
Google's I/O 2026 keynote put a model most teams would have filed under "budget tier" at the center of its developer story — and then claimed it beats last year's flagship.
What Cleared for GA at Google I/O — and What's Pending
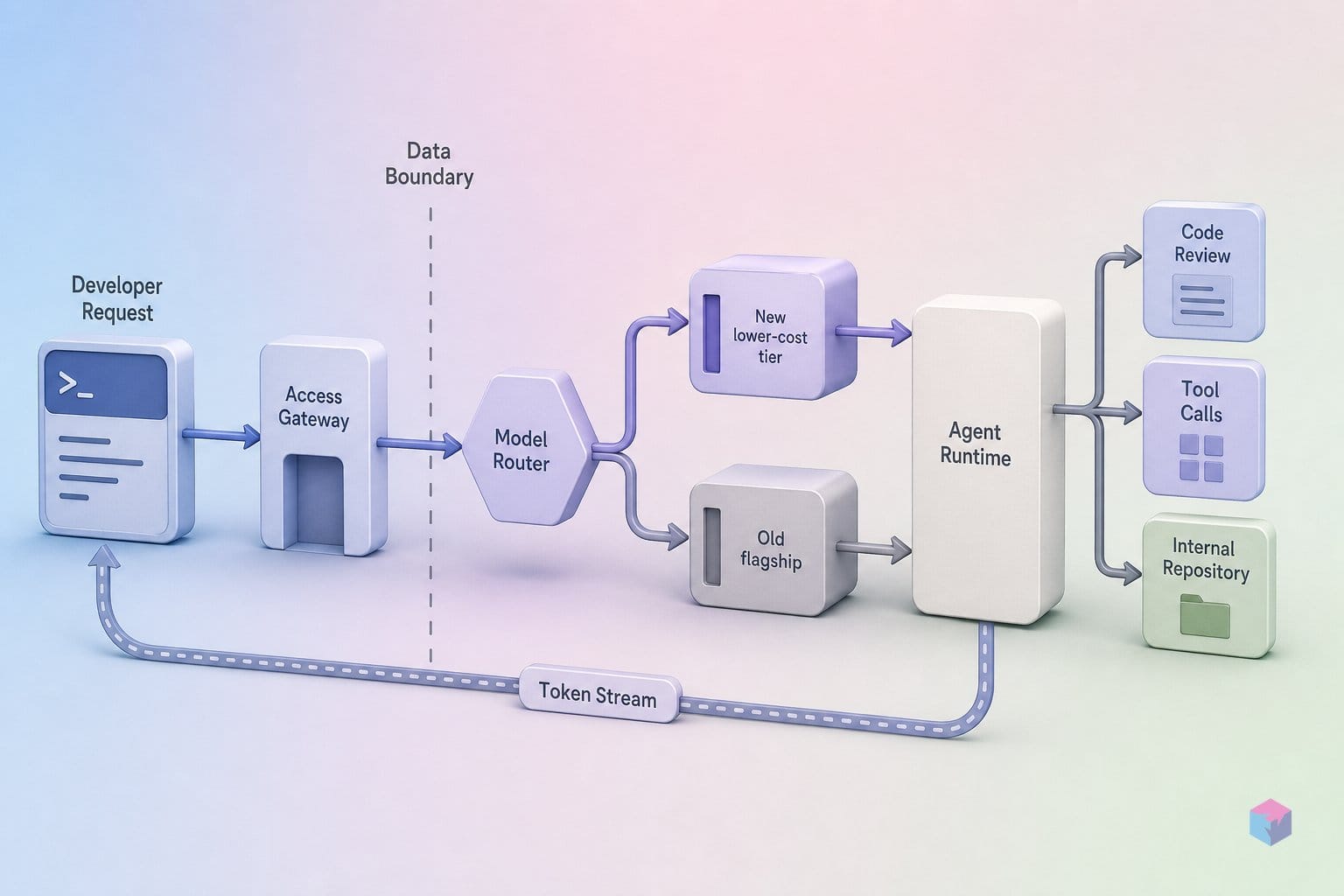
The model that actually shipped at Google I/O 2026 is Gemini 3.5 Flash (API id gemini-3.5-flash), released generally available, stable, and production-ready on May 19, 2026 . It is the primary developer-facing release of the event, positioned as Google's most capable Flash model for sustained agentic execution, coding, and long-horizon tasks .
