
MiniMax는 대부분의 오픈 웨이트 모델이 피해 온 것을 해낸 모델을 출시했습니다. 바로 100만 토큰 컨텍스트, 네이티브 멀티모달리티, 에이전틱 코딩을 하나의 아티팩트에 결합하면서도, 이 조합을 너무 비싸게 만들었던 기존 어텐션 메커니즘을 대체한 것입니다.
MiniMax M3란?
MiniMax M3는 2026년 6월 1일 출시된 네이티브 멀티모달 오픈 웨이트 혼합 전문가(MoE) 모델입니다 . 전체 파라미터는 약 4,280억 개이며 토큰당 약 230억 개가 활성화되고, 최대 1,048,576(2^20)개의 포지션을 처리합니다. 이 넓은 컨텍스트 윈도우를 가능하게 한 것은 MiniMax 희소 어텐션(MSA)으로, 표준 이차(quadratic) 풀 어텐션 대신 블록 단위 희소 메커니즘을 사용합니다 .
한눈에 보기: MiniMax M3는 2026년 6월 1일 출시된 오픈 웨이트 MoE 모델(전체 ~4,280억 / 활성화 ~230억 파라미터)로, 블록 단위 희소 어텐션 기반의 1,048,576 토큰 컨텍스트, 텍스트·이미지·영상 네이티브 입력, 그리고 입력 100만 토큰당 $0.30부터 시작하는 Anthropic 호환 API를 제공합니다.
단일 요청 내에서 멀티모달 처리가 가능합니다. Anthropic 호환 API는 최대 10MB의 JPEG/PNG/GIF/WEBP 이미지와 최대 50MB의 MP4/AVI/MOV/MKV 동영상을 인라인으로(또는 Files API를 통해 512MB까지) 텍스트 및 도구 사용 블록과 함께 처리합니다 . API는 platform.minimax.io에서 운영 중이며 최소 512K 토큰 컨텍스트를 보장하고, 512K 이하 입력 기준 표준 요금은 입력 100만 토큰당 $0.30, 출력 100만 토큰당 $1.20입니다 . 구독 플랜은 Plus $20, Max $50, Ultra $120(월 기준)으로 구성됩니다 .
M3는 2025년 말 출시된 소형 코딩 모델 MiniMax M2의 후속작으로, M2는 활성화 파라미터 100억 개, 전체 2,300억 개, 약 205K 포지션 윈도우, 100만 토큰당 $0.50/$2.20의 요금 체계를 가졌습니다 . 세대 간 변화는 구조적입니다. M2는 Artificial Analysis 지수에서 Claude Sonnet 4.5를 소폭 하회했지만, M3는 컨텍스트 길이와 모달리티 범위를 모두 확장하면서 토큰당 활성화 파라미터를 약 두 배로 늘렸습니다. 다만 출시 당시의 프런티어 벤치마크 수치가 실제로 유효한지는 별개의 문제입니다. 공개된 모든 수치는 벤더 자체 실행 결과이며, 독립적인 재현 검증은 아직 이루어지지 않았습니다.
