
Most JEPA world models you read about in 2026 are billion-parameter systems trained on a million hours of video. DVD-JEPA goes the other way: it learns the physics of a bouncing screensaver logo on a laptop CPU, and you can read every line of it.
What Is DVD-JEPA?
DVD-JEPA is a minimal, MIT-licensed Joint-Embedding Predictive Architecture (JEPA) world model that learns the motion of the classic bouncing DVD screensaver logo entirely from pixels — without ever being given a coordinate label. It was released on June 13, 2026 by independent developer Mandar Wagh (GitHub: mandarwagh9) and is built on PyTorch . The author bills it as "the smallest honest demonstration" of JEPA principles, and the trained model runs client-side in a browser — no server, no GPU .
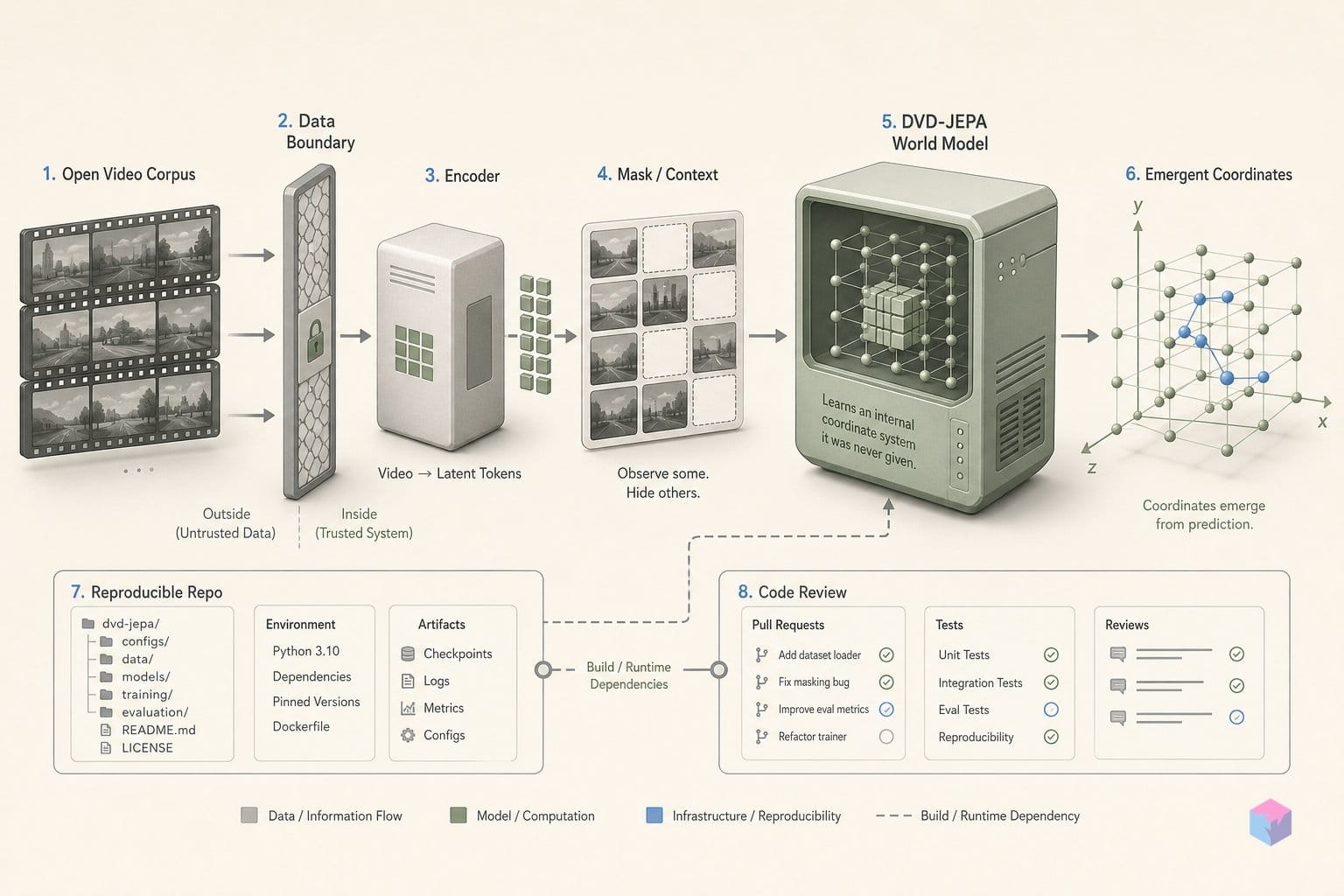
The core premise follows Yann LeCun's 2022 JEPA position paper: predict the next state as a latent vector, not a pixel reconstruction. In DVD-JEPA the predictor is the world model — it imagines the next embedding — while an optional decoder exists only to visualize that "dream." Forecasting in representation space, rather than rebuilding the image, is the whole point.