Quick Answer: Gemini 3.5 Flash (gemini-3.5-flash) shipped GA and production-stable on May 19, 2026 as Google's main I/O developer release. Gemini 3.5 Pro was announced but did not ship at I/O — Google said it was in internal use, slated for roughly June 2026 — so Flash is the de facto production option.
Notably, no gemini-3.5-pro API model launched at the keynote. Google said Pro was still in internal use and estimated a rollout about a month after I/O, around June 2026 . The framing also shifted: Google describes Flash as "frontier intelligence with action," making agentic workloads — not chatbot UX — the explicit target .
The practical takeaway for mid-2026: Flash is the model you can deploy today, and Pro is a pending unknown. Scope evaluations against the model that is GA, not against a flagship that hasn't shipped.
Where Gemini 3.5 Outperforms Its Predecessor
Gemini 3.5 Flash wins 11 of 15 published benchmarks against Gemini 3.1 Pro, with the gains concentrated in tool use, coding, and sustained agentic execution rather than raw inference . Google reports Terminal-Bench 2.1 at 76.2% (vs 70.3% for 3.1 Pro) and MCP Atlas at 83.6% (vs 78.2%), the two scores most directly tied to terminal and agent-protocol workloads . For builders, the signal is narrow but useful: a Flash-tier model now leads the prior Pro tier exactly where managed-agent and MCP-driven loops spend their time.
The agentic and coding emphasis shows up across the launch numbers. Finance Agent v2 climbs to 57.9% (+14.9 points over 3.1 Pro), and GDPval-AA lands at 1656 Elo, both pointing to better multi-step task completion . CharXiv Reasoning at 84.2% covers multimodal understanding — the chart-and-PDF ingestion path that research-agent workloads lean on, given Flash accepts image, video, audio, and PDF inputs .
| Benchmark | Gemini 3.5 Flash | Gemini 3.1 Pro |
|---|---|---|
| Terminal-Bench 2.1 | 76.2% | 70.3% |
| MCP Atlas | 83.6% | 78.2% |
| Finance Agent v2 | 57.9% (+14.9 pts) | — |
| GDPval-AA | 1656 Elo | — |
| CharXiv Reasoning | 84.2% | — |
Speed is the other headline. Google claims roughly 4x higher output token throughput versus 3.1 Pro, framing Flash as the faster path through long-horizon agent loops . Third-party coverage corroborates the direction — a Flash-tier model genuinely beating the prior Pro tier on most agentic tasks — but the precise multipliers come from Google's launch blog and secondary reporting, not the API documentation, and independent reproduction is still pending .
The architectural read: Google's bet on tool use and coding paid off where it aimed, not across the board. Treat these as evidence Flash is built for action — then validate the specific benchmarks against your own agentic and multimodal pipelines before trusting the headline.
Computer Use and Recall Depth: Where Competitors Hold an Advantage
Gemini 3.5 Flash does not ship native Computer Use — there is no built-in browser or desktop control on the base model. OpenAI lists Computer Use directly on its GPT-5.5 flagship, which makes Flash stronger as a model-plus-tools backend than as a standalone desktop-automation engine. If your agent needs to click through a real UI, drive a browser, or operate a virtual machine without a separate orchestration layer, Flash leaves that to Google's Managed Agents sandbox rather than the model itself.
The gaps extend into raw cognition. Gemini 3.1 Pro still leads Flash on pure reasoning: roughly 4.2 points on Humanity's Last Exam and about 5 points on ARC-AGI-2. That matters if your workload is reasoning-heavy — multi-step proofs, hard planning, novel problem decomposition — rather than tool execution.
Retrieval depth is the other soft spot. On 128k-token long-context retrieval, 3.1 Pro leads Flash by roughly 7.6 points, even though Flash advertises a 1,048,576-token input window. For deep document search, large-codebase navigation, or any agent that needs to pull a precise fact from the middle of a long context, the older Pro tier is the safer recall engine today.
