |
Source: Microsoft's MAI technical report . The framing to watch is selective. Microsoft highlights that its 52.8% on SWE-Bench Pro sits within a point of Claude Opus 4.6 at 53.4% on the same benchmark , but the near-parity headline quietly omits that the same report shows Anthropic's models still leading on SWE-bench Verified and Terminal-Bench 2.0. Pick the benchmark, pick the winner.
Microsoft also leans on human preference data: a blind Surge evaluation across 1,276 single- and multi-turn tasks reportedly favored MAI-Thinking-1 over Claude Sonnet 4.6 on overall quality . The caveat is structural — Surge was commissioned by Microsoft, so it is a vendor-funded study, not an arm's-length one.
"MAI-Thinking-1 matches Claude Opus 4.6 on SWE-Bench Pro coding," Microsoft states in its Build 2026 keynote materials (source: Microsoft AI keynote transcript) — a claim worth holding until a neutral evaluation reproduces it.
At publication there is no independent third-party replication of any of these figures. Treat the architecture specs as solid (they describe a shipped, fixed model) and treat the benchmark and preference numbers as early vendor claims until a neutral leaderboard such as a public Arena run or Artificial Analysis re-test posts comparable results.
Microsoft Owns the Weights — and That Is the Enterprise Licensing Differentiator
The sharpest differentiator in the MAI launch is not a benchmark — it is provenance. Microsoft states that all seven models were pre-trained from scratch on clean, commercially licensed, traceable data, with no distillation from rival labs and no fine-tuning of open-source base models . The technical report goes further: the base model MAI-Base-1 was pre-trained on 8K GB200 GPUs across a Microsoft-operated Azure cluster, on 30T pre-training tokens plus 3.55T mid-training tokens drawn from public and acquired sources, with no LLM-generated synthetic data used during pre-training .
For enterprise buyers, the implication is a cleaner IP indemnification story. A model with documented, commercially licensed training data is easier to defend in procurement and legal review than one that distills outputs from third-party frontier APIs or builds atop open weights of uncertain lineage. That matters most for regulated, document, and call-center workflows where data provenance and copyright exposure are live concerns — exactly the surfaces (Office, Teams, Dynamics, Foundry) Microsoft is targeting .
"We trained these models from scratch on clean, commercially licensed data — no distillation, no open-weight base," Microsoft AI states in its launch materials, framing the family as a "hill-climbing machine" of shared training infrastructure (source: Microsoft AI).
The caveat is that this is an assertion, not an audited fact. No independent methodology audit or third-party attestation of the data pipeline has been published; the "trained from scratch, no distillation" claim is currently unverifiable from outside the company. Treat it as differentiating positioning pending external evidence.
The contrast with the same week's releases makes the positioning deliberate. Nvidia's Nemotron 3 Ultra — a 550B-parameter open hybrid Mamba-Transformer — and Google's Apache-licensed Gemma 4 12B both build explicitly on open or publicly licensed foundations . Microsoft is selling the opposite story: proprietary, owned weights with a controlled data trail, which it argues is the safer foundation for enterprises worried about lineage and indemnification (video: Alex Volkov from ThursdAI).
