
20년 동안 검색 API는 한 가지를 의미했습니다: 쿼리 문자열을 보내고, 순위가 매겨진 목록을 받아 사람(또는 사람인 척하는 모델)이 결과를 훑어보는 것. Perplexity의 새로운 "Search as Code"는 그 계약을 다시 씁니다 — 모델에게 파이프라인 자체를 넘겨줍니다.
Search as Code: 불투명한 블랙박스에서 조합 가능한 검색 프리미티브로
Search as Code(SaC)는 AI 에이전트가 고정된 검색 엔드포인트를 호출하는 대신 코드로 자체 검색 파이프라인을 작성하고 실행할 수 있게 해주는 Perplexity의 레퍼런스 아키텍처입니다 . 이 변화는 구조적입니다: 기존 검색 API는 단일 블랙박스 엔드포인트로, 모델이 변경할 수 있는 것은 쿼리 문자열뿐이고 랭킹·필터링·페이지네이션은 불투명한 채 사람이 읽기에 맞게 조정되어 있었습니다. SaC는 이를 뒤집습니다 — 프론티어 모델이 작업을 분해하고, 원자적이고 조합 가능한 프리미티브로 맞춤형 파이프라인을 조립하는 Python 코드를 생성합니다.
한눈에 보기: Search as Code는 Perplexity의 아키텍처로, 검색 백엔드를 조합 가능한 프리미티브(retrieve, fanout, filter, dedupe, rerank)로 노출하여 모델이 하나의 고정 API를 호출하는 대신 Python 코드를 직접 작성해 오케스트레이션하도록 합니다. Perplexity는 CVE 사례 연구에서 SaC가 토큰 85.1% 감소로 100% 정확도를 달성했다고 보고합니다.
단일한 모놀리식 호출 대신, 모델은 retrieve, fanout, filter, dedupe, rerank 같은 연산을 태스크 특화 프로그램으로 엮어냅니다 . 이 아키텍처의 동기는 사람의 브라우징이 아니라 에이전트 워크로드입니다. Perplexity에 따르면, Computer 제품 내 단일 태스크가 수분 내에 수백에서 수천 건의 검색 연산을 발동시키기도 했습니다 — 열 개의 파란 링크를 읽는 사람에게는 무의미한 규모지만, 긴 궤적을 실행하는 에이전트에게는 일상적인 수준입니다. 공개된 구현체는 높은 추론 설정의 GPT-5.5로 구동됩니다 .
CEO Aravind Srinivas는 이 방향성을 명확히 밝혔습니다:
"검색의 미래는 코드젠입니다," — Aravind Srinivas, Perplexity CEO (source: Storyboard18).
실질적인 이점은 컨텍스트 절약에 있습니다. 모델이 작성한 코드는 샌드박스에서 실행되므로, 중간 결과물(부분 결과 집합, 제거된 중복 항목, 리랭크 임시 데이터 등)은 샌드박스 안에 머물고, 유용한 최종 출력만 모델의 추론 컨텍스트로 되돌아옵니다 . 이는 긴 세션에서 컨텍스트 윈도우 오염을 줄이고, 모델이 원시 페이지를 직접 프롬프트로 처리하는 데 소비하던 왕복 횟수를 줄입니다. 이 접근 방식은 Anthropic의 Model Context Protocol을 포함한 에이전트 툴링 운동의 흐름과 맥을 같이하지만, 한 가지 점에서 다릅니다: 미리 만들어진 명명된 도구를 호출하는 것이 아니라 모델이 실행 가능한 코드를 직접 생성한다는 것입니다 .
