
AMD MI300X는 오래전부터 기본 ROCm 스택이 노출하는 수준 이상의 단일 요청 추론 여유 공간을 갖추고 있었습니다. 파리의 한 스타트업이 그 실제 규모를 보여줬습니다 — 토큰별 커널 실행을 완전히 제거하는 방식으로요.
모노커널이 커널 실행 오버헤드를 없애는 방법
모노커널은 단일하고 지속적으로 GPU에 상주하는 프로그램으로, 프리필·디코드·LM 헤드 샘플링·EOS 종료 확인까지 LLM 디코드 전 과정을 호스트 CPU로 돌아가거나 토큰마다 새 커널을 실행하지 않고 처리합니다. Kog AI는 하나의 8× MI300X 노드에서 배치 크기 1, FP16 2B 모델 기준으로 요청당 3,000+ 출력 토큰/초를 기록했으며 , 이는 2026년 5월 28일 출시된 Kog 추론 엔진 기술 프리뷰의 핵심입니다. 배치 1 디코딩은 연산이 아닌 HBM 대역폭에 의해 병목이 생기기 때문에, 커널 사이의 유휴 시간이 성능을 지배한다는 점에서 이 수치는 중요한 의미를 갖습니다.
핵심 요약: 표준 MI300X 스택은 토큰마다 GPU 커널을 한 번씩 실행하며, 실행마다 약 4.5 μs의 실행 오버헤드와 HBM 재시작 레이턴시가 발생합니다. Kog의 모노커널은 전체 디코드 루프를 CPU 개입 없이 하나의 지속 커널로 압축해, 8× MI300X 노드에서 요청당 3,000+ 토큰/초를 달성합니다 (FP16 2B 모델, 배치 1).
vLLM·SGLang·ROCm/HIP 파이프라인 등 기존 스택은 모든 토큰의 모든 단계마다 새 커널을 실행합니다. Kog는 이로 인해 반복적으로 발생하는 비용을 다음과 같이 정량화합니다 :
| 오버헤드 원인 | 발생당 비용 |
|---|---|
| 커널 실행 (단계별) | ~4.5 μs |
| 메모리 로드 재시작 시 HBM 레이턴시 | ~0.5 μs |
| 중간 텐서 HBM 왕복 구체화 | >1 μs |
동기화 방식도 이에 맞게 재설계됐습니다. 원자적 도착 카운터 대신 버퍼를 NaN으로 초기화하고 소비자가 실제 데이터가 나타날 때까지 폴링하는 센티넬 값 폴링 방식을 채택해, 동기화 레이턴시를 약 7.8 μs에서 약 0.9 μs로 줄였습니다. 다만 동기화가 여전히 토큰 생성 시간의 약 35%를 차지합니다 . 최고 수치는 얼마나 신뢰할 수 있을까요? HBM 다이 인접성을 기준으로 연산 유닛을 묶은 토폴로지 최적화 변형에서 3,300 토큰/초가 인용되지만, 이 수치는 1차 블로그(3,000+ 기재)가 아닌 2차 보고서 출처입니다 . 아직 독립적인 벤치마크가 없는 단일 벤더의 자체 보고 데이터이므로 정확한 최고치는 신중하게 받아들이시기 바랍니다.
KIE 플레이그라운드와 순수 HIP, 무엇을 선택할까
오늘날 Kog의 작업을 직접 체험할 수 있는 방법은 정확히 두 가지이며, 두 방법은 노력의 스펙트럼 양 끝에 위치합니다. 호스팅된 Kog 추론 엔진(KIE) 플레이그라운드는 별도 설치 없이 브라우저에서 바로 사용할 수 있는 데모이고, 순수 HIP 재현은 연구 수준의 작업입니다. 대부분의 개발자에게는 플레이그라운드만이 즉시 활용할 수 있는 선택지이며, HIP 경로는 주말에 뚝딱 해낼 수 있는 프로젝트가 아닙니다.
playground.kog.ai의 플레이그라운드는 HumanEval에서 약 50%를 기록하는 Laneformer 2B 코딩 모델을 Kog 자체 8× MI300X 클러스터에서 실행합니다 . 별도 하드웨어 없이 브라우저에서 직접 모델과 상호작용하며 요청별 토큰 속도를 실시간으로 확인할 수 있습니다. 자신의 프롬프트로 레이턴시 주장을 직접 검증하는 가장 빠른 방법입니다.