Training is a single command, python -m dvd_jepa.train, and finishes in roughly 10 seconds on a CPU; the exported model is then served in-browser with about 40 lines of JavaScript . At publication the repository had 6 commits and around 30 stars, and it ships the paper's LaTeX source plus figure-generation scripts so every reported number can be regenerated . Treat it as a rigorous educational artifact, not a maintained library — its self-reported metrics have no third-party benchmarking yet.
DVD-JEPA's Predictor, EMA Target, and VICReg Regularizer
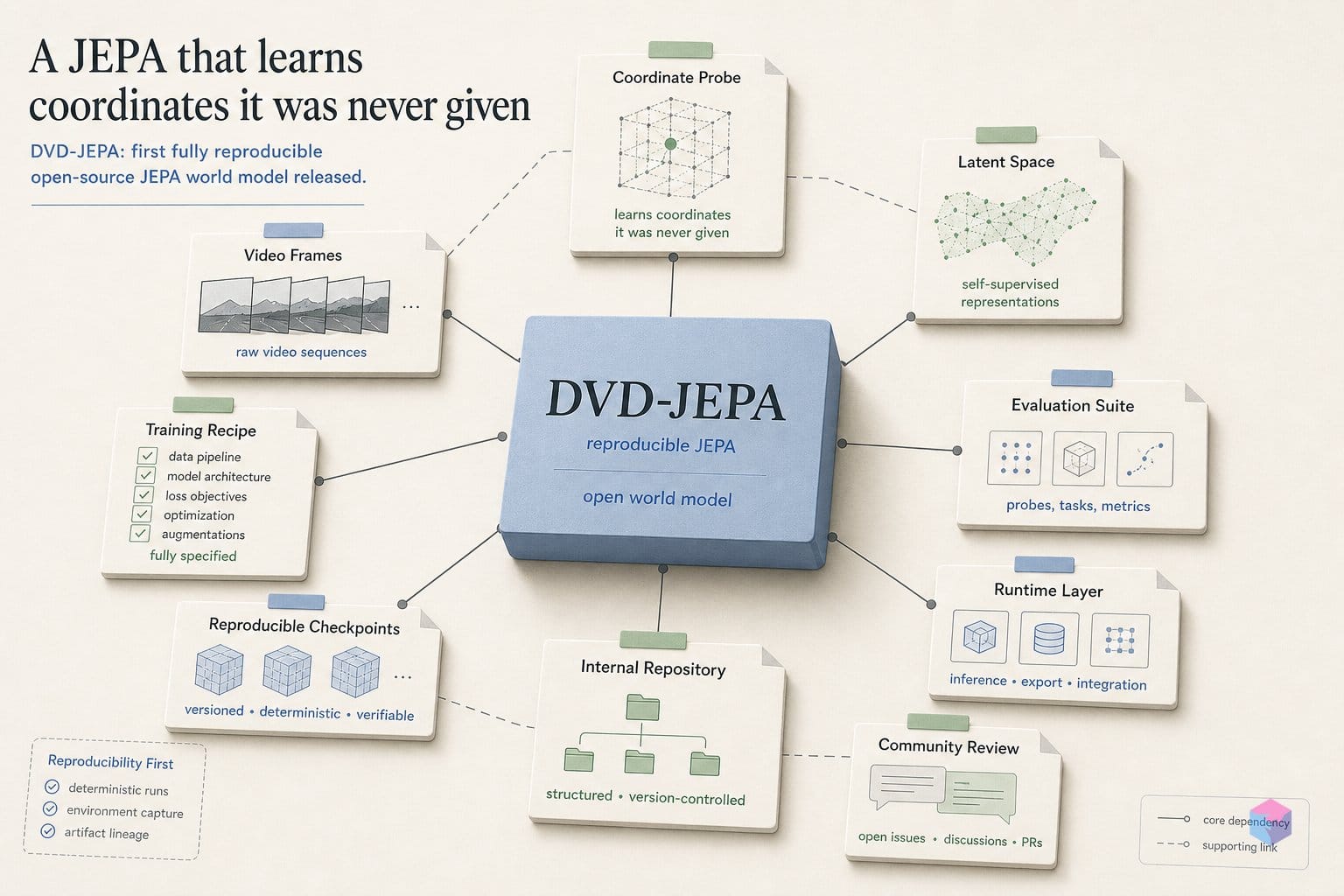
DVD-JEPA is built from four small modules that map directly onto the canonical JEPA template, and their size is the point: every tensor in the representation pathway is small enough to inspect by hand. The context encoder E_θ takes a 2×16×16 pixel patch and compresses it through 256 → 128 → 32 down to a 32-dimensional latent . That latent — not a pixel buffer — is where all forecasting happens, which is the structural distinction from generative video models.
