오늘 "SkillsGuard"를 검색하면 같은 이름을 단 것이 최소 네 가지는 나옵니다. 그중 하나는 멀웨어를 배포했다는 이유로 레지스트리에서 내려갔습니다. Agent Skills를 보호해 준다고 하는 무언가를 설치하기 전에, npm install에 정확히 어떤 패키지 이름을 입력하는지부터 확인해야 합니다.
'SkillsGuard'라는 이름의 혼선을 정리하면
"SkillsGuard"는 하나의 제품이 아닙니다. Agent Skills가 실행되기 전과 실행 중에 이를 보호한다는 같은 문제를 겨냥한, 최소 네 가지 서로 다른 시도가 이름에서 충돌한 결과입니다. 실제 코드가 배포되는지, 누가 배포하는지, 감사할 수 있는지까지 핵심 요소가 모두 다릅니다. 아래 표에서 구분해 보겠습니다.
빠른 답변: 네 개 프로젝트가 "SkillsGuard"라는 이름을 공유합니다. 이 중 GoPlus Security의 AgentGuard만 검증 가능하고 설치 가능한 런타임 가드입니다. 공개 GitHub 저장소가 있고, MIT 라이선스이며, v1.1.28 버전입니다 . "SkillGuard"라는 이름의 스캐너 하나는 악성으로 표시되어 ClawHub에서 제거됐으므로, 어떤 것을 설치하든 먼저 게시자를 확인해야 합니다.
| 이름 | 정체 | 상태 |
|---|---|---|
| SkillGuard (paper) | arXiv:2606.03024, 권한 프레임워크 | 설계안뿐이며 배포된 산출물은 없음 |
| AgentGuard (GoPlus Security) | 런타임 가드, npm, MIT | v1.1.28, 활발히 유지보수 중 |
| @yangyixxxx/skill-guard | npm 패키지 (skillguard.vip) | 서드파티 |
| skills-guard | SkillsHub 레지스트리에 포함된 엔진 | 레지스트리 내장형 |
위험은 현실적입니다. c-goro라는 사용자의 "SkillGuard"라는 도구는 악성으로 표시되어 ClawHub에서 내려갔습니다. 스캐너 자체가 공격이었던 셈입니다. Snyk에 따르면 마켓플레이스 스킬의 13% 이상에 치명적 취약점이 포함되어 있습니다 . 따라서 다른 스킬을 감사하겠다고 믿고 맡기는 도구는 그 자체로 감사 가능하고 오픈소스여야 합니다.
현재 권장 경로는 GoPlus Security의 AgentGuard입니다. 공개 GitHub 저장소가 있고, MIT 라이선스이며, v1.1.28 기준 문서가 충분히 갖춰져 있습니다 . arXiv의 SkillGuard 논문은 구현 설계안으로 읽어볼 가치가 있지만, 아직 설치 가능한 산출물은 없습니다 .
시작 전에 준비할 것
AgentGuard는 전역 npm 패키지로 설치되므로 준비는 가볍습니다. 필요한 것은 Node.js 18 이상과 npm입니다. Python 인터프리터나 별도 런타임을 관리할 필요는 없습니다. 전체 스캐너가 npm을 통해 v1.1.28로 배포되며 , 라이선스는 MIT입니다.
다음으로 호환되는 에이전트형 호스트를 준비합니다. AgentGuard는 자동 훅 레이어를 포함해 Claude Code와 OpenClaw를 완전히 지원합니다. Codex, Gemini, Cursor, Copilot은 skill-only 모드로 지원되며, 이 모드에서는 에이전트의 실시간 도구 호출 루프에 연결하지 않고 스킬 디렉터리를 스캔합니다 .
그리고 스캔할 대상도 필요합니다. 명령을 실행하기 전에 아래를 준비하세요.
- Node.js ≥18 + npm — 유일한 런타임 의존성입니다.
node -v로 확인하세요. - 에이전트형 호스트 — 전체 훅을 쓰려면 Claude Code 또는 OpenClaw, skill-only 스캔에는 Codex/Gemini/Cursor/Copilot을 사용합니다.
