
For two decades, a search API meant one thing: send a query string, get back a ranked list, and let a human (or a model pretending to be one) skim the results. Perplexity's new "Search as Code" rewrites that contract — it hands the model the pipeline itself.
Search as Code: From Opaque Box to Composable Retrieval Primitives
Search as Code (SaC) is a reference architecture from Perplexity that lets an AI agent write and run its own search pipeline in code instead of calling a fixed retrieval endpoint . The shift is structural: a traditional search API is a single black-box endpoint where the model can vary only the query string, while ranking, filtering, and pagination stay opaque and tuned for human reading. SaC flips that — a frontier model decomposes the task and generates Python that assembles a bespoke pipeline from atomic, composable primitives.
Quick Answer: Search as Code is Perplexity's architecture that exposes its search backend as composable primitives — retrieve, fanout, filter, dedupe, rerank — which a model orchestrates by writing Python, rather than calling one fixed API. Perplexity reports a CVE case study where SaC hit 100% accuracy with an 85.1% token reduction.
Instead of one monolithic call, the model strings together operations like retrieve, fanout, filter, dedupe, and rerank into a task-specific program . The motivation is agent workloads, not human browsing. Perplexity reports that a single task inside its Computer product has triggered hundreds to thousands of retrieval operations within minutes — a volume that makes no sense for someone reading ten blue links but is routine for an agent running a long trajectory. The published implementation is powered by GPT-5.5 at high reasoning .
CEO Aravind Srinivas framed the bet plainly:
"Search as codegen is the future," — Aravind Srinivas, CEO at Perplexity (source: Storyboard18).
The practical payoff is context discipline. Because the model-written code executes in a sandbox, intermediate results — partial result sets, dropped duplicates, rerank scratch data — stay inside that sandbox, and only the useful final output is fed back into the model's reasoning context . That reduces context-window pollution on long sessions and cuts the round-trips a model would otherwise spend shuttling raw pages through its own prompt. It also parallels the broader agent-tooling movement — Anthropic's Model Context Protocol among them — but differs in a specific way: the model generates executable code rather than calling pre-built named tools .
Control Plane, Secure Sandbox, and Primitive Operations: SaC Unpacked
Search as Code runs on a three-layer stack: a model control plane, a secure compute sandbox, and an Agentic Search SDK . The split matters because it moves orchestration logic out of a fixed endpoint and into code the model writes per task. Each layer owns one job — reasoning, execution, and primitives — and the published implementation is driven by GPT-5.5 at high reasoning .
Layer 1, the control plane. A frontier model reasons about the task, decomposes it into sub-goals, and emits Python that assembles a bespoke retrieval pipeline. It is not selecting a pre-wired API call and varying a query string; it is generating the program that batches queries, branches on intermediate results, and decides what to fetch next .
Layer 2, the secure sandbox. Generated code runs deterministically in an isolated container that handles batching, retries, filtering, and aggregation so the model does not have to micromanage them token by token . A notable engineering choice: state is managed through filesystem-based serialization and deserialization rather than a persistent REPL, a decision Perplexity attributes to reliability across long trajectories where a live interpreter session would drift or break .
Layer 3, the Agentic Search SDK. This surfaces the search backend as discrete, composable primitives the model codes against instead of one monolithic endpoint. Reported building blocks include:
retrieve— pull ranked results from the indexfanout— issue parallel sub-queriesfilter/dedupe— prune and collapse resultsrerank— reorder by task relevanceparse_field— extract structured valuesrender— shape output for the next reasoning step
Each is a callable the model composes in code, with batching, retries, and aggregation layered underneath .
On language choice, Perplexity evaluated Python, Rust, TypeScript, and Bash and picked Python for its ubiquity — the runtime a frontier model has seen most and generates most reliably . The SDK and its Agent Skills are kept compact, each under roughly 2,000 tokens, and a continuous "autoresearch" loop refines both the skills and the primitive set over time . The practical caveat: this full internal SDK surface is described in Perplexity's research write-up but is not yet exposed in the public API docs .
CVE Case Study: Why Perplexity's 100% Figure Warrants a Second Opinion
Perplexity's headline result is a vendor-reported CVE benchmark on which Search as Code scored 100% accuracy while every non-Perplexity system stayed below 25% . The task: resolve 200+ high-severity CVEs from 2023–2025, each requiring a correct vendor advisory URL, affected product, and fix version . That is a clean, verifiable retrieval problem — facts that either match a published advisory or do not — which makes it a strong demonstration. It is also Perplexity's own dataset, run by Perplexity, with no independent replication confirmed.