HIP 재현 경로는 완전히 다른 차원의 작업입니다. 모노커널을 재현하려면 AMD Instinct GPU, ROCm 6.x 스택, 그리고 깊은 HIP/어셈블리 경험이 필요합니다 — 실제 구현에는 3-dword 타입 원자 연산을 위한 수작업 인라인 어셈블리, 수동 레지스터 압력 관리(LICM, 명령어 검사), HSA API로 동기화된 커스텀 크로스 GPU 타임스탬프 프로파일링 하네스가 요구됐습니다 .
결정적으로, 2026년 6월 현재 오픈소스 커널도, pip 패키지도 존재하지 않습니다 . Kog 엔지니어링 블로그가 유일한 공개 구현 참고 자료이며, 클론 가능한 레포지토리가 아닌 상세한 기술 문서입니다. 이 기법을 원한다면 글을 읽고 직접 재구현해야 합니다.
직접 해보기: KIE 플레이그라운드에서 HIP 복제까지
먼저 플레이그라운드에서 시작하고, 기법 자체가 필요할 때만 HIP로 넘어가세요. 별도 설치 없이 바로 쓸 수 있는 경로는 playground.kog.ai입니다. 페이지를 열고 코딩 프롬프트를 제출하면 응답 UI에서 요청당 토큰 카운터를 실시간으로 확인할 수 있습니다. 백엔드 모델은 Kog의 8× MI300X 노드에서 FP16으로 구동되는 Laneformer 2B로, HumanEval 기준 약 50% 성능을 기록하며, 2026년 5월 28일 출시된 기술 프리뷰에서는 로그인 없이 이용 가능합니다 . 이 페이지 하나만으로도 직접 작성한 프롬프트로 지연 시간 주장을 검증하기에 충분합니다.
기법을 직접 복제하려면 Kog 엔지니어링 글을 먼저 읽어보세요. 컴파일 타임 작업 분할, gridDim=(256,)·blockDim=(64,8)로 구성된 256 컴퓨트 유닛 그리드, 칩릿 설계의 크로스 다이 리덕션 패널티를 피하기 위한 I/O 다이별 텐서 복제 방식이 상세히 설명되어 있습니다 . 전체 루프를 시도하기 전에 반드시 이해해야 할 구현 세부 사항이 두 가지 있습니다:
- GEMM이 아닌 GEMV. 배치 크기 1에서 벡터-행렬 곱셈은 GEMV이므로, 모노커널은 행렬 코어 대신 스칼라/벡터 ALU
dot2명령어를 사용합니다 — 텐서 코어는 배치 크기가 타일을 가득 채울 때야 비로소 효율이 생깁니다 . 먼저 본인의 가중치 형태에 맞게 이 부분부터 복제하세요. - 지연 텐서 병렬화(DTP). 어텐션과 FFN의 TP 리덕션을 뒤로 미뤄 이후 레이어에 접어 넣습니다. 덕분에 Infinity Fabric을 통한 크로스 GPU 트래픽이 비동기로 처리되어 연산 뒤에 숨겨집니다. 이것이 동기식 통신 장벽 없이 8-GPU 레인 분할을 가능하게 하는 핵심입니다 .
"모노커널은 샘플링과 EOS 종료 검사까지 포함한 전체 디코드 루프를 하나의 영속 커널로 압축합니다. 덕분에 호스트 CPU가 이 경로에 다시 진입하는 일이 없습니다." — Kog 엔지니어링 팀 (source: Kog AI blog).