| Module | Shape | Role |
|---|---|---|
Context encoder E_θ | 2×16×16 → 256 → 128 → 32 | Encodes the current frame into a 32-dim latent |
Target encoder E_ema | EMA copy of E_θ | Stop-gradient, slow-moving copy that produces stable prediction targets |
Predictor P | 32 → 64 → 32 | The world model: forecasts the next latent from the current one |
Decoder D (optional) | 32 → 64 → 256 → 256 | Visualizes the model's "dream"; no training signal |
The target encoder E_ema is an exponential-moving-average, stop-gradient copy of E_θ . This is the standard JEPA defense against shortcut solutions: because the target slowly trails the online encoder and receives no gradient, the network cannot trivially collapse both sides onto the same constant to drive loss to zero. The predictor P (32 → 64 → 32) then learns to imagine the next embedding directly, so planning and rollout occur entirely in representation space.
The training objective pairs a latent prediction error with a VICReg-style variance regularizer that keeps each latent dimension active and blocks representational collapse . The decoder D (32 → 64 → 256 → 256) exists only to render what the model "sees" when it dreams the next frame; it contributes nothing to the loss, so removing it changes the visualization but not the learned dynamics. The conceptual takeaway, per the project, is that the model predicts the future as a vector, not a picture .
Parsing the 0.73 px Probe and 88× Surprise Spike
The three headline numbers DVD-JEPA reports each test a different property of that vector forecast, and they should be read separately. A linear probe trained on the frozen 32-dimensional latents recovers the logo's position to roughly 0.73 px . That is the load-bearing result: a linear map is too weak to compute coordinates on its own, so if it reads them out cleanly, the encoder already stored them. The model was never given a coordinate, yet the unsupervised representation encodes one — the most direct evidence for the JEPA representation-quality claim in this repo .
The predictor rolls forward about 20 steps before drift accumulates . Read this as the effective planning horizon on the bouncing-logo domain, not a general video-prediction figure — error compounds each step the imagined embedding feeds back into itself, and 20 steps reflects a deterministic, low-entropy scene, not real footage.
Teleporting the logo produces roughly an 88× spike in the prediction-error "surprise" meter . Because the predictor expects a smooth bounce, a discontinuity it never modeled registers as a large latent residual, which makes the prediction error itself a usable anomaly signal inside this domain. The live demo lets you trigger the teleport and watch the meter react .
One caveat governs all three. As the author frames the project, it is "the smallest honest demonstration" of JEPA principles — and honest cuts both ways. Every figure here is self-reported by the repo and demo site, with no independent benchmarking or peer review at publication time. Treat the 0.73 px, 20-step, and 88× numbers as instructive for understanding how a JEPA behaves, not as comparative evidence against other world models.
EB-JEPA Shipped in February — DVD-JEPA's Niche Is Narrower
DVD-JEPA is not the first open-source JEPA world model, and that framing does not survive contact with the 2026 release history. Meta/FAIR's EB-JEPA — an official, Apache-2.0 library for Energy-Based JEPAs — was introduced in an arXiv paper dated February 3, 2026, months before DVD-JEPA's June 13, 2026 release. So the defensible superlative for DVD-JEPA is narrower than "first": it is the smallest fully reproducible toy JEPA world model with browser inference. The "first open-source JEPA" claim does not hold.
EB-JEPA ships three progressively harder examples — image representation learning, video prediction, and action-conditioned planning — each designed for single-GPU training within a few hours. It reports up to 91.02% CIFAR-10 linear-probe accuracy (SIGReg), multi-step Moving MNIST prediction, and 97% planning success in its Two Rooms environment. At crawl time its repo showed 715 stars and 85 forks — a different audience and scale than DVD-JEPA's ~30 stars.