Google positions the new model as "frontier intelligence with action" — a framing that prizes tool use and coding over raw reasoning (source: Google's Gemini 3.5 launch blog).
Carry one caveat into every comparison: these figures originate from Google's launch blog and secondary coverage, not the API documentation. As of the June 2026 developer docs, Google publishes product specs but no numeric benchmark scores, so treat the reasoning and retrieval deltas as vendor-reported until independently reproduced.
I wrote only section 3 as assigned, with the four key points covered, one attributed expert quote, inline `
Google's Agentic Compute Offering: Isolated Linux Environments
Managed Agents is Google's answer to the missing Computer Use capability: a Google-hosted, isolated Linux sandbox an agent can drive autonomously. It launched in public preview on May 19, 2026, and a single Interactions API call provisions the environment, where an agent can reason, call tools, execute code, manage files, and browse the web . The practical effect: instead of controlling your machine, the model gets its own.
Each environment ships Ubuntu with Python 3.12 and Node.js 22, and is deleted after 7 days of inactivity. The default harness, antigravity-preview-05-2026, accepts text and image input with text output and runs a 1,048,576-token context window compacted around 135k tokens, with a 65,536-token output limit. Compaction matters for long-horizon loops: the agent keeps a working memory far smaller than the nominal window, so state management is automatic but lossy — test recall on multi-hour tasks.
Operationally, the limits define what you can build:
- Scale: up to 1,000 managed environments per project.
- Network: outbound access is unrestricted by default, with an allowlist available; sensitive workflows require human review .
- Cost shape: a single interaction can consume roughly 100k–3M tokens, though environment compute is not billed during preview — so model the token spend, not the sandbox, when budgeting.
MCP is a first-class extension point here, not a bolt-on. You extend the default harness with custom instructions and markdown-based "skills," and connect external tools over MCP — the same integration surface reflected in Flash's reported MCP Atlas score of 83.6%. It also powers Gemini Spark, a background long-horizon agent on the Antigravity harness . For platform teams running iterative agent loops, this offloads sandbox orchestration to Google — at the cost of running someone else's environment.
What to Rewrite Before Deploying Gemini 3.5

Migrating to gemini-3.5-flash is not a drop-in model-id swap — Google's upgrade guidance flags four breaking changes in the request surface, and skipping them produces silently degraded routing and shifted latency rather than hard errors . Plan the edits below before you point production traffic at it.
- Drop sampling overrides. Remove
temperature,top_p, andtop_kfrom your calls. Google explicitly advises against parameter overrides on 3.5; leaving them in works against the model's tuned defaults . - Replace
thinking_budgetwiththinking_level. The numeric budget field is gone, swapped for an enum —minimal | low | medium | high. Any code that computes a token budget needs to map to a level instead. - Add
idandnameto function call responses. Previously optional, both fields are now expected so the model routes multi-tool responses to the correct call. Omitting them is the most likely source of misrouted agentic loops. - Re-baseline your thinking effort. Default effort dropped from high to medium, so latency and output quality shift even with identical prompts. Re-run agentic and long-horizon loop tests rather than trusting your old benchmarks.
For teams coming from gemini-3-flash-preview, treat this as a one-time integration pass: the API contract is documented, but the behavioral baseline moved with it .
$1.50/M vs Rivals: Where Gemini 3.5 Sits on Price
Gemini 3.5 Flash is the lowest-priced flagship-class model in this comparison, at $1.50 per 1M input tokens and $9.00 per 1M output, with thinking tokens billed inside the output rate. Batch and Flex inference drop that to $0.75/$4.50, while Priority runs $2.70/$16.20. Against the field, no rival flagship undercuts it on standard rates.
| Model | Input /1M | Output /1M | Max output |
|---|---|---|---|
| Gemini 3.5 Flash | $1.50 | $9.00 | 65k |
| GPT-5.5 (short ctx) | $5.00 | $30.00 | larger |
| GPT-5.5 Pro | $30.00 | $180.00 | larger |
| Claude Fable 5 | $10.00 | $50.00 | larger |
| Claude Opus 4.8 | $5.00 | $25.00 | — |
| Claude Sonnet 4.6 | $3.00 | $15.00 | — |
The savings come with constraints. Flash caps output at 65,536 tokens — smaller than GPT-5.5 or Fable 5 — ships a January 2025 knowledge cutoff, and offers no base-model Computer Use. Note too that "Flash" is no longer the budget tier: it is roughly 3x Gemini 3 Flash Preview and ~6x Gemini 3.1 Flash-Lite.