직접 작성한 HIP와 인라인 어셈블리까지 관리하기 부담스럽다면, AMD의 AITER(ROCm용 AI 텐서 엔진)에서 한 단계 위부터 시작하세요 — Triton, Composable Kernel, HIP, 수작업 튜닝 어셈블리 백엔드가 vLLM 및 SGLang에 이미 연결된 공식 레퍼런스입니다 . "Kog가 응답하는지" 최소한으로 확인하는 예시 코드는 아래와 같습니다 — 여기서 직접 실행하지는 않으며(Kog 런타임/CLI가 필요), 해당 의존성이 없으면 깔끔하게 종료됩니다:
import importlib.util
import shutil
import subprocess
import sys
if not shutil.which("kog") and importlib.util.find_spec("kog") is None:
raise SystemExit("needs dependency: kog runtime/CLI")
cmd = ["kog", "bench", "--device", "mi300x", "--target-tps", "3000", "--no-kernel-switches"]
print("+", " ".join(cmd))
out = subprocess.check_output(cmd, text=True, stderr=subprocess.STDOUT)
print(out)3K t/s 수치가 말해주지 않는 것들
헤드라인 수치는 매우 좁은 구성을 전제합니다. 단일 8× MI300X 노드에서 FP16·배치 크기 1로 구동되는 커스텀 2B 파라미터 "Laneformer" 모델의 결과입니다 . 2026년 6월 현재, 이 모노커널이 더 큰 밀집 모델이나 MoE 아키텍처, FP8 등 양자화 정밀도, 배치 크기 1 초과, 멀티 노드 환경에서도 일반화된다는 공개 근거는 없습니다 — AI Weekly 요약도 이 항목들을 미검증 사항으로 명시합니다 .