It is also not alone. JEPA-WMs (facebookresearch, December 30, 2025) publishes action-conditioned world models with pretrained checkpoints across five robot environments, reportedly outperforming DINO-WM and V-JEPA-2-AC on navigation and manipulation — but its CC-BY-NC 4.0 license rules out commercial use. LeWorldModel (~15M parameters, arXiv 2603.19312) is another end-to-end-from-pixels JEPA trainable on a single GPU in hours.
| Release | Date | License | Headline result |
|---|---|---|---|
| EB-JEPA | 2026-02-03 | Apache-2.0 | 91% CIFAR-10 probe; 97% Two Rooms planning |
| JEPA-WMs | 2025-12-30 | CC-BY-NC 4.0 | Beats DINO-WM, V-JEPA-2-AC on robot tasks |
| DVD-JEPA | 2026-06-13 | MIT | Smallest toy JEPA with browser inference |
As LeCun's collaborators frame the energy-based line, EB-JEPA is "a lightweight library and tutorial" for Energy-Based JEPAs (source: Terver et al., FAIR, 2026-02). Read against that, DVD-JEPA's value is pedagogical reach, not priority.
DVD-JEPA and the 2026 JEPA Landscape
To place DVD-JEPA correctly, compare it against the compute-heavy end of the spectrum it deliberately avoids. Meta's V-JEPA 2, announced June 11, 2025, is a 1.2-billion-parameter world model pre-trained on more than 1 million hours of video plus 1 million images, then action-conditioned on 62 hours of DROID robot data . It reports 77.3 top-1 on Something-Something v2 and 65–80% pick-and-place success on new objects and environments . That is a different artifact class entirely: powerful, but not something a single developer inspects end-to-end on a CPU.
A second reference point is DINO-WM, from November 2024, which builds a latent visual dynamics model on frozen DINOv2 patch features and runs zero-shot action-sequence optimization across six environments . Its reproducibility trade-off is distinct from DVD-JEPA's: no fine-tuning is required, but you inherit DINOv2 pretrained weights as a dependency rather than training every module from scratch.
Read across these releases, the 2026 direction is a healthy diversification of the reproducibility spectrum — from large-but-partially-reproducible models toward smaller, more complete packages. EB-JEPA serves as a permissive teaching library, JEPA-WMs ships checkpoints and a dataset for planning, and DVD-JEPA occupies the minimal-toy slot with browser inference. The author frames his model as predicting the future "as a vector, not a picture" — Mandar Wagh, DVD-JEPA author (source: GitHub, 2026-06), which is the same collapse-avoidance machinery the larger systems use, just made legible.
For developers surveying this field before committing, the community-maintained awesome-jepa tracker is a practical index of license terms, compute requirements, and reproducibility level across implementations.
When to Clone DVD-JEPA vs. Reach for EB-JEPA
Pick DVD-JEPA when your goal is understanding, and EB-JEPA when your goal is shipping. DVD-JEPA's value is that its entire collapse-avoidance stack — the EMA target encoder plus a VICReg-style variance term — fits in under 200 lines of Python and trains in roughly 10 seconds on CPU . EB-JEPA, by contrast, is a maintained Apache-2.0 library from Meta/FAIR with single-GPU examples and real benchmarks . Use this as a quick decision guide:
- Clone DVD-JEPA if you want to read EMA-target + VICReg machinery end to end, need browser-compatible inference from an exported model (the demo runs in ~40 lines of client-side JavaScript), or you are teaching JEPA fundamentals and need a fully inspectable reference .
- Reach for EB-JEPA if you need GPU-scale examples with CIFAR-10 (~91% linear probe), Moving MNIST prediction, or Two Rooms planning (97% success), want an extensible maintained codebase, or have commercial use on the table — its license permits it .
- Use JEPA-WMs checkpoints if you are targeting robot manipulation or navigation and need pretrained weights such as jepa_wm_droid or jepa_wm_metaworld — but read the CC-BY-NC 4.0 (noncommercial) license before any product work .
One operational caveat: at capture DVD-JEPA was a 6-commit, single-author project with ~30 stars and no independent benchmarking . Fork it freely, but do not wire it into a production dependency tree. Treat the bundled LaTeX paper and figure-generation script as the primary artifact — that is where its reproducibility claim actually lives.