MSA가 이차 어텐션을 대체하는 방식: 블록 선택 메커니즘
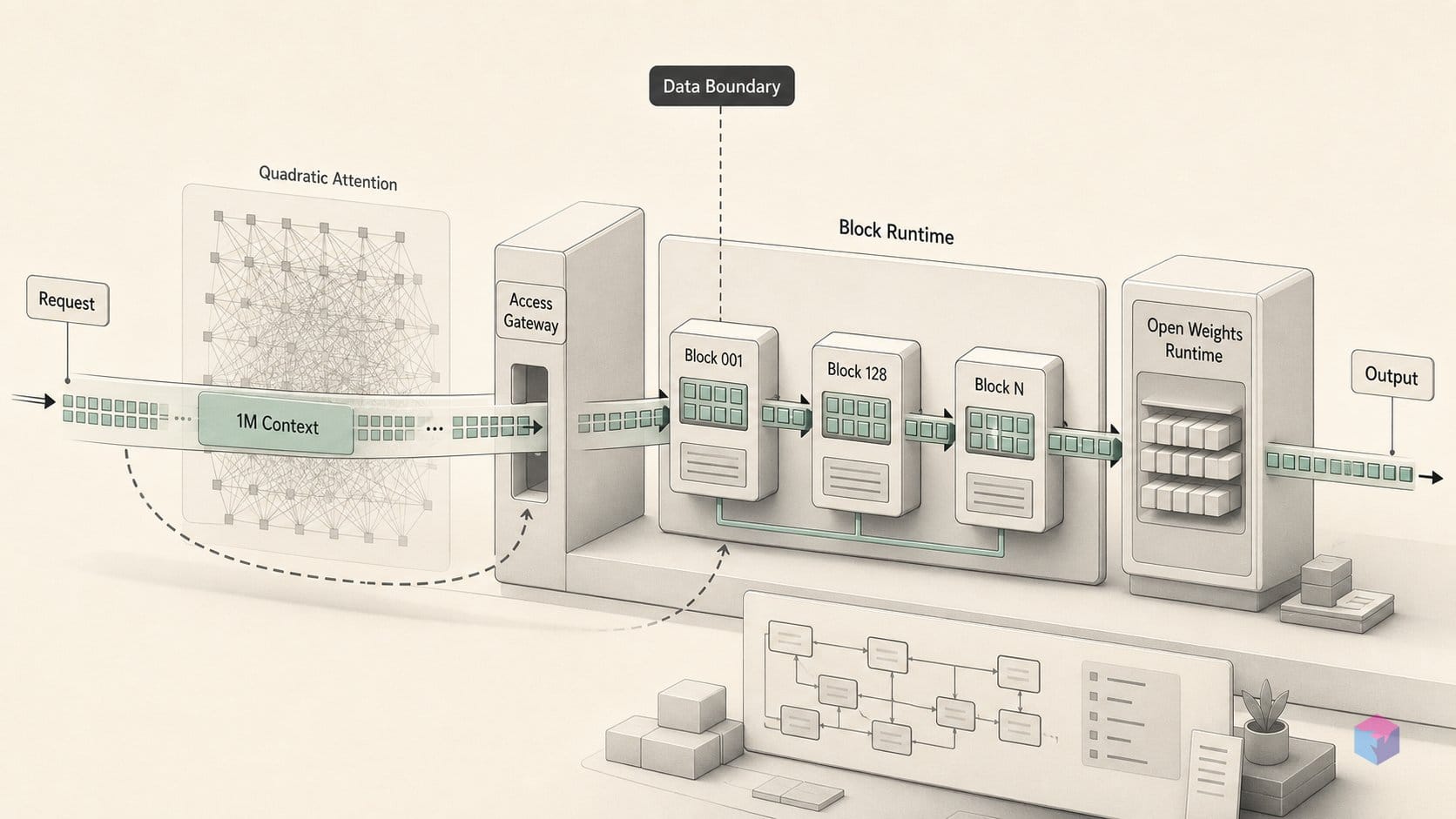
100만 토큰 윈도우를 경제적으로 구현하는 핵심은 MiniMax 희소 어텐션(MSA)입니다. 이는 표준 이차 풀 어텐션을 대체하는 블록 단위 희소 어텐션 방식입니다. 표준 어텐션은 O(n²)으로 확장됩니다. 시퀀스 길이가 두 배로 늘면 연산량은 네 배가 되므로, 100만 포지션에서는 어텐션 항 자체만으로도 현존하는 어떤 가속기에서도 감당하기 어려운 수준이 됩니다. MSA는 선형 어텐션 근사 방식에 의존하지 않고, 모든 토큰 쌍 대신 선택된 키-값 블록의 부분집합에만 어텐션을 수행함으로써 이 한계를 극복합니다 .
구체적으로 MSA는 그룹 쿼리 어텐션(GQA) 위에 구축되며 두 개의 브랜치로 동작합니다. 경량의 인덱스 브랜치가 GQA 그룹별 관련도를 점수화하여 상위 k개의 키-값 블록을 선택하고, 메인 브랜치가 선택된 블록들에 대해서만 정확한 블록 희소 소프트맥스 어텐션을 수행합니다 . 선택된 블록 내부에서는 정확한 연산이 이루어집니다. 소프트맥스를 근사하는 것이 아니라, 소프트맥스에 입력되는 블록의 범위를 제한하는 방식입니다.