결과는 전적으로 자체 보고된 수치입니다. 독립적인 제3자 벤치마크는 아직 등장하지 않았으며, 널리 유통되는 3,300 t/s 수치는 Kog의 기본 블로그(3,000+ 명시)가 아니라, AI Weekly가 2026년 5월 29일 토폴로지 튜닝 변형을 다룬 글에서 비롯된 것입니다 . Kog 외부에서 재현이 이루어지기 전까지는 정확한 피크 수치를 신중하게 받아들이세요.
크로스 벤더 비교에도 같은 주의가 필요합니다. Kog는 동일한 FP16·배치 크기 1 조건에서 형제 모노커널이 8× NVIDIA H200으로 약 2,100 t/s에 도달했다고 보고합니다 — 이 역시 자체 보고이며 외부 검증은 없습니다.
마지막으로, 개발자들이 원하는 여러 기능은 출시된 것이 아니라 로드맵 항목입니다. Kog는 서드파티 MoE 모델 지원, FP8 등 양자화, 투기적 디코딩, 더 큰 배치 크기를 계획 중이나 아직 제공되지 않는다고 명시합니다 .
칩렛 구조 심층 분석과 앞으로의 전망
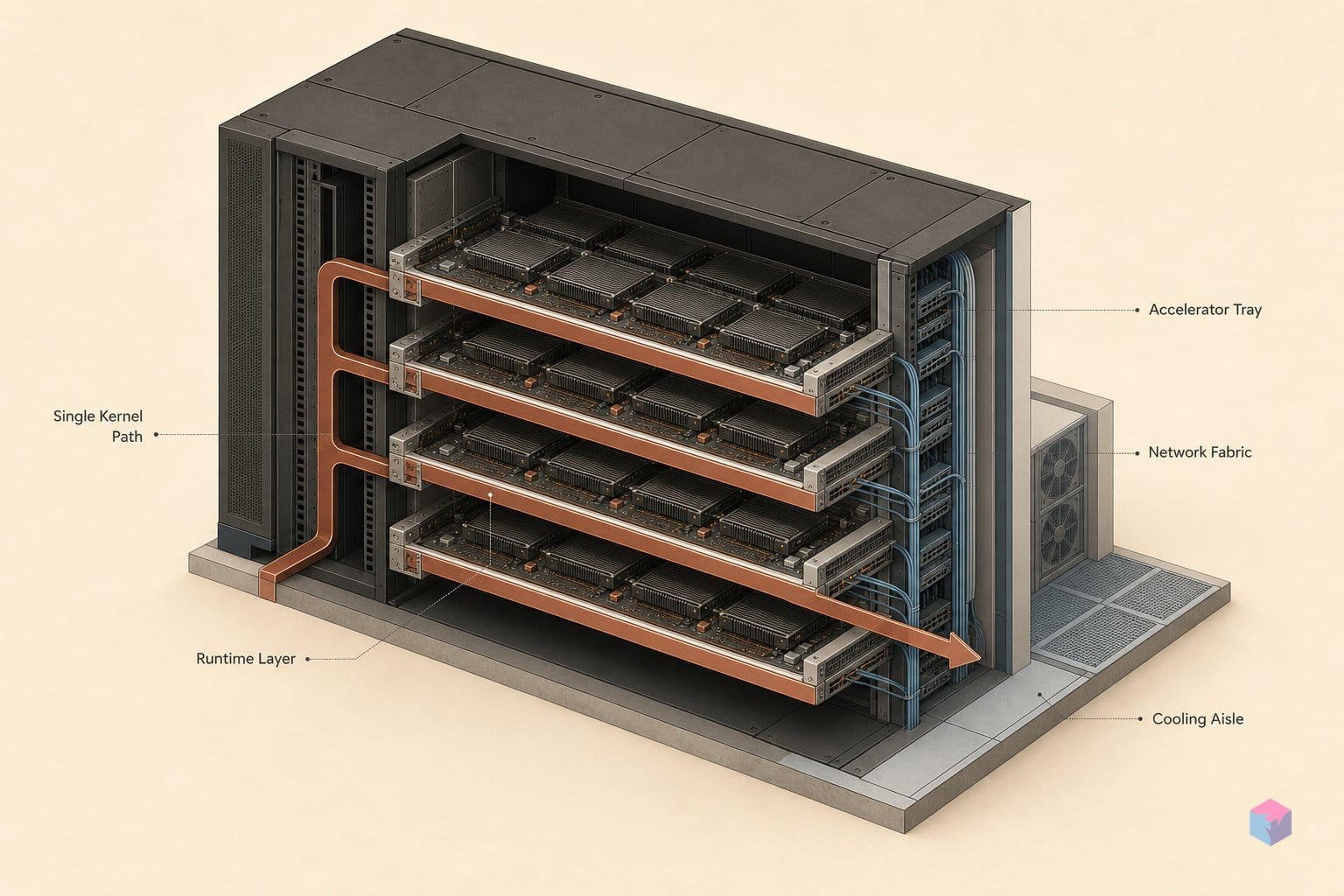
토폴로지 튜닝이 왜 중요한지 이해하려면 다이 맵을 살펴봐야 합니다. MI300X는 CDNA3 칩렛 설계로, 4개의 I/O 다이(IOD) 위에 총 304개(XCD당 38개)의 컴퓨트 유닛을 보유한 8개의 가속기 컴퓨트 다이(XCD)가 올려져 있으며, 192GB HBM3로 최대 약 5.3 TB/s 대역폭을 제공합니다 . Kog의 모노커널은 의도적으로 304개 CU 중 256개만 사용하고 IOD별로 텐서를 복제하는데, 이는 약간의 메모리를 희생하는 대신 단일 요청 디코드를 지연시킬 수 있는 다이 간 all-reduce 페널티를 피하기 위한 선택입니다 .
Kog 수준의 리소스 없이 MI300X 어텐션 커널을 시작하고 싶다면, ROCm AI Developer Hub의 AMD AITER MLA 디코드 튜토리얼이 가장 진입 장벽이 낮은 출발점입니다. Ubuntu 22.04와 ROCm 6.3.1을 대상으로 하며, /dev/kfd와 /dev/dri를 노출한 Docker 컨테이너에서 실행되고, AITER를 재귀적으로 클론하고 python3 setup.py develop를 실행한 후 mla_decode_fwd를 직접 호출하는 과정을 안내합니다 .