The Toy Domain Boundary: Why Position-Only Metrics Don't Generalize
The bouncing-logo domain is deterministic, low-entropy, and strictly 2D — which is exactly why it is ideal for demonstrating a JEPA training loop, and exactly why none of its metrics transfer. A logo with constant velocity and reflective walls has a tiny state space, so recovering position to ~0.73 px is meaningful inside that world and silent about anything outside it. Reading it as a real-video, robotics, or control result is a category error.
That caveat matters most when you line DVD-JEPA up against its larger relatives. Comparing its probe number to I-JEPA or V-JEPA accuracy on ImageNet or Kinetics — V-JEPA 2 reports 77.3 top-1 on Something-Something v2 across 1.2B parameters — measures different domains at different information densities. The ~88× surprise spike on a teleport is similarly scoped: its size is partly a function of how large that perturbation is relative to the domain's near-zero natural variance, so it says little about anomaly detection in richer, stochastic settings.
The honest value sits elsewhere. DVD-JEPA trades empirical competitiveness for conceptual clarity, making the collapse-avoidance machinery — EMA target encoder plus VICReg regularizer, latent-space prediction, linear-probe evaluation, surprise-based anomaly signal — legible end-to-end in a way a 1.2-billion-parameter codebase cannot. The takeaway: clone it to understand how JEPAs avoid representational collapse, not to benchmark one.
Frequently asked questions
What is DVD-JEPA and how does it differ from Meta's V-JEPA 2?
DVD-JEPA is a minimal toy Joint-Embedding Predictive Architecture that learns the physics of the bouncing DVD screensaver logo from pixels alone, using a 32-dimensional latent and training in roughly 10 seconds on CPU . Meta's V-JEPA 2, announced June 11, 2025, sits at the opposite end of the spectrum: 1.2 billion parameters pre-trained on more than 1 million hours of video plus 1 million images, then action-conditioned on 62 hours of DROID robot data . Both share the core JEPA recipe — predict in latent space, prevent collapse with an EMA target encoder — but differ by roughly seven orders of magnitude in scale and compute. One is a learning artifact you can read end-to-end; the other is a research-grade world model for real-world video and control.
Is DVD-JEPA actually the first open-source JEPA world model?
No. The "first fully reproducible open-source JEPA world model" framing is the weakest part of the project's positioning. Meta/FAIR's EB-JEPA shipped February 3, 2026 under an Apache-2.0 license with image, video, and planning examples , and the facebookresearch/jepa-wms release — PyTorch code plus pretrained checkpoints and an 11.1 GB dataset — appeared December 2025 . DVD-JEPA's defensible, narrower niche is the smallest fully reproducible toy JEPA world model with client-side browser inference .
What does VICReg do in DVD-JEPA and why is it necessary?
VICReg prevents representational collapse — the failure mode where the encoder maps every input to the same vector, trivially minimizing prediction error while learning nothing useful. It adds a variance term that penalizes low-variance latent dimensions and a covariance term that decorrelates them, forcing the 32-dimensional embedding to stay informative . DVD-JEPA pairs this with a complementary anti-collapse signal: the EMA target encoder is a stop-gradient, exponential-moving-average copy of the context encoder, which decouples the prediction target from the parameters being optimized so the model cannot cheat by shrinking both sides toward a constant . Together they are the machinery that lets the unsupervised latent recover logo position to roughly 0.73 px.
Can I use DVD-JEPA in a commercial project?
The MIT license permits commercial use, but practically you should not. DVD-JEPA is a 6-commit educational artifact with no published releases — fine for learning, unsuitable as a production dependency . For commercial JEPA work, EB-JEPA (Apache-2.0) is the appropriate starting point, with a maintained library and single-GPU examples . Note that JEPA-WMs is licensed CC-BY-NC 4.0 and its dataset gates access behind contact details, so it must not be used commercially .
How do I reproduce the 0.73 px linear probe result from scratch?
Run the single training command, python -m dvd_jepa.train, which finishes in roughly 10 seconds on CPU using PyTorch, then execute the included linear-probe evaluation script against the frozen 32-dimensional latents to recover logo position to about 0.73 px . The repository ships the paper's LaTeX source and the figure-generation script, so every reported number — the probe accuracy, the ~20-step rollout horizon, and the ~88× surprise spike — can be regenerated end-to-end, which is the basis for the "fully reproducible" label .