컨트롤 플레인, 보안 샌드박스, 기본 연산: SaC 해부
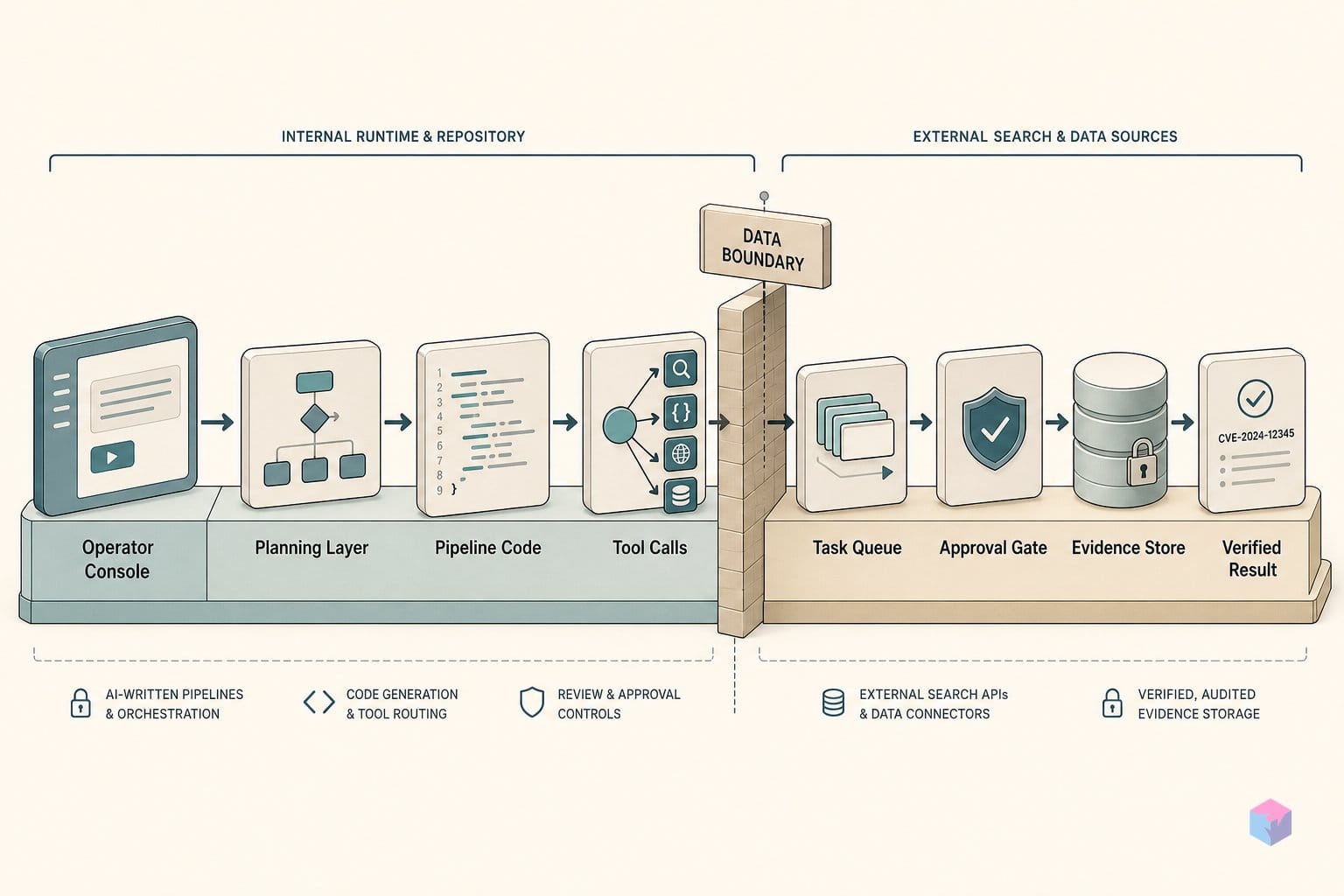
Search as Code는 모델 컨트롤 플레인, 보안 컴퓨팅 샌드박스, 에이전틱 검색 SDK라는 세 계층 스택으로 동작합니다 . 이 분리가 중요한 이유는, 오케스트레이션 로직이 고정 엔드포인트에서 벗어나 모델이 작업마다 직접 작성하는 코드 안으로 들어오기 때문입니다. 각 계층은 추론·실행·기본 연산이라는 하나의 역할만 담당하며, 공개된 구현은 높은 추론 수준의 GPT-5.5가 구동합니다 .
1계층, 컨트롤 플레인. 프론티어 모델이 작업을 추론하고 하위 목표로 분해한 뒤, 맞춤형 검색 파이프라인을 조립하는 Python 코드를 생성합니다. 사전에 연결된 API 호출을 선택해 쿼리 문자열만 바꾸는 방식이 아니라, 쿼리를 일괄 처리하고 중간 결과에 따라 분기하며 다음에 무엇을 가져올지 결정하는 프로그램 자체를 생성합니다 .