- 최소 하나의 Agent Skill 디렉터리 —
SKILL.md와 함께 포함된 스크립트나 자산이 들어 있는 폴더입니다. - 선택: 도구 호출 JSON 페이로드 — 전체 스킬이 아니라 단일 동작만 평가하고 싶을 때
agentguard protect에 파이프로 넘길 수 있습니다.
빠른 시작: 초기화, 스캔, 보호
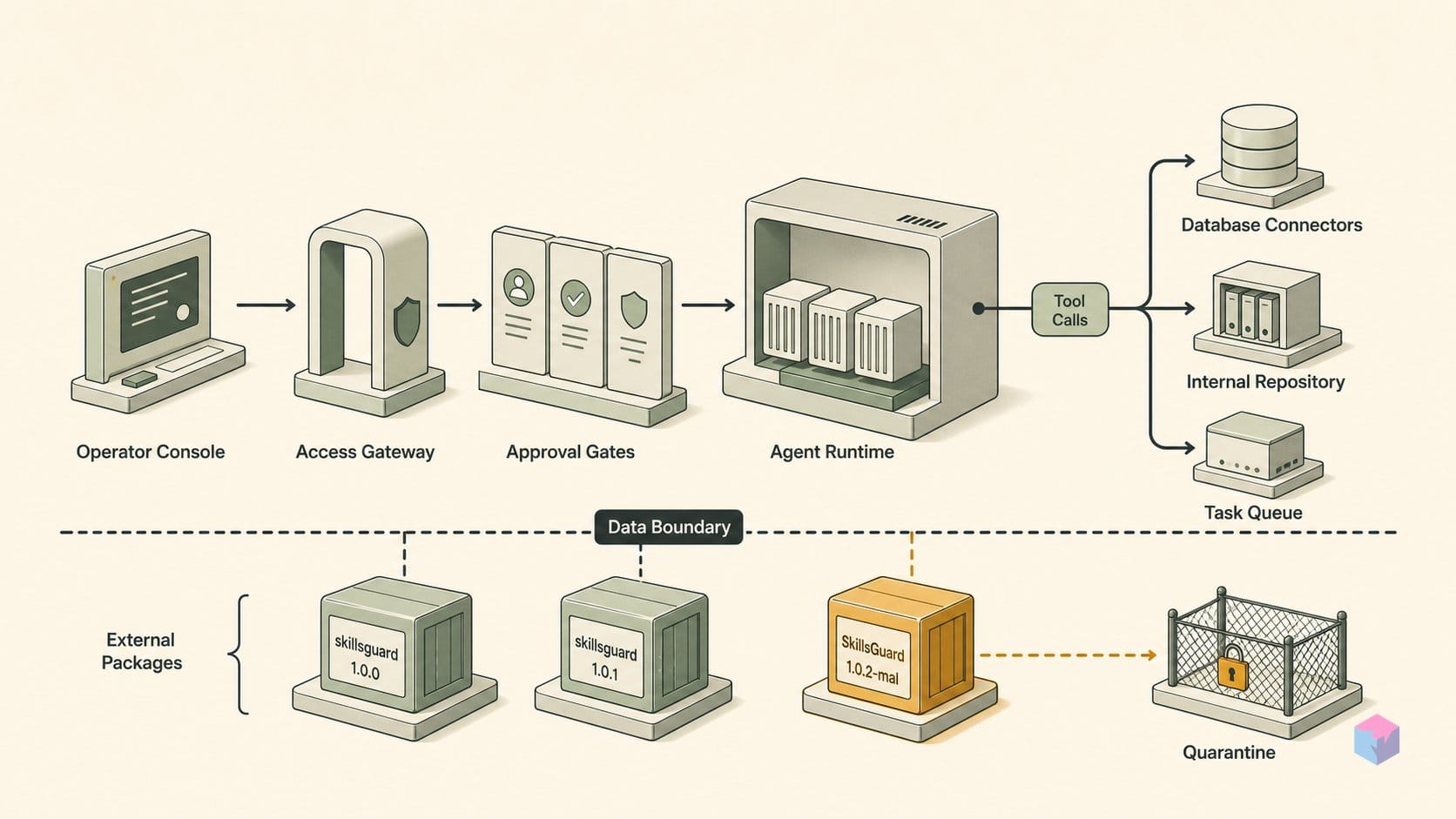
Node와 스킬 디렉터리가 준비되어 있으면 AgentGuard는 세 가지 명령만으로 설치 상태에서 활성 런타임 가드로 전환됩니다. 전역으로 설치하고, 에이전트 호스트에 맞춰 훅을 초기화한 다음, 스킬 폴더를 스캔하거나 단일 도구 호출을 평가하면 됩니다. GoPlus Security의 AgentGuard는 GitHub에서 v1.1.28 기준으로 검증되어 있으며 , MIT 라이선스이고, "SkillsGuard"라는 이름을 공유하는 패키지들 중 설치 가능한 선택지로서 가장 검증하기 쉽습니다.