처리량 측면에서 핵심은 선택이 토큰 단위가 아닌 블록 단위로 이루어진다는 점입니다. 블록 단위 접근은 GPU가 연속된 메모리를 읽는 방식에 자연스럽게 대응하므로, 희소 커널이 토큰 수준 가지치기에서 발생하는 분산되고 불규칙한 메모리 접근 대신 병합된(coalesced) 로드를 수행할 수 있습니다. 이것이 토큰 수준 가지치기 및 선형 어텐션 방식과의 구조적 차이입니다. MSA는 더 저렴한 근사 방식이 아닌 정확한 어텐션 수식을 유지하면서도 메모리 접근 패턴을 통해 성능을 확보합니다 .
관련 수치는 2026년 6월 11일 제출된 MSA 기술 보고서(arXiv:2606.13392)에서 가져온 것으로, 1,090억 파라미터 규모의 네이티브 멀티모달 모델을 기준으로 평가했습니다. 보고서에 따르면 100만 포지션 기준으로 GQA 대비 토큰당 어텐션 연산량이 28.4배 감소하면서도 품질이 유지되었으며, H800 하드웨어에서 프리필 14.2배, 디코드 7.6배의 실제 처리 속도 향상이 확인되었습니다 . 이 수치는 출시된 M3 모델 카드의 수치와 혼동하지 않아야 합니다. 모델 카드의 수치는 100만 토큰 컨텍스트 기준 M2 대비 프리필 약 9배, 디코드 약 15배 속도 향상, 토큰당 연산량 약 1/20 감소이며, 이는 다른 모델을 기준으로 측정된 것입니다 .
| 방식 | 어텐션 확장성 | 소프트맥스 입력 범위 | 100만 컨텍스트에서의 동작 |
|---|---|---|---|
| 풀 어텐션 | O(n²) | 모든 토큰 쌍 | 기준값; 컨텍스트 두 배마다 연산량 4배 증가 — 현실적으로 불가 |
| GQA | O(n²), KV 헤드 수 감소 | 모든 토큰 쌍, KV 그룹 공유 | KV 메모리는 줄지만 이차 연산 항은 유지 |
| MSA | 블록 선택으로 준선형 | GQA 그룹별 상위 k개 KV 블록에 대한 정확한 소프트맥스 | GQA 대비 어텐션 연산량 ~28.4배 감소, 품질 유지 |
커널 재사용을 계획 중인 분들을 위한 주의사항: 공개된 MSA 저장소는 NVIDIA SM100을 타겟으로 하며 dense FlashAttention과 sparse top-k 경로를 사용하고, CUDA와 Linux x86_64가 필요합니다. 범용 드롭인 런타임이 아닌 인프라 수준의 구현이므로 해당 스택을 이미 사용하는 경우에는 유용하지만, 그렇지 않은 경우에는 활용도가 낮을 수 있습니다 .
M3의 파라미터 비율: 총 4,280억 개, 활성화 230억 개
M3는 총 약 4,280억 개의 파라미터를 보유하되 포워드 패스당 약 230억 개만 활성화하는 MoE(Mixture-of-Experts) 모델로, 활성화 비율은 약 5.4%입니다 . 쉽게 말하면, 라우터가 대용량 저장소를 유지하면서도 각 토큰마다 그중 일부만 실행합니다. 덕분에 토큰당 한계 연산량은 낮게 유지되면서도, 전작보다 훨씬 많은 전문화된 학습 역량을 활용할 수 있습니다. 전작인 M2는 총 2,300억 개 파라미터 중 100억 개를 활성화하고 컨텍스트는 약 20만 5,000개였습니다 . M3는 총 용량을 약 두 배로 늘리고 활성화 파라미터도 두 배 이상 확장했으며, 컨텍스트 상한을 1,048,576 토큰까지 끌어올렸습니다.
MiniMax는 이러한 규모 확장과 함께 모델 카드에서 속도 관련 주장도 제시합니다. 1M 위치 용량 기준 M2 대비 M3는 프리필 속도 약 9배, 디코드 속도 약 15배, 위치당 연산량 약 1/20 수준이라고 밝히고 있습니다 . 이는 독립 검증이 이루어지지 않은 벤더 수치입니다. 별도의 1,090억 파라미터 모델에서 측정한 arXiv 논문의 28.4배 연산량·14.2배/7.6배 실시간 수치와는 다른 값이므로 혼동하지 마십시오. 해당 릴리스를 다룬 리뷰어들은 자체 타이밍 측정 없이 '디코드 약 15배'라는 수치를 그대로 인용하고 있습니다(영상: Binary Verse AI).
