
Most text-to-image models still take a sentence and guess at the layout. Ideogram 4.0 takes a JSON object and places each element where you tell it to.
What Ideogram 4.0 Is and Why the Schema Matters
Ideogram 4.0 is a 9.3-billion-parameter diffusion transformer released on June 3, 2026, trained end-to-end on structured JSON captions rather than free-text prompts, and shipped as Ideogram's first open-weight text-to-image foundation model . The vendor is explicit that it is a model trained from scratch, "not a fine-tune or distillation" of any prior checkpoint . The notable part for builders is not image quality but the control surface: layout-first generation driven by a schema, with downloadable weights you can run yourself.
Quick Answer: Ideogram 4.0 (June 3, 2026) is a 9.3B-parameter diffusion transformer trained on structured JSON, not prose. It treats layout as data — each element gets a bounding box in 0–1000 coordinates. Ideogram reports a 7Bench layout mIoU of 0.69, a vendor figure, not independently verified.
The headline numbers are worth stating early — and flagging. Ideogram reports a 7Bench layout mIoU of 0.69 and an X-Omni English OCR accuracy of 0.97, the latter described as the highest among open-weight models at its scale . Both are Ideogram-claimed as of mid-June 2026 and rest on the company's own blog and GitHub rather than an independently cached benchmark run, so treat them as vendor-reported.
The core shift is structural. Layout is specified as a JSON object with a bounding box per element in normalized 0–1000 coordinates, written as [y_min, x_min, y_max, x_max] . Prose prompts still run, but they lose layout fidelity, because the model was trained on the schema and rewards structured input.
"Open-weight" here needs an asterisk. The weights ship as quantized NF4 and FP8 checkpoints via gated Hugging Face repos, but they are non-commercial by default — free for research, evaluation, and prototyping . Production, client-facing, or self-hosted commercial use requires the hosted API or a separately negotiated commercial license . Downloadable, in other words, is not the same as permissive.
Ideogram 3 → 4: Prose Out, JSON Schema In
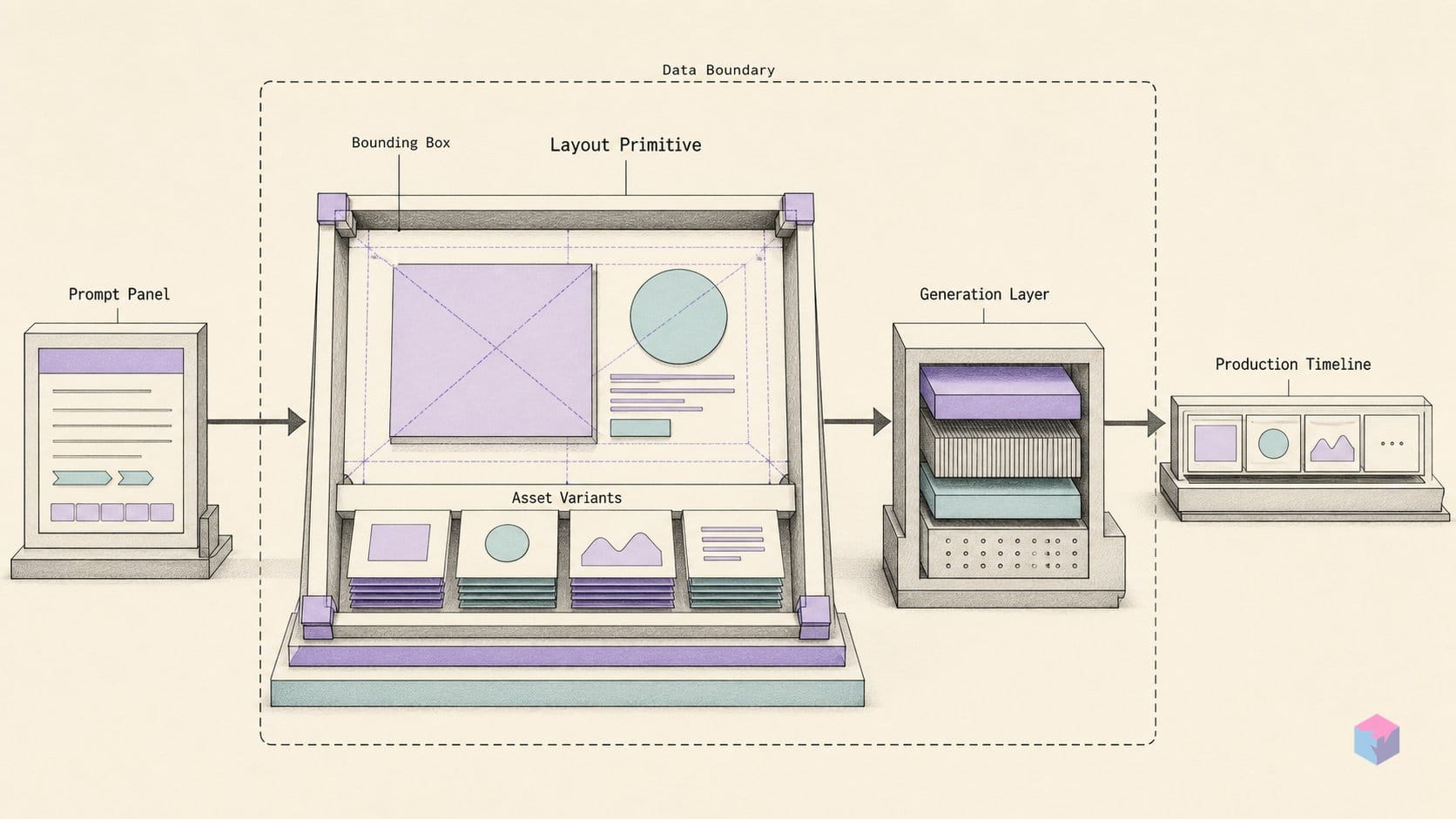
Ideogram 3.0 read a free-text sentence and inferred a layout from it; Ideogram 4.0 reads a structured JSON object that states the layout outright. That is the core break between the two releases. Ideogram 3.0 accepted a prose prompt plus up to three style-reference images and optimized for photorealism and legible in-image text . Ideogram 4.0, released June 3, 2026, treats layout, typography position, per-element color, and rendering style as explicit fields rather than qualities guessed from a sentence .