먼저 전역으로 설치하고, 더 진행하기 전에 바이너리가 정상적으로 잡히는지 확인합니다.
npm install -g @goplus/agentguard
agentguard --version # expect 1.1.28+다음으로 Layer 1을 연결합니다. --agent auto 플래그는 Claude Code 또는 OpenClaw를 자동 감지하고, 파괴적인 명령과 .env 및 .ssh/ 쓰기를 차단하는 훅을 설치하며, 웹훅 기반 유출 탐지도 함께 설정합니다 :
agentguard init --agent auto
agentguard status # active hook count + webhook monitoring state계속하기 전에 agentguard status를 실행하세요. 활성화된 훅 수와 유출 모니터링이 준비되었는지 확인해 줍니다. 훅이 0개라면 정상 상태가 아니라 초기화 실패로 봐야 합니다.
스킬을 감사하려면 온디맨드 딥 스캔 대상에 해당 폴더를 지정합니다. Layer 2는 Execution(SHELL_EXEC, REMOTE_LOADER), Secrets(READ_ENV_SECRETS, PRIVATE_KEY_PATTERN), Exfiltration(NET_EXFIL_UNRESTRICTED, WEBHOOK_EXFIL), Obfuscation, 8개의 Web3 규칙, 4개의 트로이 목마/사회공학 규칙까지 포함하는 24개 탐지 규칙을 모두 실행한 뒤, 심각도 순으로 정렬된 보고서를 출력합니다 :
agentguard scan ./path/to/skill전체 스킬이 아니라 단일 작업만 확인하려면 도구 호출 JSON 페이로드를 agentguard protect로 파이프합니다. 기본 Balanced 레벨은 위험한 작업을 차단하고 리스크가 있는 작업은 확인을 요구합니다. --level strict를 추가하면 매니페스트에 명시적으로 선언되지 않은 모든 작업을 차단합니다 :
cat tool-call.json | agentguard protect --level strict왜 세 레이어를 모두 실행해야 할까요? 위협은 단순한 텍스트가 아니라 실행에서 나오기 때문입니다. Anthropic의 Skills 문서도 악성 스킬이 "data exfiltration, unauthorized system access"를 유발할 수 있다고 경고하며, 예상치 못한 네트워크 또는 파일 활동이 있는지 모든 번들 파일을 감사하라고 안내합니다 . SKILL.md만 보는 스캐너는 런타임에 실행되는 스크립트를 놓칩니다. Layer 1 훅과 Layer 2 스캔을 함께 두면 스킬이 셸에 닿기 전에 그 빈틈을 줄일 수 있습니다.
AgentGuard가 막지 못하는 영역
스캐너는 공격 표면을 좁히지만 완전히 봉인하지는 못합니다. AgentGuard는 SKILL.md와 최상위 스크립트를 24개 탐지 규칙으로 검사하지만, 현재 어떤 규칙 세트도 닫지 못하는 네 가지 빈틈이 남아 있습니다 . 이 한계를 알아야 깨끗한 스캔 결과가 안심해도 되는 신호인지, 아니면 잘못된 안도감인지 구분할 수 있습니다.
- 매니페스트 생성은 잡음이 많고 테스트 범위가 얕습니다. SkillGuard 논문의 자동 매니페스트 생성기는 깨끗한 스킬 23개만으로 평가되었고, 정밀도 85.6%, 재현율 97.1%를 기록했습니다. 하지만 23건 중 13건(56.5%)에서 최소 하나 이상의 권한을 과도하게 선언했고, 4건(17.4%)에서는 부족하게 선언했습니다 . 정상적인 스킬에서도 오탐을 예상해야 합니다.