Quick Answer: Perplexity reports Search as Code hit 100% accuracy on 200+ high-severity 2023–2025 CVEs with an 85.1% token cut (288.7K → 42.9K), versus under 25% for rival systems. The figures are vendor-run and not yet independently reproduced, so treat them as positioning until external evals confirm them.
The efficiency claim is as notable as the accuracy: SaC reportedly cut token usage 85.1%, from 288.7K to 42.9K, by inspecting intermediate state in the sandbox and feeding only resolved fields back into the model's context . The broader benchmark suite tells a similar story. Across five evaluations, all using GPT-5.5 at high reasoning except Anthropic's Opus 4.7, Perplexity says SaC led four:
| Benchmark | SaC | Closest cited rival |
|---|---|---|
| DSQA | 0.871 | 0.815 (Anthropic) / 0.733 (OpenAI) |
| BrowseComp | 0.805 | — |
| WideSearch | 0.651 | — |
| WANDR | 0.386 | 0.130 (OpenAI) |
| Humanity's Last Exam | ~tied | 0.614 (OpenAI) |
Perplexity frames the gains as +29% (+19.77 points) on DSQA and +45% (+12.00 points) on WANDR . The caveat developers should hold onto: those percentages are calculated against Perplexity's own traditional-pipeline baseline, not a neutral reference. Two things further soften the numbers. WANDR is a newly developed benchmark Perplexity has not yet published — it says it will release details in coming weeks — and Perplexity itself calls WANDR "unsaturated" and hard even for SaC . A 0.386 lead over a 0.130 rival on an unreleased test is suggestive, not settled.
None of this means the results are wrong. CVE resolution is exactly the kind of multi-step, cross-source retrieval where generating a bespoke pipeline should beat a fixed query loop, and the directional story is coherent . But the dataset is internal and the figures are vendor-run. The verification angle for now: treat the 100% as a well-constructed demo, and watch for Anthropic's MCP-based agents or OpenAI Responses to post comparable CVE or DSQA-style evals before reading SaC's lead as a durable, reproducible gap.
How SaC Compares to Fixed Invocations and Pre-Written Tool Wrappers
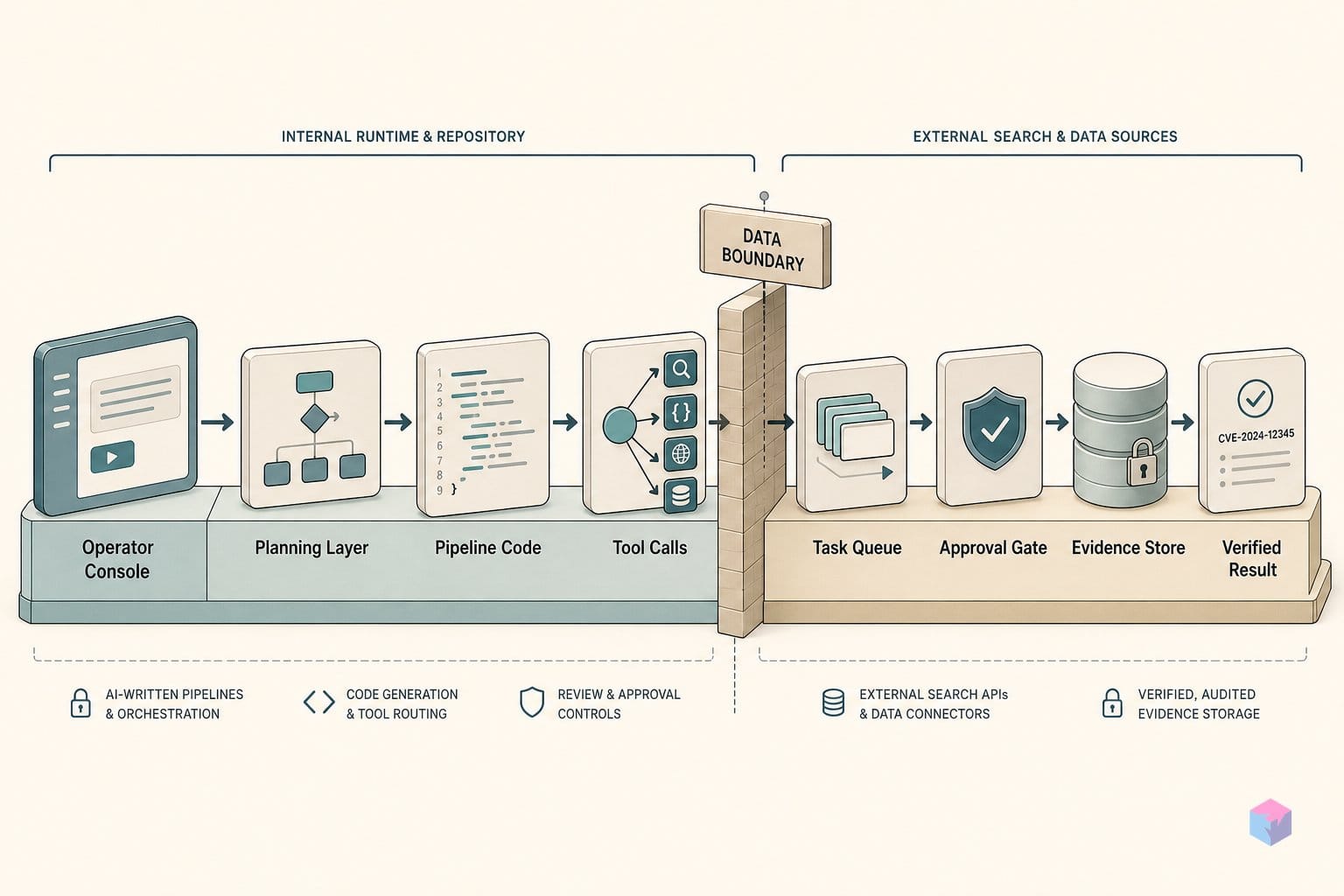
The core difference is when the retrieval logic gets written. Pre-written tool wrappers — the model picks from a catalog of pre-authored, named tools, as in Anthropic's Model Context Protocol — keep the tool logic human-written and frozen: the model decides which tool to call and with what arguments, but it cannot rewrite the tool's internals at inference time (video: NetworkChuck). Search as Code inverts that: a frontier model generates the retrieval pipeline in Python during the request, then runs it in a sandbox .