Kog 자체에 관해서는, KIE 기술 미리보기 포스트에서 서드파티 MoE 모델, 추가 배치 크기, 양자화, 투기적 디코딩을 예정 항목으로 나열하고 있으나 구체적인 일정은 없습니다 . 핵심 요점: 3K t/s 수치는 단일 요청·단일 모델의 개념 증명이지 일반 벤치마크가 아닙니다 — 지금 바로 플레이그라운드를 체험해 보고, 로드맵은 blog.kog.ai에서 확인하며, 지금 당장 재현 가능한 커널 경로가 필요하다면 AITER를 선택하세요.
자주 묻는 질문
Kog 추론 엔진을 사용해 보려면 AMD MI300X가 필요한가요?
아니요. KIE 기술 미리보기는 playground.kog.ai에서 호스팅되는 브라우저 플레이그라운드로, Kog의 자체 8× MI300X 클러스터에서 Laneformer 2B 코딩 모델을 실행합니다 . 브라우저를 통해 상호작용하며 요청별 토큰 속도를 직접 확인할 수 있습니다 — 로컬 GPU, 드라이버, 별도 설정이 전혀 필요 없습니다. 엔지니어링 문서를 참고해 HIP으로 모노커널을 직접 재현하고 싶을 때만 MI300X가 필요합니다.
모노커널이 텐서 코어를 건너뛰고 스칼라/벡터 ALU를 사용하는 이유는 무엇인가요?
배치 크기 1에서 디코드는 GEMM이 아닌 GEMV(행렬-벡터 곱셈)이므로 행렬 코어가 유휴 상태에 머뭅니다. 텐서/행렬 코어 기본 연산은 배치가 타일을 채울 만큼 충분히 클 때만 효과적이며, 단일 벡터 곱셈으로는 그럴 수 없습니다. 따라서 Kog는 스칼라/벡터 ALU의 dot2 명령어로 프로젝션을 구현하는데, 이는 컴퓨팅이 아닌 HBM 대역폭이 병목이 되는 배치-1 디코드에서 더 빠릅니다 .
Delayed Tensor Parallelism이란 무엇이며 여기서 왜 중요한가요?
Delayed Tensor Parallelism(DTP)은 어텐션과 FFN에서의 텐서 병렬 all-reduce를 뒤로 미루고 이후 레이어 연산에 통합함으로써, Infinity Fabric을 통한 GPU 간 트래픽을 산술 연산 뒤에 숨겨 비동기적으로 실행합니다 . 이를 통해 모델이 8개 GPU에 걸쳐 8개 레인으로 분할되고 레이어마다 블로킹 리덕션이 지연 시간을 지배하게 되는, 배치 1에서의 8-GPU 텐서 병렬 처리가 겪는 동기적 통신 지연을 피할 수 있습니다.
AMD의 AITER는 Kog가 구축한 것과 어떻게 다른가요?
AITER(AI Tensor Engine for ROCm)는 Triton, Composable Kernel, HIP, 수동 튜닝 어셈블리 백엔드를 갖춘 프레임워크 수준의 연산자 라이브러리로, 이미 vLLM과 SGLang 프로덕션 서빙 경로에 통합되어 있습니다 . Kog의 모노커널은 정반대입니다: 프레임워크 추상화 없이 HIP과 인라인 어셈블리로 작성된, 컴파일 타임에 작업이 분할된 수작업 단일 커널입니다. 더 저수준이고 오픈소스가 아니며 커스텀 2B 모델에서만 시연되었습니다 — 지금 당장 커널이 필요하다면 AITER가 재현 가능한 경로입니다 .
3,300 토큰/초 수치는 Kog 블로그에서 나온 것인가요?
아니요. Kog 엔지니어링 블로그는 단일 8× MI300X 노드에서 배치 크기 1의 FP16 2B 모델에 대해 요청당 초당 3,000개 이상의 출력 토큰을 명시합니다 . 3,300이라는 수치는 2026년 5월 29일 AI Weekly 요약에서 토폴로지 튜닝 변형을 설명하며 등장했습니다 . 2026년 6월 현재 독립적인 재현이 없으므로, 3,000+를 주된 수치로 봐야 합니다.








