
The pitch behind SubQ is simple enough to fit in one sentence: stop chunking and retrieving, and just load the whole codebase into a single context window. The architecture that supposedly makes that affordable, and the evidence that does and doesn't back it up, is where the interesting part starts.
What subquadratic attention does (and where the evidence stops)
SubQ is a long-context language model from the startup Subquadratic, unveiled on May 5, 2026, whose defining claim is a fully subquadratic, sparse-attention design where compute grows roughly linearly with context length instead of quadratically . Standard transformer attention computes every pairwise dot-product across tokens (O(n²)). SubQ replaces that with selective connections, the architectural departure that, in theory, lets a full document set or repository fit in one pass.
The performance figures are aggressive and all trace to Subquadratic's own launch post: sparse attention "52× faster than FlashAttention" with "63% less compute," and throughput around 150 tokens/sec, none independently reproduced . Vendor-published benchmarks show RULER 128K recall near 95.6% (versus Claude Opus ~94.8%) and MRCR v2 at 1M tokens around 65.9% (versus ~32.2% for Opus), with strong long-context retrieval but middling coding relative to frontier models .
"We load an entire codebase, document set or history into one context window in a single pass," is the company's stated pitch. Subquadratic is led by CEO Justin Dangel and CTO Alex Whedon (source: Introducing SubQ).
One caveat to carry into setup: the callable model ships as 'subq-preview', and although the marketed ceiling is 12M tokens, every published eval stops at 1M. The gap is unexplained and the full model card is "coming soon" .
Wire SubQ in: URL, bearer header, and a runnable example
SubQ ships as an OpenAI-compatible REST API, so wiring it in means changing two values (the base URL and the key), not your request code. The base URL is https://api.subq.ai/v1, authentication is a standard bearer token read from a SUBQ_API_KEY environment variable, and you call POST /v1/chat/completions against the model identifier subq-preview . Existing Chat Completions code runs unchanged; the role/content message schema, the stream parameter, and tool/function calling all follow the OpenAI spec with no modifications .
Prerequisites. Three things before you start:
- An early-access invitation from subq.ai, as the model is in private beta and requires an issued API key first.
- Python 3.9+ (or any HTTP-capable environment).
- The
openaipackage ≥1.0, orhttpxif you prefer raw requests.
Step 1: Set the key. No custom header format; it is the ordinary bearer pattern.
export SUBQ_API_KEY=<your_key>Step 2: Point an OpenAI client at the SubQ base URL.
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.subq.ai/v1",
api_key=os.environ["SUBQ_API_KEY"],
)Step 3: Issue a chat completion. The messages array is identical to the OpenAI schema.
resp = client.chat.completions.create(
model="subq-preview",
messages=[
{"role": "system", "content": "You are a code reviewer."},
{"role": "user", "content": "Summarize the architecture of this repo."},
],
)
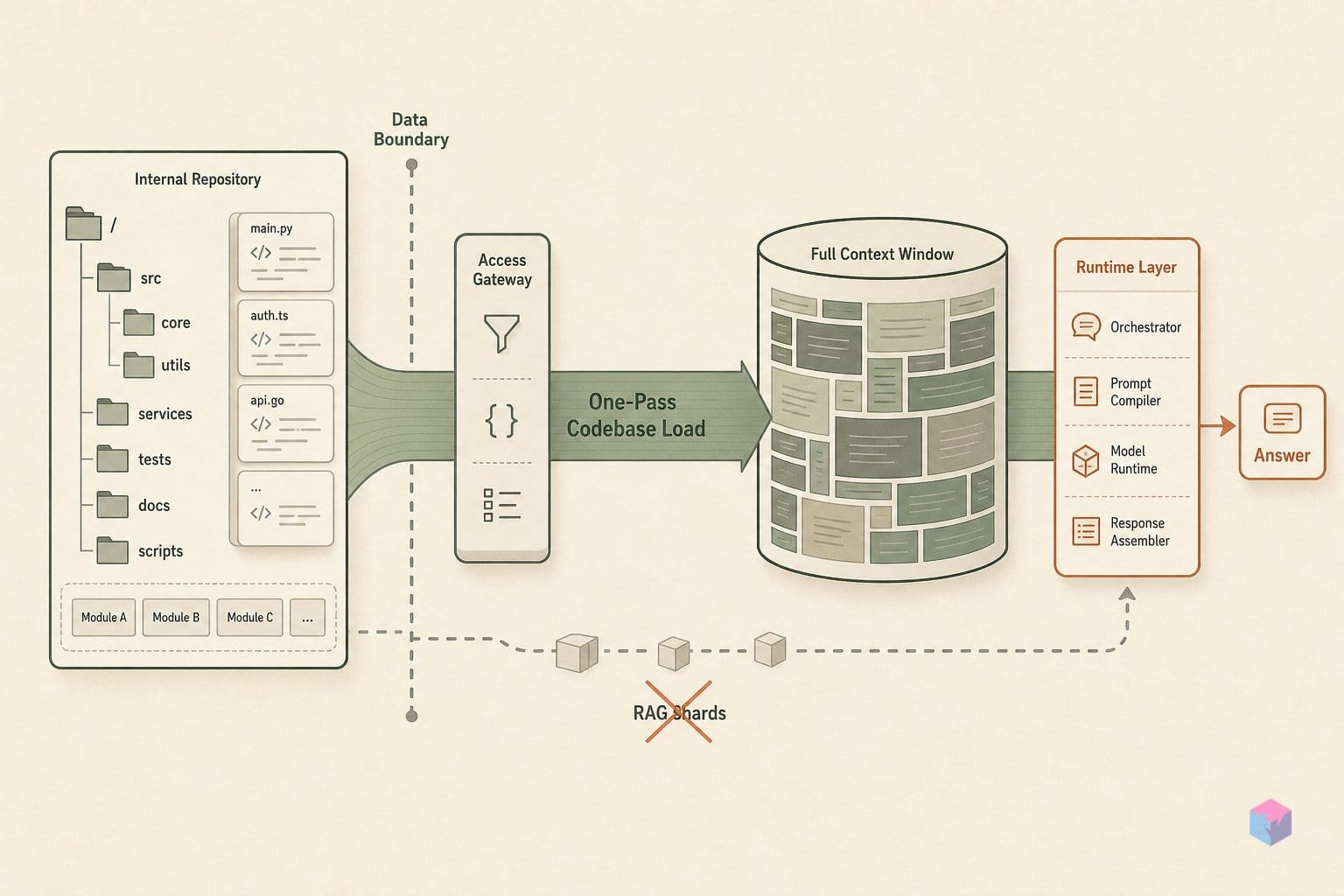
print(resp.choices[0].message.content)Step 4: For very large inputs, skip the retrieval stack. Paste the entire document or codebase directly into the user message with no chunking or retrieval pipeline, which is the single-pass approach Subquadratic pitches . Keep in mind the callable preview is benchmarked only to 1M tokens despite the marketed 12M ceiling.