The difference is baked in at training time, not bolted on afterward. Ideogram 4.0 was trained from scratch on structured JSON captions using a "describe-to-structure-to-recreate" loop, so the model expects and rewards structured input . This matters because layout awareness comes from the training objective, not a post-training adapter or a prompt-engineering trick layered over a prose model. The reference pipeline parses and validates each prompt against the schema before inference, which makes malformed layouts a parse error instead of a silent misrender .
For a builder, the practical shift is from coaxing to specifying. Under Ideogram 3.0 you described a poster and hoped the headline landed where you wanted; under 4.0 you place the headline in a bounding box, attach its color and rendering approach, and run the same template dozens of times with swapped parameters for consistent output across a batch .
| Dimension | Ideogram 3.0 | Ideogram 4.0 |
|---|---|---|
| Prompting method | Free-text sentence | Structured JSON schema |
| Style-reference support | Up to 3 reference images | Per-element style + palette fields in schema |
| Native resolution | Standard output | Native 2K (256–2048 px/side, up to 6:1) |
| Per-element color control | Inferred from prose | ~5 hex slots per element, up to 16 per image |
| Typography handling | Legible in-image text | Literal text string kept separate from its style |
| Downloadable weights | None (hosted only) | NF4 + FP8 quantized, gated, non-commercial by default |
Read top to bottom, the table shows that nothing 4.0 adds is a quality bump on top of the old surface — each row replaces an inferred heuristic with an addressable field . The resolution and color figures (native 2K, 16 hex slots per image, roughly 5 per element) are vendor-documented spec rather than independently benchmarked, but they describe the control contract a developer codes against .
The JSON Schema: Bounding Boxes, Color Palettes, and Typography Objects
The schema a developer codes against has three top-level fields: image_description (a high-level summary of the whole image), style_description (the global visual treatment), and compositional_deconstruction, which holds the actual layout. Inside that object sits a background field plus an array of per-element nodes — each one either a graphical object or a typed text node . This is the structural break from prose: instead of one sentence the model must parse for intent, you hand it a tree where every element is separately addressable, and the reference pipeline parses and validates that tree against the schema before inference .
Position is the field most people will reach for first. Each element carries a bounding box written as [y_min, x_min, y_max, x_max] in normalized integer coordinates from 0 to 1000, on a notional 1000×1000 grid . Two details matter in practice. The order is y-first, not the x-first convention many graphics APIs use, so a careless port will transpose your layout. And the coordinates are integers — fractional values are not valid, so you quantize to the 1000-step grid rather than passing floats.