2계층, 보안 샌드박스. 생성된 코드는 격리된 컨테이너 안에서 결정론적으로 실행되며, 배치 처리·재시도·필터링·집계를 컨테이너가 담당하므로 모델이 토큰 하나하나로 이를 직접 제어할 필요가 없습니다 . 주목할 만한 엔지니어링 선택은 상태 관리 방식입니다. 지속적인 REPL 세션 대신 파일시스템 기반 직렬화·역직렬화를 사용하는데, Perplexity는 라이브 인터프리터 세션이 장기 실행 궤적에서 드리프트되거나 중단될 수 있어 안정성을 위해 이 방식을 선택했다고 밝혔습니다 .
3계층, 에이전틱 검색 SDK. 검색 백엔드를 하나의 모놀리식 엔드포인트가 아닌, 모델이 코드로 직접 다룰 수 있는 개별·조합 가능한 기본 연산으로 노출합니다. 알려진 구성 요소는 다음과 같습니다:
retrieve— 인덱스에서 순위가 매겨진 결과 가져오기fanout— 병렬 하위 쿼리 실행filter/dedupe— 결과 정제 및 중복 제거rerank— 작업 관련성 기준으로 재정렬parse_field— 구조화된 값 추출render— 다음 추론 단계에 맞는 출력 형태로 가공
각각은 모델이 코드 안에서 조합하는 호출 가능한 함수이며, 배치 처리·재시도·집계는 그 아래 계층에서 처리됩니다 .
언어 선택과 관련해, Perplexity는 Python·Rust·TypeScript·Bash를 검토한 끝에 Python을 택했습니다. 프론티어 모델이 가장 많이 접하고 가장 안정적으로 생성하는 런타임이기 때문입니다 . SDK와 Agent Skills는 각각 약 2,000토큰 이하로 컴팩트하게 유지되며, 지속적인 "오토리서치" 루프가 시간이 지남에 따라 스킬과 기본 연산 세트를 함께 개선합니다 . 실용적인 주의 사항으로, 이 내부 SDK의 전체 인터페이스는 Perplexity의 연구 게시물에 기술되어 있지만 아직 공개 API 문서에는 노출되지 않았습니다 .
CVE 사례 연구: Perplexity의 100% 수치를 다시 봐야 하는 이유
Perplexity의 대표 결과는 자체 보고한 CVE 벤치마크입니다. 이 벤치마크에서 Search as Code는 정확도 100%를 기록한 반면, Perplexity 외 모든 시스템은 25% 미만에 머물렀습니다 . 과제는 2023~2025년 고위험 CVE 200건 이상을 해결하는 것으로, 각 CVE마다 올바른 벤더 권고 URL, 영향받는 제품, 패치 버전을 정확히 맞혀야 했습니다 . 공개된 권고문과 일치하는지 여부가 명확한, 검증 가능한 검색 문제였기에 강력한 시연 사례라 할 수 있습니다. 다만 이 데이터셋은 Perplexity가 자체 제작하고 직접 실행한 것으로, 독립적인 재현 사례는 아직 확인되지 않았습니다.
한눈에 보기: Perplexity에 따르면 Search as Code는 2023~2025년 고위험 CVE 200건 이상에서 정확도 100%를 달성했으며, 토큰 사용량을 85.1%(288.7K → 42.9K) 절감했습니다. 경쟁 시스템은 25% 미만에 그쳤습니다. 이 수치는 벤더가 직접 실행한 것으로 아직 독립 검증이 이루어지지 않았으니, 외부 평가가 확인될 때까지 포지셔닝 자료로 받아들이세요.