The Copilot Routing Change: What MAI-Code-1-Flash Does in Your IDE
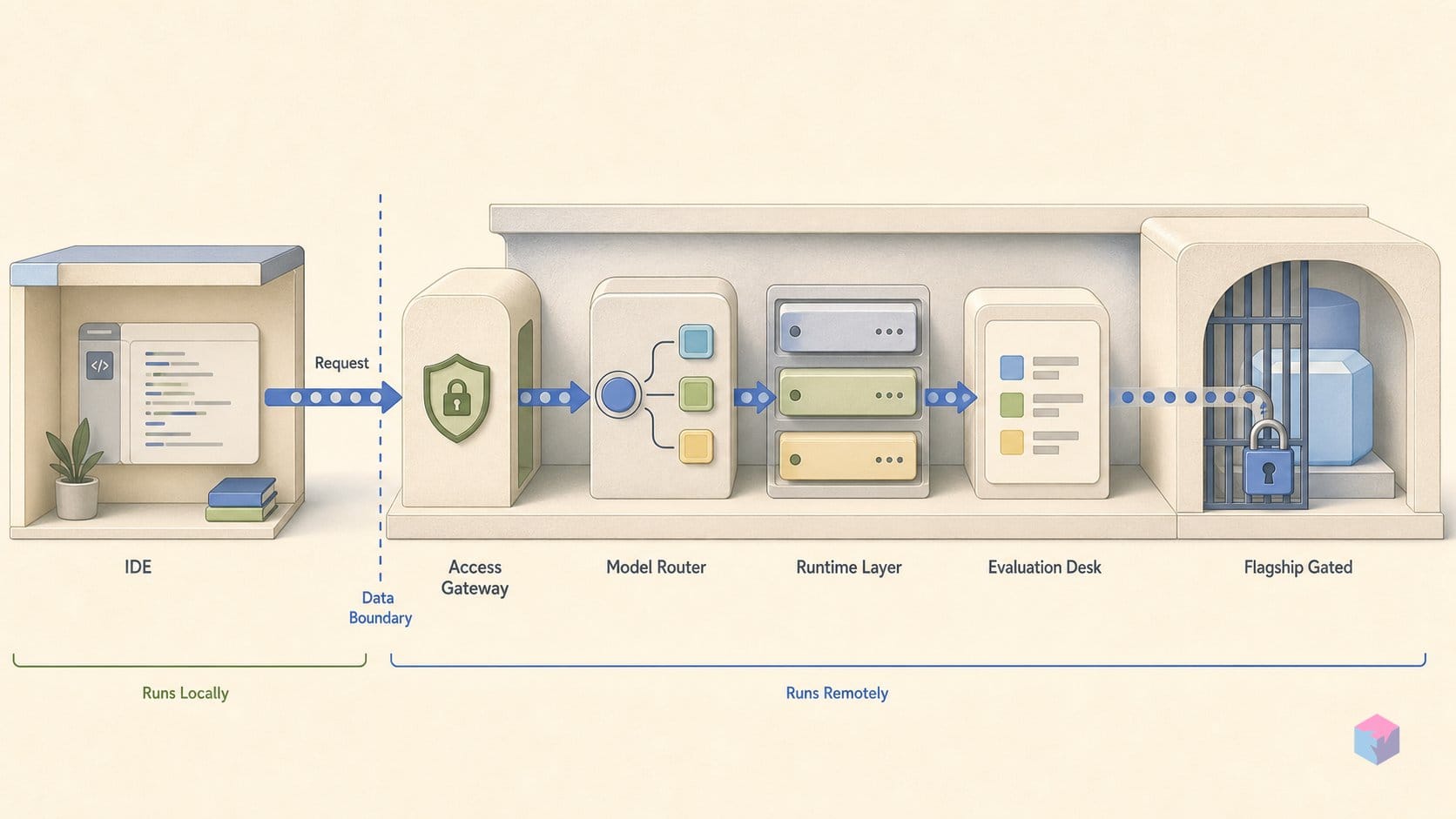
The model most developers will actually touch first is not the gated flagship — it is MAI-Code-1-Flash, a roughly 5-billion-active-parameter agentic coding model purpose-built for Microsoft's IDE stack . As of the Build 2026 announcement on June 2, it is rolling out to GitHub Copilot individual users inside VS Code through the model picker and the default Auto routing path, with the keynote footnote specifying about 10% of individual users as the starting cohort . There is no explicit opt-in: if you leave Copilot on Auto, you may already be running a Microsoft in-house model on everyday completions and small agentic tasks without ever selecting it.
Positioned as the inexpensive workhorse slot, MAI-Code-1-Flash targets roughly Claude Haiku-class quality at a lower per-token cost. Microsoft reports it beat Claude Haiku 4.5 in its production harness across SWE-Bench Verified, SWE-Bench Pro, SWE-Bench Multilingual, and Terminal-Bench 2 — including 51.2% versus 35.2% on SWE-Bench Pro — and says it can solve harder problems with up to 60% fewer tokens on SWE-Bench Verified . As with the rest of the family, treat those as vendor-reported figures until an independent harness replicates them.
Microsoft frames the model as native to its developer surfaces rather than a general drop-in. "MAI-Code-1-Flash is built specifically for the Microsoft developer stack — GitHub Copilot and VS Code," the launch materials state (source: Microsoft AI, 2026-06). For non-Copilot integrations, the same model is also distributed through OpenRouter, Fireworks, and Baseten, so you can wire it into your own tooling outside the IDE .
What it deliberately does not do is the heavy lifting. Complex multi-step reasoning and long-context work are not its job; those requests stay routed to the gated MAI-Thinking-1 or to third-party frontier models you can still pick manually in Copilot's model selector (video: thehype.). The practical takeaway: MAI is already in your editor on the cheap, high-volume tasks — while the model that would actually rival Opus-class reasoning is the one you cannot freely call yet.