Color stops being an adjective. Rather than describing "warm coral tones," you bake hex values directly into the JSON: up to 16 hex slots per image and roughly 5 per element . The palette becomes data the model honors per-region, which is what makes brand-consistent output reproducible instead of a re-roll lottery.
Text nodes are where the schema earns its keep. A typed text element keeps the literal string to render separate from its visual style — the characters you want on the canvas live in one field, the styling in another . Because the string is specified literally rather than inferred from a description, in-image typography is the model's strongest dimension, and the separation unlocks batch templating: hold the bounding box and style constant, swap only the string, and run the same layout dozens of times for compositional consistency across a set .
"The schema makes templated design pipelines practical — run the same layout dozens of times with swapped parameters and you get compositional consistency across the whole batch," notes the Ideogram 4 builder's log at ChatForest.
The payoff is determinism. A poster, an apparel mock, or a localized ad set stops being a prompt you nudge and becomes a record you populate — the same reason a config file beats a wish. That is also the constraint: you now own a data contract, and malformed coordinates or out-of-range hex slots fail validation rather than degrading gracefully .
9.3B Diffusion Transformer: Frozen Encoder, Unified Sequence, Flow-Matching
Under that data contract sits a 9.3-billion-parameter single-stream Diffusion Transformer with 34 layers, and "single-stream" is the load-bearing word: text and image tokens are concatenated into one unified sequence rather than routed through a separate cross-attention branch between modalities . Ideogram describes 4.0 as a foundation model trained from scratch — "not a fine-tune or distillation" of an existing checkpoint . For builders, the unified sequence is the architectural reason structured prompts and in-image text behave consistently: layout instructions and pixels share one attention space instead of being reconciled across two.
The text side is a frozen Qwen3-VL-8B-Instruct vision-language encoder. Instead of taking a single final-layer embedding, the model draws hidden states from 13 intermediate layers to assemble multi-scale semantic understanding — coarse intent and fine detail at once . Because the encoder is frozen, you are conditioning a fixed, well-understood text tower rather than co-training one, which is part of why the JSON schema's literal text fields render predictably.
On the pixel side, a frozen KL autoencoder decodes latents back to images, and training uses flow-matching with dual-branch classifier-free guidance . Flow-matching is the now-standard alternative to step-wise denoising diffusion; the dual-branch guidance is what gives the sampler presets (covered later) a clean quality-versus-speed dial.
The capacity envelope is where the design intent shows. The spec lists:
- 2048 max text tokens and a 4608 embedding dimension across 18 attention heads — a large text budget that matches a schema where you may declare many typed text and color elements per image.
- Native 2K output, with supported resolution from 256 to 2048 pixels per side in multiples of 16 .
- Aspect ratios up to 6:1 , wide enough for banners and apparel strips without post-stitching.
The practical read for a developer: the multiples-of-16 constraint and the 256–2048 range are the same discipline as the bounding-box validation — dimensions are part of the contract, not a soft suggestion. Pair the frozen, multi-layer Qwen3-VL conditioning with a unified-sequence DiT and native 2K, and the architecture is optimized for one thing the benchmarks later test: getting specified text and layout to land where the JSON says they should, at print-usable size .
NF4 vs FP8: Quantization Trade-offs and ComfyUI Compatibility
Ideogram 4.0's weights ship in two quantized formats, and the choice between them is really a choice about your inference stack. Both repos hold the same 9.3-billion-parameter model ; the difference is what hardware and which loader they expect. NF4 is CUDA-compatible and ships with Diffusers support, so it drops into existing Diffusers-based pipelines with no custom loader . FP8 covers a broader hardware range but has no Diffusers integration at launch, so running it means writing custom inference code or pulling in a third-party loader .
The practical read for builders:
- NF4 — pick this if you are on NVIDIA and already run Diffusers. CUDA-compatible, Diffusers-native, distributed through a gated Hugging Face repo. Least integration work to a first image .
- FP8 — pick this when you need hardware reach beyond CUDA, and budget time for the loader gap, since Diffusers will not load it as-is at launch .
One constraint applies to both: neither variant is the full-precision checkpoint. These are quantized weights under a non-commercial agreement, fine for research, evaluation, and prototyping. Commercial or production self-hosting of the full-precision model requires a separately negotiated license, not a download . So the open-weight files let you test the architecture locally, but they do not, on their own, clear you for a shipped product.