정확도만큼 주목할 만한 것이 효율성 수치입니다. SaC는 샌드박스의 중간 상태를 검사해 해결된 필드만 모델 컨텍스트에 반환하는 방식으로 토큰 사용량을 85.1% 절감했다고 합니다(288.7K → 42.9K) . 더 넓은 벤치마크 결과도 비슷한 흐름입니다. Anthropic Opus 4.7을 제외하고 모두 GPT-5.5 고추론 모드를 사용한 5개 평가에서, Perplexity는 SaC가 4개 평가를 선도했다고 밝혔습니다:
| 벤치마크 | SaC | 가장 근접한 경쟁사 |
|---|---|---|
| DSQA | 0.871 | 0.815 (Anthropic) / 0.733 (OpenAI) |
| BrowseComp | 0.805 | — |
| WideSearch | 0.651 | — |
| WANDR | 0.386 | 0.130 (OpenAI) |
| Humanity's Last Exam | ~tied | 0.614 (OpenAI) |
Perplexity는 DSQA에서 +29%(+19.77점), WANDR에서 +45%(+12.00점)의 향상을 제시합니다 . 개발자가 놓치지 말아야 할 주의 사항이 있습니다. 이 퍼센트는 중립적 기준이 아니라 Perplexity 자체의 기존 파이프라인 대비 수치입니다. 수치를 더 희석시키는 요소가 두 가지 있습니다. WANDR은 Perplexity가 아직 공개하지 않은 신규 벤치마크로, 향후 몇 주 내 상세 내용을 공개할 예정이라고 밝혔습니다. Perplexity 스스로도 WANDR을 "포화되지 않았고 SaC조차 어렵다"고 인정합니다 . 미공개 테스트에서 경쟁사 0.130 대비 0.386의 우위는 시사적이긴 하지만 확정적이지 않습니다.
이것이 결과가 틀렸다는 의미는 아닙니다. CVE 해결은 다단계·교차 출처 검색에서 맞춤형 파이프라인이 고정 쿼리 루프를 능가해야 하는 대표적인 사례이며, 방향성 자체는 일관성이 있습니다 . 그러나 데이터셋은 내부 것이고 수치는 벤더가 직접 실행한 것입니다. 당분간 검증 관점에서는 100%를 잘 구성된 데모로 받아들이고, SaC의 우위를 지속 가능하고 재현 가능한 격차로 판단하기 전에 Anthropic의 MCP 기반 에이전트나 OpenAI Responses가 유사한 CVE 또는 DSQA 스타일 평가를 발표하는지 지켜봐야 합니다.
SaC vs 고정 호출 방식·사전 작성 도구 래퍼
핵심 차이는 검색 로직이 작성되는 시점입니다. 사전 작성 도구 래퍼 — Anthropic의 Model Context Protocol처럼 모델이 사전에 작성된 명명 도구 카탈로그에서 선택하는 방식 — 는 도구 로직을 사람이 작성한 채 고정해 둡니다. 모델은 어떤 도구를 어떤 인수로 호출할지 결정하지만, 추론 시점에 도구 내부를 재작성할 수는 없습니다(video: NetworkChuck). Search as Code는 이를 뒤집습니다. 프론티어 모델이 요청 시점에 Python으로 검색 파이프라인을 직접 생성한 뒤 샌드박스에서 실행합니다 .
이 전환은 아무도 미리 도구를 작성해 두지 않은 태스크 유형에서 유연성을 제공합니다. SaC는 더 넓은 에이전트 도구화 흐름과 맥을 같이하지만, 고정된 명명 도구를 호출하는 대신 모델이 실행 가능한 코드를 직접 생성한다는 점에서 다릅니다 . 기존 고정 호출 루프는 쿼리 문자열만 변경하고 랭킹·필터링·페이지네이션은 불투명하게 유지됩니다. 생성 코드를 사용하면 다단계 팬아웃, 병렬 중복 제거, 조건부 재랭킹을 단일 패스로 처리할 수 있습니다. 명시적인 오케스트레이터 체인이 필요 없는 것은 모델이 오케스트레이션 자체를 작성하기 때문입니다 .
단점은 정적 도구 레지스트리에서는 드러나지 않는 실패 방식입니다. 명명 도구는 존재하거나 존재하지 않거나 둘 중 하나입니다. 생성된 코드는 문법적으로 틀리거나, 의미적으로 어긋나거나, 무한 루프에 빠질 수 있습니다. 이것이 Perplexity가 긴 궤적에서 안정성을 위해 REPL 대신 파일시스템 직렬화로 상태를 관리하는 이유 중 하나입니다 .
더 심각한 우려는 보안입니다. 모델이 코드를 작성하고 실행하면, 프롬프트 인젝션이 코드 인젝션으로 확대될 수 있습니다. 악의적인 페이지나 검색된 문서가 생성을 조작한다면 실행되는 프로그램도 조작될 수 있습니다. 따라서 샌드박스 격리는 선택적 강화 조치가 아닌 필수 의존성입니다. Perplexity는 모델이 생성한 코드를 결정론적으로 실행하는 보안 컴퓨팅 샌드박스 안에서 SaC를 운영하지만, 이 샌드박스 도구는 아직 미리보기 단계이며 할당량과 가격은 변경될 수 있습니다 . MCP 스타일 레지스트리와 SaC를 저울질하는 팀에게, 코드 생성 검색의 안전한 배포 여부를 결정하는 것은 벤치마크 수치 차이가 아니라 바로 이 격리 경계입니다.