Live vs. Gated: Which MAI Models You Can Call Today
As of June 8, 2026, four MAI models are in some form of public rollout and three remain gated or unshipped. The models you can actually reach today are the high-volume, narrow-task ones — coding, image, transcription, and voice — while the flagship reasoning model stays behind a private-preview wall. MAI-Code-1-Flash is rolling out to GitHub Copilot individual users in VS Code, starting at roughly 10% of users via the model picker and Auto routing . MAI-Image-2.5 is live in PowerPoint and rolling out to OneDrive, alongside Foundry availability . MAI-Transcribe-1.5 and MAI-Voice-2 are distributed through Microsoft Foundry .
The gated set is where the strategic caution shows. MAI-Thinking-1 is in Azure/Microsoft Foundry private preview only, with a broader MAI Playground public preview promised but undated . MAI-Image-2.5-Flash is staged, and MAI-Voice-2-Flash is described only as "coming soon" with no date .
| Model | Status (June 8, 2026) | Where to call it |
|---|---|---|
| MAI-Code-1-Flash | Rolling out (~10% of Copilot individuals) | GitHub Copilot / VS Code model picker |
| MAI-Image-2.5 | Live | PowerPoint, OneDrive, Foundry |
| MAI-Transcribe-1.5 | Available | Foundry |
| MAI-Voice-2 | Available | Foundry |
| MAI-Thinking-1 | Private preview only | Azure / Foundry (gated) |
| MAI-Image-2.5-Flash | Staged | Foundry (partial) |
| MAI-Voice-2-Flash | "Coming soon," no date | Not yet shipped |
Pricing is mostly opaque. The exception is MAI-Image-2.5, with published Foundry rates of $5 per 1M text input tokens, $8 per 1M image input tokens, and $47 per 1M image output tokens; the Flash variant lists $1.75, $1.75, and $19.50 . The MAI-Thinking-1 model card states only that cost depends on deployment type and token volume — no concrete price, no rate-limit or quota documentation . Foundry is the primary enterprise access point; broader developer distribution runs through OpenRouter, Fireworks, and Baseten, but direct API access outside Foundry varies by model and is not yet fully documented .
How MAI Stacks Up Against Rivals From the Same Week

MAI launched into a crowded release window, and within days its strongest leaderboard claims were already contested — so the honest read is near-parity, not dominance. In the same cycle, Nvidia shipped Nemotron 3 Ultra, a 550B-parameter open hybrid Mamba-Transformer claiming roughly 5x faster inference and available on CoreWeave; Google released Gemma 4 12B, a multimodal Apache-licensed model; and Ideogram 4.0 arrived as 9.3B open weights . Against that field, MAI does not hold a clear across-the-board lead.
On image generation, Microsoft positioned MAI-Image-2.5 at roughly No. 3 for text-to-image and No. 2 for image-to-image on Arena/ELO at announcement . But community arena results from the same week placed Ideogram 4.0's open weights at the top open text-to-image slot, ahead of MAI-Image-2.5 . A ranking that slips within days of launch is a reminder of how fast these boards churn.
"MAI-Image looked strong at announcement, but Ideogram 4.0's open release took the top open text-to-image spot in the arena the same week — these leaderboard positions are contested almost immediately," noted Alex Volkov in his weekly roundup (video: ThursdAI).
The reasoning picture is similar. Microsoft's own technical report puts MAI-Thinking-1 at 52.8% on SWE-Bench Pro, just under Claude Opus 4.6's 53.4% — near-parity on one benchmark, not a win . The same report shows MAI-Thinking-1 trailing on SWE-bench Verified (73.5%) and Terminal-Bench 2.0 (46.0%), where Sonnet 4.6 and Opus 4.6 still lead . That is a competitive showing on selected measures, not a broad sweep.
For developers choosing where to route work, the net signal is this: MAI's edge is not benchmark supremacy. Its real differentiation is the enterprise IP lineage story — models Microsoft says were trained from scratch on licensed, traceable data . If you need provenance and Microsoft-managed deployment, MAI is compelling. If you are optimizing purely on capability per benchmark, the same-week field gives you credible, sometimes higher-ranked, alternatives.