Ecosystem support arrived early. ComfyUI shipped native 4.0 support at launch, and fal.ai also carried the model from day one, alongside the hosted API . For anyone wiring generation into a node graph, that means the quantized weights and a working UI exist on the same day, not weeks later. The community has also started pushing the quantization further: a June 10, 2026 arXiv paper reports INT8 and GGUF experiments on RTX 3090-class hardware . Those are independent experiments, not official launch artifacts — useful signal that consumer-GPU inference is plausible, but not a supported path from Ideogram itself.
What to Make of the 0.69 mIoU and 47.9% Designer Preference
Ideogram's headline scores are credible but vendor-reported: a 7Bench layout mIoU of 0.69, SpatialGenEval accuracy of 0.76, X-Omni English OCR accuracy of 0.97, and a Prism prompt-alignment score of 0.89. All four come from Ideogram's own models and blog page, so read them as the vendor's self-test, not an audited result.
| Reported metric | Score | Source |
|---|---|---|
| 7Bench layout mIoU | 0.69 | Ideogram |
| SpatialGenEval accuracy | 0.76 | Ideogram |
| X-Omni English OCR | 0.97 | Ideogram |
| Prism prompt-alignment | 0.89 | Ideogram |
The most useful external signal is a ContraLabs blind typography test in which ten professional designers picked Ideogram 4 first 47.9% of the time, ahead of Gemini 3.1 Flash Image Preview at 30.0%, FLUX.2 max at 15.5%, and Grok Imagine 1.0 at 15.0%, with a client-work usability rating of 3.55 out of 5. A blind panel is harder to game than an internal eval, though ten reviewers is a small sample and the test only measures typography, the model's strongest dimension. In Ideogram's own blind preference arena of 4,366 votes, it ranked second overall behind GPT Image 2 medium.
"Ideogram 4.0 leads open-weight models on Design Arena and beats much larger models on text legibility, including FLUX.2 [dev] (32B) and HunyuanImage 3.0 (80B MoE)," — Ideogram, Ideogram 4.0 model documentation (source: GitHub).
Treat the leaderboard claim carefully. Design Arena documents a public methodology — anonymous four-model tournaments scored with Bradley-Terry ratings — but the static public pages did not expose a verifiable Ideogram 4 snapshot, so the ranking is Ideogram-reported as of mid-June 2026. There is no independently cached leaderboard position to confirm it at the time of writing.
One independent sanity check exists, but it speaks to feasibility, not quality. A June 10, 2026 arXiv paper documents successful INT8 and GGUF inference on RTX 3090-class hardware, consistent with the published 9.3B parameter count. That corroborates the architecture and that consumer-GPU inference is plausible — it does not independently evaluate layout accuracy, OCR, or designer preference. Until a third party re-runs 7Bench or a public arena snapshot surfaces, the scores above are best understood as well-specified vendor claims worth verifying against your own prompts.
Parsing the License: Non-Commercial Download, Negotiated Commercial
The license is the catch that the phrase "open-weight" tends to obscure: Ideogram 4.0's downloadable weights are free for research, evaluation, and non-production prototyping, but production, client-facing, and self-hosted commercial deployments require either the hosted API or a separately negotiated commercial license . You can pull the quantized NF4 and FP8 checkpoints from gated Hugging Face repos and run them locally without paying, as long as the work stays non-commercial . The moment that pipeline ships to customers or backs a paid product, you are outside the download license.
The non-commercial tier is genuinely no-cost: download, prototype, benchmark, and fine-tune on your own data for internal experiments, with no payment and no subscription . The commercial tier is where the picture gets less transparent. Production-scale or full-precision commercial use routes you to the tiered hosted API — Turbo at $0.03, Default at $0.06, and Quality at $0.10 per image, with a default ceiling of 10 in-flight requests — or to a bespoke commercial license whose pricing Ideogram does not publish, framing it as "negotiate to match your scale" . For a developer scoping a build, that opacity is the real friction: you can estimate API spend per image, but self-hosted commercial cost is a sales conversation, not a price tag.
Output rights are the more permissive part of the agreement, and worth separating from the model rights. Images you generate — whether through the API or the downloaded weights — are not owned by Ideogram and may be used commercially, subject to acceptable-use and third-party-rights terms . The restriction lands on the model, not the pixels: you can sell the poster, but you cannot run the unlicensed weights in production to make it.