웹 검색·Fetch·샌드박스 세션의 호출 요금
SaC 요금은 토큰 단위가 아닌 호출 단위로 부과되며, 금액 자체는 실험을 막을 만큼 크지 않습니다. 하지만 에이전트가 수백 번의 호출로 분기되면 구조가 중요해집니다. Perplexity 공식 문서에 따르면 web_search는 호출당 $0.005, fetch_url은 $0.0005, people_search와 finance_search는 각각 $0.005입니다 . 샌드박스는 세션당 $0.03이 청구되며, 한 세션은 최대 20분간의 활성 사용을 포함합니다. 이는 과금 창이지 실행 시간 상한이 아닙니다. 샌드박스 내부에서 발행된 SDK 검색 쿼리는 최상위 웹 검색과 동일한 요율인 건당 $0.005가 청구됩니다 .
| 작업 | 단위 | 가격 |
|---|---|---|
| web_search | 호출당 | $0.005 |
| fetch_url | 호출당 | $0.0005 |
| people_search / finance_search | 호출당 | 각 $0.005 |
| sandbox | 세션당 (활성 20분 이하) | $0.03 |
| SDK search (샌드박스 내부) | 쿼리당 | $0.005 |
| Search API (원시 순위 결과) | 1,000건당 | $5.00, 토큰 비용 없음 |
하위 수준의 Search API는 이 에이전트 스택 밖에 위치합니다. 요청 1,000건당 $5.00이며 토큰 오버헤드 없이 구조화된 JSON을 반환해, 모델 없이 순위 결과만 원하는 팀에 적합합니다 . Agent API 모델 접근은 마크업 없이 공급사 직접 토큰 요율로 청구되며, Perplexity·Anthropic·OpenAI·Google·xAI·NVIDIA를 포함합니다 .
프로덕션 비용을 추정하는 분들께 한 가지 주의사항: 여기 언급된 모든 수치는 변경 가능성이 있으며, 샌드박스는 아직 프리뷰 상태로 런타임 가용성과 쿼터가 지속적으로 수정 중입니다 . 이는 안정적인 분기 예산 기준이 아닌 방향성 참고 가격표로만 활용하세요.
아직 미결인 것들: WANDR·미공개 프리미티브·샌드박스 GA
2026년 6월 현재 Search as Code의 여러 부분은 검증이 불가능하거나 유동적이며, 이를 평가하는 개발자는 확정된 사실이 아닌 열린 질문으로 다루어야 합니다. 핵심 공백은 WANDR입니다. Perplexity는 해당 벤치마크에서 SaC가 0.386, OpenAI가 0.130이라고 발표했지만, 벤치마크는 "수 주 내"에 공개하겠다고만 밝혔습니다 . 그때까지 비교 결과를 외부에서 재현하거나 감사할 수 없으며, Perplexity 스스로도 WANDR을 "미포화" 상태이자 SaC에도 어렵다고 표현합니다 .
논문에서 설명하는 내용과 실제로 호출할 수 있는 것 사이에도 간극이 있습니다. 내부 Agentic Search SDK 표면, 즉 fanout·parse_field·render 및 중간 상태 처리 같은 프리미티브는 현재 공개 Agent API 문서보다 훨씬 광범위합니다 . 저수준 툴셋은 문서에 설명되어 있으나, Perplexity 자체 하네스 외부에서는 아직 사용할 수 없습니다.
실행 레이어도 마찬가지로 잠정적입니다. 샌드박스 도구는 프리뷰로 표시되어 있으며 런타임 가용성·쿼터·요금 모두 변경될 수 있습니다. Perplexity는 이를 안정적인 프로덕션 의존성으로 취급하지 말 것을 명시적으로 경고합니다 . 그리고 공개된 구현은 높은 추론 설정의 GPT-5.5에서 실행되며 , Perplexity는 언어 및 모델 선택이 "주기적 재검토" 대상임을 밝히고 있습니다. 아키텍처는 설계상 모델에 구애받지 않으므로, 제어 플레인 모델은 언제든 변경될 수 있습니다.