What the Announcement Left Out: Fees, GA Dates, and Undisclosed Specs
Before you commit a workload to MAI, weigh what Microsoft did not publish. There is no public price for any of the seven models, no general-availability date for the flagship, and no parameter or throughput disclosure for five of the seven — meaning core procurement and capacity-planning inputs are missing at launch. The MAI-Thinking-1 model card states only that cost depends on deployment type and token volume, with no concrete per-token figure attached .
The gaps cluster around four practical unknowns:
- Pricing. Microsoft Foundry lists rates for MAI-Image-2.5 ($5 / $8 / $47 per 1M text, image-input, and image-output tokens) and its Flash variant , but no published price exists for Thinking-1, Code-1-Flash, Transcribe-1.5, or the Voice models. Cost-per-task comparisons against Claude or GPT routes are therefore not yet possible.
- GA timing. MAI-Thinking-1 ships in Azure/Microsoft Foundry private preview . Private preview leaves quota policy, rate limits, regional availability, and SLA terms opaque to most developers, with no committed general-availability date.
- Undisclosed specs. Active and total parameter counts are public only for Thinking-1 (~35B active / ~1T total, 256K context) and Code-1-Flash (~5B active) . Context-window, function-calling, and throughput details for MAI-Image-2.5, MAI-Transcribe-1.5, and MAI-Voice-2 are absent from launch documentation.
- Unauditable provenance. The "trained from scratch, no distillation, no open-weight fine-tuning" claim has no external methodology paper and cannot be verified by a third party today.
The takeaway (결): treat MAI as a credible platform bet, not a today-decision for production. If your case is the licensed-data lineage story, request private-preview access and a written quote now — but hold capacity commitments until Microsoft publishes per-token pricing, firm GA dates, and the missing model cards. Until then, the verifiable surface is narrow: Code-1-Flash in your IDE and Image-2.5 in Foundry. Everything else is a roadmap.
Frequently asked questions
What is MAI-Thinking-1?
MAI-Thinking-1 is Microsoft's first in-house flagship reasoning model, introduced at Build 2026 on June 2, 2026 . It is a sparse mixture-of-experts model with about 35B active parameters and roughly 1T total parameters, a 256K-token context window, function calling, developer instructions, and Chat Completions API compatibility . Microsoft's technical report says its MAI-Base-1 base model was pre-trained from scratch on 30T pre-training tokens plus 3.55T mid-training tokens, with a July 2025 training cutoff . As of June 2026 it is in Azure/Microsoft Foundry private preview — not publicly available.
Is MAI-Code-1-Flash available in VS Code right now?
Yes. MAI-Code-1-Flash, a 5B-active-parameter agentic coding model, began rolling out to GitHub Copilot individual users in VS Code on June 2, 2026 through the model picker and default Auto routing . No opt-in is required — it becomes the default Auto route for everyday completions. Microsoft's keynote footnote specified the rollout starting with roughly 10% of individual users , so coverage is staged rather than universal on day one.
What does Microsoft's 'trained from scratch, no distillation' claim mean for enterprise?
It means Microsoft asserts a clean commercial data lineage: the MAI models are pre-trained on public and acquired sources with no distillation from rival labs' outputs and no fine-tuning of open-source base models . The technical report adds that no synthetic data generated by language models was used during pre-training . For enterprises, this is relevant to IP indemnification and data-provenance requirements. The caveat: the claim is not independently auditable from outside Microsoft as of publication, so treat it as a vendor assertion rather than a verified fact.
Are MAI-Thinking-1's benchmark scores independently verified?
No. Every published figure — including 97.0% on AIME 2025, 52.8% on SWE-Bench Pro, and 73.5% on SWE-bench Verified — comes from Microsoft's own technical report or early press coverage, not neutral replication . Microsoft positions the 52.8% SWE-Bench Pro result as near Claude Opus 4.6's 53.4%, but Sonnet 4.6 and Opus 4.6 still lead on several other listed measures . No third-party leaderboard has corroborated these scores yet, so treat them as vendor-reported until an independent evaluation appears.
When will MAI-Thinking-1 be generally available, and what will it cost?
Microsoft has disclosed no general-availability date and no public pricing for MAI-Thinking-1. As of June 2026 it is in private preview via Azure/Microsoft Foundry, with public preview on MAI Playground described as coming soon . The model card states only that pricing depends on deployment type and token volume — no concrete per-token price is published . Firm SLAs, regional availability, and rate limits remain unannounced, so GA timing should be treated as an open question.