One more distinction matters for anyone reading the repo. The accompanying inference and pipeline code is reported under Apache 2.0, a permissive license separate from the weights agreement . So "open-weight" here means downloadable-but-not-permissive — the code is free to reuse, the weights are gated by use case. That pattern is now the norm rather than the exception, matching how Llama, Mistral, and similar recent foundation models split a permissive codebase from a restricted-weights license.
Sampler Choices and Ecosystem Connectors: ComfyUI, fal.ai, $0.03–$0.10

The hosted API exposes three sampler presets that map directly to per-image price, letting you trade quality for cost at call time rather than at deploy time. Turbo runs 12 steps at $0.03/image, Default runs 20 steps at $0.06/image, and Quality runs 48 steps at $0.10/image, billed per image with no subscription and a default ceiling of 10 in-flight requests . The step counts are the same V4_TURBO_12, V4_DEFAULT_20, and V4_QUALITY_48 presets exposed to local inference, so a draft you tune in ComfyUI maps cleanly onto a paid tier .
Distribution was broad on day one. ComfyUI shipped native support at launch, fal.ai offered 4.0 the same day, and the hosted API is also reachable over MCP for tool-use contexts — so an agent can request a layout-controlled render the same way it calls any other MCP tool .
Two capabilities builders often expect from a design model are not yet part of the inference call. Native alpha channels and editable text layers direct from inference are described as coming in a future 4.x release; until then, background removal and layerize ship today as separate utility tools you run after generation, not as flags on the core request . Plan asset pipelines around that gap: if you need transparent PNGs, budget an extra step.
The economics steer usage cleanly. Per-image pricing with no subscription favors burst work and templated batches — run one validated JSON layout dozens of times with swapped parameters and pay only for what renders. Sustained high-volume production or self-hosted commercial inference is steered toward the negotiated commercial license rather than the metered API . The practical takeaway: prototype on Turbo at $0.03, validate layouts locally with the NF4 or FP8 weights, promote to Quality for client deliverables, and treat the commercial license as the decision point only once volume or self-hosting makes the per-image meter the wrong unit.
Frequently asked questions
What is the Ideogram 4.0 JSON bounding box coordinate format?
Ideogram 4.0 positions each element with a bounding box written as [y_min, x_min, y_max, x_max], using integer values on a normalized 0–1000 grid rather than raw pixels . The box lives inside the compositional_deconstruction object, attached per element alongside its styling . Because coordinates are resolution-independent, the same layout reproduces consistent positioning across a batch even when output dimensions change — useful for templated pipelines that swap parameters while holding composition fixed .
Can I use Ideogram 4.0 weights commercially?
Not by default. The downloadable quantized weights are licensed under Ideogram's non-commercial agreement — free for research, evaluation, and non-production prototyping . Production, client-facing, or self-hosted commercial deployment requires the hosted API or a separately negotiated commercial license . The restriction applies to model use, not to outputs: images you generate are not owned by Ideogram and may be used commercially, subject to acceptable-use and third-party-rights terms .
What is the difference between the NF4 and FP8 quantized variants?
Both are 9.3B-parameter quantized builds, and neither is the full-precision checkpoint . NF4 is CUDA-compatible and ships with Diffusers library support; FP8 reaches a broader range of hardware but has no Diffusers integration at launch . Pick NF4 if you want the Diffusers path on CUDA, FP8 if your target hardware needs the wider compatibility. Full-precision, self-hosted commercial inference is not covered by either download and requires a negotiated commercial license .
How does Ideogram 4.0 handle in-image typography compared to earlier versions?
The JSON schema treats text as a typed element that separates the literal string to render from its visual style, making the string itself a first-class field rather than a sentence the model has to parse out of prose . Because the model was trained end-to-end on this separation, typography is its strongest dimension and stays consistent across batch runs that reuse a layout . Ideogram reports an X-Omni English OCR accuracy of 0.97, which it describes as the highest among open-weight models at its scale — a vendor-reported figure .
Are the Ideogram 4.0 benchmark numbers independently verified?
Mostly no — treat them as vendor-reported. As of mid-June 2026, the 0.69 layout mIoU, 0.97 OCR accuracy, and Design Arena position all rest on Ideogram's own pages and secondary write-ups rather than an independently fetched first-party snapshot . The ContraLabs typography test — where designers picked Ideogram 4 first 47.9% of the time — was run by a third party but is a small sample of ten designers . A June 10, 2026 arXiv paper confirms inference runs on consumer RTX 3090-class hardware via community quantization, but it does not re-evaluate the quality claims .