명확한 결론: SaC의 아이디어, 즉 모델이 조합 가능한 프리미티브를 기반으로 자체 검색 코드를 생성한다는 개념은 실제이며 Perplexity Computer와 Agent API 내부에서 출시 중입니다. 수치는 벤더가 보고한 것이고, 실제로 구축할 수 있는 표면은 논문보다 좁습니다. 프로토타입으로는 활용하되, 프로덕션에 투자하기 전에 공개 벤치마크와 GA 샌드박스를 기다리세요.
자주 묻는 질문
Search as Code는 고정 검색 API 호출과 무엇이 다른가요?
고정 검색 API는 단일 호출로 순위가 매겨진 결과를 반환하며, 모델은 쿼리 문자열만 바꿀 수 있고 — 순위 결정·필터링·페이지네이션·집계는 엔드포인트 내부에서 불투명하게 사람 기준으로 최적화된 채 남아 있습니다. 반면 Search as Code(SaC)는 Perplexity의 백엔드를 원자적이고 조합 가능한 기본 요소 — retrieve, fanout, filter, dedupe, rerank, parse_field — 로 노출하며, 프론티어 모델이 Python 코드를 생성해 이를 직접 오케스트레이션합니다 . 정렬·필터링·집계에 대한 제어권이 API 내부에 고정되는 대신 모델로 이전됩니다 .
Perplexity SaC 벤치마크 수치, 독립적으로 검증됐나요?
아니요. 공개된 모든 수치 — DSQA 0.871, BrowseComp 0.805, WANDR 0.386, 그리고 CVE 정확도 100% 주장 — 는 벤더 자체 발표이며, 인용된 출처에서 아직 독립적으로 재현·검증되지 않았습니다 . WANDR 벤치마크는 새로 개발된 미공개 항목으로, Perplexity는 수 주 내 공개 예정이라고 밝히며 스스로 '포화되지 않은(unsaturated)' 벤치마크라고 칭합니다 . 수치는 방향성 참고용으로만 해석하세요 — 동료 검토를 거친 것이 아니며, 외부 재현 검증은 아직 진행 중입니다.
Perplexity 샌드박스, 실제로 무엇을 실행하나요?
샌드박스는 요청 처리 중 격리된 컨테이너 내에서 모델이 생성한 Python을 실행하며, 원시 결과를 모델에 반환하는 대신 배치 처리·재시도·필터링·집계를 직접 수행합니다 . 상태는 REPL 방식이 아닌 파일시스템 기반 직렬화로 관리되는데, 이는 긴 에이전트 실행 궤적 전반에서 안정성을 확보하기 위한 Perplexity의 설계 선택입니다. 샌드박스 툴은 현재 프리뷰 상태이며, 런타임 가용성·할당량·가격은 변경될 수 있습니다 .
SaC 호출 비용은 얼마인가요?
Perplexity 공식 문서 기준 — 변경 가능성이 명시됨 — web_search는 호출당 $0.005, fetch_url은 호출당 $0.0005, 샌드박스는 최대 20분 활성 사용을 포함해 세션당 $0.03입니다 . 샌드박스 내부에서 발행되는 SDK 검색 쿼리는 건당 $0.005로 청구되며, 하위 레벨 Search API는 1,000건당 $5.00이고 토큰 비용은 없습니다 . 모델 토큰은 마크업 없이 공급자 직접 요율로 청구됩니다.
지금 내 코드에서 SaC 조합 기본 요소를 직접 호출할 수 있나요?
독립적인 저수준 SDK 형태로는 불가능합니다. SaC는 Perplexity Computer 및 Agent API 하네스 내부에서 실행되며, 내부 Agentic Search SDK 기본 요소 — fanout, parse_field, render 등 — 는 공개 문서화되어 있지 않습니다 . 현재 접근 가능한 진입점은 POST https://api.perplexity.ai/v1/agent 로 노출된 Agent API와 프리뷰 상태인 샌드박스 툴입니다 . 지금은 이 두 진입점을 기반으로 프로토타입을 구축하세요. 연구 논문에서 설명한 전체 기본 요소 인터페이스는 아직 직접 호출할 수 없습니다.