That shift buys flexibility for task shapes nobody pre-authored a tool for. SaC parallels the broader agent-tooling movement, but differs by having the model emit executable code rather than invoke fixed named tools . A traditional fixed-invocation loop varies only the query string while ranking, filtering, and pagination stay opaque; with generated code, multi-step fanout, parallel deduplication, and conditional reranking can run in a single pass — no explicit orchestrator chaining required, because the model writes the orchestration itself .
The trade-off is failure modes that static tool registries never expose. A named tool either exists or doesn't; generated code can be syntactically wrong, semantically off, or non-terminating, which is part of why Perplexity manages state via filesystem serialization rather than a REPL for reliability on long trajectories .
The sharper concern is security. When the model writes and executes code, prompt injection can escalate into code injection — a hostile page or retrieved document that steers generation could, in principle, steer the executed program. That makes sandbox isolation a hard dependency, not an optional hardening step. Perplexity runs SaC inside secure compute sandboxes that deterministically execute model-generated code, but the sandbox tool is still marked preview, with quotas and pricing subject to change . For teams weighing SaC against an MCP-style registry, that isolation boundary — not raw benchmark deltas — is the line that decides whether code-generating retrieval is safe to deploy.
Invocation Fees for Web Search, Fetch, and Sandbox Sessions
SaC pricing is per-invocation, not per-token, and the numbers are small enough that cost rarely gates experimentation — but the structure matters once an agent fans out to hundreds of calls. Perplexity's docs list web_search at $0.005 per invocation, fetch_url at $0.0005, and both people_search and finance_search at $0.005 each . The sandbox bills $0.03 per session, where a session covers up to 20 minutes of active use — a billing window, not a hard runtime cap — and SDK search queries issued from inside that sandbox are billed at $0.005 each, the same rate as a top-level web search .
| Operation | Unit | Price |
|---|---|---|
| web_search | per invocation | $0.005 |
| fetch_url | per invocation | $0.0005 |
| people_search / finance_search | per invocation | $0.005 each |
| sandbox | per session (≤20 min active) | $0.03 |
| SDK search (inside sandbox) | per query | $0.005 |
| Search API (raw ranked results) | per 1,000 requests | $5.00, no token cost |
The lower-level Search API sits outside this agent stack: $5.00 per 1,000 requests with no token overhead, returning structured JSON for teams that want ranked results without a model in the loop . Agent API model access is billed at direct provider token rates with no markup, spanning Perplexity, Anthropic, OpenAI, Google, xAI, and NVIDIA .