- 번들 라이브러리 소스는 분석되지 않습니다. 가져온 의존성 내부에 악성 로직이 숨어 있으면 SKILL.md와 진입 스크립트가 깨끗해 보이는 한 스캔을 통과합니다. 이 논문도 번들 스크립트 분석 누락을 여전히 열려 있는 미탐 원인으로 지적합니다 .
- 프롬프트 인젝션 공급망 공격은 강화 이후에도 살아남습니다. SKILL.md만 이용한 공격도 여전히 최대 86%의 쌍대 발견 승률과, 스캔으로 강화된 호스트를 상대로 36.5%~100%의 거버넌스 회피율에 도달합니다 . 제안된 완화책은 읽기 전용 스킬 마운트이며, AgentGuard는 이를 제공하지 않습니다.
- 권한 검사는 의도를 읽을 수 없습니다. 합법적인 FETCH_WEB 접근 권한이 있는 스킬은 스캔을 통과한 뒤 데이터를 유출할 수 있습니다. 기능을 부여하는 것과 그 사용을 통제하는 것은 서로 다른 문제입니다.
독립적인 신호도 이 위험을 강조합니다. Snyk 연구팀은 스킬 스캐너가 왜 잘못된 보안감을 만들 수 있는지 분석하면서 "over 13% of marketplace skills contain critical vulnerabilities"라고 표현했습니다 . AgentGuard는 초기에 실패 시 닫히도록 만드는 하나의 레이어로 봐야지, 스킬이 안전하다는 증거로 보면 안 됩니다.
스캐너를 넘어: 매니페스트 사이드카
스캐너는 스킬을 한 번 판단하지만, 매니페스트는 스킬이 행동할 때마다 통제합니다. 이 차이를 메우려면 SkillGuard 논문에서 가져온 기본 거부 방식의 권한 레이어를 AgentGuard와 함께 사용하세요 . 각 스킬 옆에 skillguard-manifest.json을 두고, 모든 항목에 capability, effect(allow/confirm/deny), workspace_only, time_window, rate_limit 같은 constraints, 그리고 권한이 계속 남지 않도록 만료시키는 expires_at을 선언합니다.
{
"capability": "POST_WEB",
"effect": "confirm",
"constraints": { "workspace_only": true, "rate_limit": "5/min" },
"expires_at": "2026-07-25T00:00:00Z"
}그다음 PreToolUse 훅을 연결합니다. 각 도구 호출을 표준 capability로 매핑하고, 실행 전에 매니페스트를 평가합니다. 해당 capability가 선언되지 않았거나 위험, 시스템, 또는 redact 등급이라면 차단하거나 사용자 확인을 요구합니다. 정적 스캔은 활성화 이후 악성 형제 스킬이 SKILL.md를 변조하는 것을 막을 수 없기 때문에 이 단계가 중요합니다. 관련 연구에서 이 공격 유형은 최대 100%의 거버넌스 회피율에 도달하는 것으로 나타났습니다 . 컨테이너에서 스킬 디렉터리를 읽기 전용으로 마운트하면 이를 무력화할 수 있습니다.
마지막으로 커버리지가 스스로 갱신되게 합니다. agentguard status --schedule daily로 Layer 3을 활성화하세요 . 그러면 이후 스킬 업데이트로 새 번들 파일이나 네트워크 호출 패턴이 추가되더라도 수동 재스캔 없이 잡아낼 수 있습니다.
핵심은 이것입니다. 스킬이 무엇을 할 수 있는지 선언하고, 읽기 전용으로 마운트하고, 모든 호출을 도구 경계에서 검사하며, 매일 순찰하세요. 어떤 단일 도구도 스킬의 안전을 증명하지 못합니다. 하지만 레이어를 쌓고 실패 시 닫히는 기본값을 두면, "스캔됨"과 "신뢰됨" 사이의 간격을 막연히 가정하는 대신 직접 통제할 수 있습니다.
자주 묻는 질문
SkillsGuard는 Anthropic의 공식 제품인가요?