Optional: streaming and tools. Add stream=True for SSE token streaming; function calling uses the unmodified OpenAI tools schema.
stream = client.chat.completions.create(
model="subq-preview",
messages=[{"role": "user", "content": "Explain main.py line by line."}],
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta.content
if delta:
print(delta, end="")| Setting | Value |
|---|---|
| Base URL | https://api.subq.ai/v1 |
| Auth | Bearer token from SUBQ_API_KEY |
| Endpoint | POST /v1/chat/completions |
| Model ID | subq-preview |
| Streaming | stream=True (SSE) |
The unknowns: no rates, no GA date, no independent replication
Before you wire subq-preview into anything billable, know what is missing. SubQ ships no per-token pricing anywhere in its developer docs. The cost pitch is comparative only: Subquadratic frames the model as roughly 1/5 to 1/20 the price of frontier long-context LLMs, but with no dollar figure attached, that ratio is unverifiable today. You cannot model spend, set budgets, or compare against GPT-5.5 or Claude Opus on real workloads.
Access is gated. As of June 2026 there is no announced general-availability date; the model runs in private beta and the "apply for early access" form is the only entry point . No SLA, no published rate limits, no migration timeline.
The benchmark story needs the same skepticism. Every figure, including RULER 128K at ~95.6% and MRCR v2 at 1M near 65.9%, traces back to Subquadratic's own May 5, 2026 announcement or to secondary coverage that repeats it . Independent reproductions were unavailable at launch, and secondary sources note an unexplained gap between lab and production recall.
"Until a third party re-runs these evals on the public endpoint, treat the published numbers as upper bounds, not guarantees." (Synthesis of independent coverage; source: DataCamp, 2026-05)
Kick the tires: whole-repo ingestion, needle-in-haystack, streaming
Before wiring SubQ into anything you ship, run it against your own content. Two companion products handle the heavy-input cases. SubQ Code is a CLI coding agent that installs separately and loads an entire repository into one context window in a single pass , useful for cross-file refactoring and dependency tracing without manually concatenating files. SubQ Search is the long-context research counterpart: feed it large PDF or markdown corpora directly instead of building a chunked embedding pipeline .
The fastest validation is a needle-in-haystack test at 500K+ tokens against your actual content type. Recall on RULER 128K (~95%) and MRCR v2 at 1M (~65.9%) says little about how SubQ handles your codebase or document mix, so confirm it holds before committing to a production integration.
Two integration checks finish the dry run: set stream=True for any output exceeding ~4K tokens, and exercise tool-calling with a minimal schema to confirm the function-call round-trip works . The takeaway: treat the public endpoint as a private-beta tool to benchmark on your data, not a drop-in retrieval replacement yet.
Frequently asked questions
What is the base URL for the SubQ API?
The base URL is https://api.subq.ai/v1 . Drop it into the OpenAI SDK's base_url parameter and authenticate with your key in the SUBQ_API_KEY environment variable, passed as a standard bearer token. No custom headers are required. The endpoint follows the OpenAI Chat Completions contract, so the SDK handles authorization for you.
Which model string do I pass to get the subquadratic model?
Pass subq-preview in the model field . Some docs also list subq-1m-preview as an alias; both resolve to the same early-access checkpoint, with published benchmarks tested only up to 1M tokens . There is no separate GA model identifier yet.
Is SubQ's 12M-token context window validated?
No. As of June 2026 every published evaluation stops at 1M tokens, and the 12M-token figure is vendor-stated only . No third-party benchmark has confirmed it, the full model card is still listed as "coming soon," and independent reproductions were unavailable, with most numbers tracing to Subquadratic's own May 5, 2026 announcement .
How is SubQ Code different from calling the REST endpoint directly?
SubQ Code is a CLI coding agent that auto-ingests an entire local repository into one context pass, handling file discovery and concatenation for you . The REST endpoint does no ingestion. You assemble and submit the content yourself. If your goal is whole-repo reasoning without writing a file-walker, SubQ Code is the shortcut; if you need programmatic control over what enters the context window, call /v1/chat/completions directly.
Do I need to rewrite my existing OpenAI SDK integration to use SubQ?
No. Change base_url to https://api.subq.ai/v1, swap the API key env var to SUBQ_API_KEY, and set model='subq-preview' . Standard chat completions, streaming via the stream parameter, and tool/function calling all work without further modification, since the API is OpenAI-compatible .