One caveat for anyone modeling production spend: every figure here is flagged subject to change, and the sandbox remains in preview with runtime availability and quotas under active revision . Treat this as a directional price sheet, not a stable surface to budget a quarter against.
What's Not Settled: WANDR, Unpublished Primitives, and Sandbox GA
Several pieces of Search as Code remain unverifiable or in flux as of June 2026, and developers evaluating it should treat them as open questions rather than settled facts. The headline gap is WANDR: Perplexity reports SaC at 0.386 against OpenAI's 0.130 on that benchmark, but says it will publish the benchmark only "in coming weeks" . Until then the comparison cannot be externally reproduced or audited, and Perplexity itself calls WANDR "unsaturated" and hard even for SaC .
There is also a gap between what the research paper describes and what you can actually call. The internal Agentic Search SDK surface — primitives like fanout, parse_field, render, and intermediate-state handling — is wider than what the public Agent API currently documents . The low-level toolset is described, not yet exposed for use outside Perplexity's own harnesses.
The execution layer is similarly provisional. The sandbox tool is marked preview, with runtime availability, quotas, and pricing all subject to change — Perplexity explicitly warns against treating it as a stable production dependency . And the published implementation runs on GPT-5.5 at high reasoning , with Perplexity framing language and model choices as subject to "periodic reevaluation." The architecture is model-agnostic by design, so the specific control-plane model could shift.
The concrete takeaway: the SaC idea — models generating their own retrieval code against composable primitives — is real and shipping inside Perplexity Computer and the Agent API. The numbers are vendor-reported and the surface you can build on is narrower than the paper. Prototype against it; wait for the published benchmarks and a GA sandbox before betting production on it.
Frequently asked questions
How is Search as Code different from calling a fixed search API?
A fixed search API returns ranked results from a single call, and the model can only vary the query string — ranking, filtering, pagination, and aggregation stay opaque and human-optimized inside the endpoint. Search as Code (SaC) instead exposes Perplexity's backend as atomic, composable primitives — retrieve, fanout, filter, dedupe, rerank, parse_field — that a frontier model orchestrates by generating Python code . Control over ordering, filtering, and aggregation shifts to the model rather than being baked into the API .
Are Perplexity's SaC benchmark figures independently verified?
No. Every published figure — DSQA 0.871, BrowseComp 0.805, WANDR 0.386, and the 100% CVE accuracy claim — is vendor-reported and not yet independently replicated in the cited sources . The WANDR benchmark is newly developed and unpublished; Perplexity says it will release it in the coming weeks and itself calls it "unsaturated" . Treat the numbers as directionally interesting, not peer-reviewed — external replication is still pending.
What does the Perplexity sandbox actually run?
The sandbox executes model-generated Python inside an isolated container during a request, handling batching, retries, filtering, and aggregation rather than returning raw results to the model . State is managed through filesystem-based serialization rather than a REPL, a choice Perplexity made for reliability across long agent trajectories. The sandbox tool is currently marked preview, with runtime availability, quotas, and pricing subject to change .
What does SaC cost per invocation?
Per Perplexity's docs — flagged as subject to change — web_search costs $0.005 per call, fetch_url $0.0005 per call, and sandbox $0.03 per session covering up to 20 minutes of active use . SDK search queries issued from inside the sandbox are billed at $0.005 each, and the lower-level Search API is $5.00 per 1,000 requests with no token costs . Model tokens are billed at direct provider rates with no markup.
Can I call SaC's composable primitives from my own code today?
Not as a standalone low-level SDK. SaC runs inside the Perplexity Computer and Agent API harnesses, and the internal Agentic Search SDK primitives — fanout, parse_field, render, and the rest — are not publicly documented . The accessible entry points are the Agent API, exposed at POST https://api.perplexity.ai/v1/agent, and the sandbox tool, which remains in preview . Prototype against those today; the full primitive surface described in the research paper is not yet callable directly.