아니요. 2025년 10월에 발표된 Anthropic의 Agent Skills 사양 은 SKILL.md 형식을 문서화하고 데이터 유출이나 무단 시스템 접근 같은 위험을 명시적으로 경고하지만, 자체 스캐너를 함께 제공하지는 않습니다. "SkillsGuard"라는 이름은 의미가 모호하며, GoPlus Security의 AgentGuard, 학술 논문에서 설명된 연구 프레임워크, 별도로 공개된 npm 패키지 두 개처럼 Anthropic과 무관한 서드파티 작업들을 가리킵니다. 이들 중 Anthropic의 보증을 받은 것은 없으므로, 이 이름은 제품이 아니라 하나의 범주로 보는 것이 맞습니다.
agentguard scan은 실제로 무엇을 검사하나요?
여섯 개 범주에 걸친 24개 탐지 규칙으로 정적 심층 스캔을 실행합니다 . 범주는 다음과 같습니다. Execution(SHELL_EXEC, AUTO_UPDATE, REMOTE_LOADER), Secrets(READ_ENV_SECRETS, READ_SSH_KEYS, PRIVATE_KEY_PATTERN, MNEMONIC_PATTERN), Exfiltration(NET_EXFIL_UNRESTRICTED, WEBHOOK_EXFIL), Obfuscation(OBFUSCATION, PROMPT_INJECTION), WALLET_DRAINING과 UNLIMITED_APPROVAL 같은 Web3 규칙 여덟 개, 그리고 트로이목마/사회공학 규칙 네 개입니다. 이 스캔은 스킬을 실행하지 않고 파일과 패턴을 검사하므로, 런타임에 접근을 허용하거나 차단하는 대신 발견 사항을 보고합니다.
AgentGuard가 SKILL.md 안의 프롬프트 인젝션을 잡아낼 수 있나요?
부분적으로 가능합니다. AgentGuard의 PROMPT_INJECTION 규칙은 알려진 인젝션 패턴을 표시하지만, 패턴 매칭만으로 위험이 사라지는 것은 아닙니다. SkillGuard 논문의 적대적 평가는 그 한계를 가늠하게 해 줍니다. 전체 매니페스트 강제를 적용했을 때 문맥형 인젝션 성공률은 32.37%에서 23.02%로, 노골적인 인젝션은 25.56%에서 16.67%로 낮아졌습니다 . 의미 있는 감소이지만 보장은 아닙니다. 이미 부여된 권한을 악용하는 공격은 여전히 통과할 수 있으므로, 스캐너는 단독으로 두기보다 기본 차단 정책 뒤에 배치해야 합니다.
호스트 환경에서 스킬을 활성화하지 않고 스캔하려면 어떻게 하나요?
agentguard scan <skill-dir>을 실행하면 됩니다. 이 명령은 정적 분석만 수행하며 호스트 에이전트에서 스킬을 활성화하지 않습니다 . 호스트 권한을 부여하기 전에, dry-run JSON 페이로드를 agentguard protect로 파이프해 해당 스킬이 수행할 것으로 예상되는 구체적인 도구 호출을 평가하세요. 그러면 각 작업에 대해 허용, 확인 요청, 차단 중 어떤 결정이 내려지는지 개별적으로 볼 수 있고, 스킬은 파일과 예상 동작이 모두 확인된 뒤에만 호스트 접근 권한을 얻게 됩니다.
strict, balanced, permissive 보호 수준은 어떻게 다른가요?
Balanced가 기본값입니다. 위험한 기능은 차단하고, 위험 가능성이 있는 기능은 확인을 요청합니다 . Strict는 스킬 매니페스트에 명시적으로 선언되지 않은 모든 것을 차단하므로, 필요한 권한을 이미 확정한 스킬에 적합합니다. Permissive는 차단하지 않고 활동을 기록하므로, 새 스킬의 기준 동작을 잡고 실제로 무엇을 하는지 파악할 때 유용합니다. 실무에서는 Balanced로 시작하고, 매니페스트를 작성하는 동안 Permissive로 관찰한 뒤, 강제할 선언이 확인되면 Strict로 옮기는 흐름이 적절합니다.