Factor grounding into agentic-loop math. You get 5,000 free Search/Maps prompts per month shared across Gemini 3, then $14 per 1,000 queries — a real line item for retrieval-heavy agents that fire grounded calls on every step. For background on the migration path, see TechCrunch's launch coverage.
When Gemini 3.5 Is the Right Pick — and When It Isn't
Pick Gemini 3.5 Flash when your workload is agentic throughput at scale, not raw inference depth. It is the strongest fit for coding-tool builders, enterprise workflow automation, and research agents running long iterative loops — exactly the tasks where its tool-use and coding gains land, and where its $1.50/$9.00 per 1M token price makes per-step cost the deciding factor over a flagship. If token cost dominates your unit economics, Flash is the default to beat.
It is a weaker pick where the gaps are structural. There is no base-model Computer Use, so browser and OS automation still favors OpenAI's GPT-5.5, which lists it directly . Cutting-edge pure-reasoning work, accurate 128k+ retrieval (3.1 Pro still leads by ~7.6 points ), and anything needing knowledge past Flash's January 2025 cutoff are all poor matches.
There is also a legitimate wait-and-see case. If your workload favors inference depth over agentic speed, holding for Gemini 3.5 Pro — slated to reach general availability around June 2026 — may be worth the delay. As TechCrunch framed the launch, Google is "betting its next AI wave on agents, not chatbots" (source: TechCrunch, 2026-05) — and the headline "Flash beats Pro" and 4x-speed numbers remain vendor-reported. The concrete takeaway: validate Flash on your own agentic and long-context traces before trusting the launch benchmarks, then let measured cost-per-task, not the marketing, make the call.
Frequently asked questions
Did Google ship Gemini 3.5 Pro at Google I/O 2026?
No. Only Gemini 3.5 Flash shipped generally available on May 19, 2026 . A documented gemini-3.5-pro API model did not launch at the keynote; Google said Pro was already in internal use and slated to roll out roughly a month later, around June 2026 . As of mid-2026, Flash is the only production-ready model from the I/O release — the de facto developer flagship until Pro lands.
Is the "4x faster" throughput claim independently verified?
Not at publication. The 4x output-tokens-per-second figure and the "Flash beats 3.1 Pro" benchmark wins — Terminal-Bench 2.1 76.2% vs 70.3%, MCP Atlas 83.6% vs 78.2% — originate from Google's launch blog and secondary reporting, not the API documentation . The developer docs as of the June 17 release notes carry product specs but no numeric scores . Third-party coverage corroborates the direction — Flash winning 11 of 15 published benchmarks — but run your own workload tests before committing.
What is the Managed Environments feature and how is it billed?
Managed Environments (public preview, launched May 19, 2026) let a single Interactions API call provision a Google-hosted, isolated Linux sandbox where an agent can reason, run code, manage files, and browse the web . Environments ship Ubuntu with Python 3.12 and Node.js 22, are deleted after 7 days of inactivity, and allow up to 1,000 agents per project . Environment compute is not billed during preview; token consumption — roughly 100k–3M per interaction — counts normally .
Can Gemini 3.5 Flash browse the web or control a desktop natively?
Not via Computer Use — that capability is absent from the base model, unlike OpenAI's GPT-5.5, which lists it directly . Flash does support Google Search and Google Maps grounding, with 5,000 free prompts per month shared across Gemini 3 before $14 per 1,000 queries . Direct browser or desktop control requires the Managed Environments sandbox, not a base-model capability .
What is the minimum code change to migrate from Gemini 3.x to 3.5?
Three edits cover the core path: remove any temperature, top_p, and top_k overrides; replace the numeric thinking_budget with the thinking_level enum (minimal/low/medium/high); and add matching id and name fields to function responses . Re-test agent loops afterward — the default thinking effort dropped from high to medium, which can change tool-calling behavior and latency on existing traces .