호스팅 API가 아닌 어텐션 커널을 직접 재사용할 계획이라면 기대치를 신중히 조율해야 합니다. 공개된 MSA 커널(MiniMaxAI/MiniMax-Text-01-MSA)은 NVIDIA SM100(Blackwell)을 타깃으로 하는 밀집형 FlashAttention과 희소 top-k 경로를 제공하며, BF16/FP8/NVFP4/FP4 수치 경로를 지원하고 Linux x86_64에서만 동작합니다. 해당 스택에서는 유용한 인프라이지만 범용 드롭인 대체품은 아닙니다 . 가중치 자체는 59개 safetensors 샤드에 걸쳐 분산된 약 854GB 아티팩트이므로, M3를 서빙하려면 단일 가속기가 아닌 멀티 GPU 클러스터가 필요합니다 .
| 사양 | MiniMax M2 | MiniMax M3 |
|---|---|---|
| 총 파라미터 | 2,300억 | ~4,280억 |
| 토큰당 활성화 파라미터 | 100억 | ~230억 (~5.4%) |
| 최대 컨텍스트 위치 | ~20만 5,000 | 1,048,576 (1M) |
| API 입력 가격 (≤512K, /M 토큰) | $0.50 | $0.30 |
| API 출력 가격 (≤512K, /M 토큰) | $2.20 | $1.20 |
가격 비교는 주목할 만합니다. 파라미터가 약 두 배임에도 M3의 ≤512K 할인 요금($0.30 입력 / $1.20 출력, 백만 토큰당)은 M2의 $0.50 / $2.20보다 저렴합니다. MoE 희소성과 MSA가 이를 경제적으로 가능하게 합니다 . 512K 초과 입력의 경우 요금이 $0.60 / $2.40으로 두 배가 되며, MiniMax는 해당 구간이 현재 제한적으로 제공된다고 밝히고 있습니다.
M3 리더보드 성적 해석: MiniMax 자체 보고, 독립 재현 대기 중
M3의 모든 주요 벤치마크는 벤더가 직접 실행한 결과이므로, 독립적인 재현이 이루어지기 전까지는 MiniMax의 자체 주장으로 받아들여야 합니다. 대표 수치는 SWE-Bench Pro 59.0%로, MiniMax에 따르면 GPT-5.5(~58.6%)와 Gemini 3.1 Pro를 소폭 앞서면서 Claude Opus(~69.2%)에는 뒤처집니다 . 방법론적 세부 사항이 중요합니다. 해당 실행은 MiniMax 인프라에서 Claude Code 스캐폴딩을 사용해 "공식 방법론에 맞춰" 진행됐으며, 회사가 선택한 기준 모델을 사용했습니다 . 에이전틱 평가에서는 스캐폴딩과 기준 선택만으로도 점수가 수 포인트 달라질 수 있어, GPT-5.5 대비 0.4포인트 우위는 하네스 선택이 만드는 노이즈 범위 안에 충분히 들어옵니다.
한눈에 보기: M3 벤치마크는 잠정적 수치로 취급하세요. MiniMax는 자체 인프라에서 선택된 기준 모델을 사용해 SWE-Bench Pro 59.0%(vs. GPT-5.5 ~58.6%, Opus ~69.2%), BrowseComp 83.5%를 보고했습니다. Artificial Analysis와 LMArena 평가는 발행 시점에 아직 결과가 나오지 않은 상태였습니다 .
전체 성적표는 전 항목 압도가 아닌 엇갈린 양상을 보입니다. MiniMax 모델 페이지에 따르면 BrowseComp 83.5%(Opus 4.7의 79.3 상회), Terminal-Bench 2.1 66.0%, MCP Atlas 74.2%, OSWorld-Verified(컴퓨터 사용) 약 70.0%, SVG-Bench 63.7%(Opus 상회 주장)를 기록했습니다 . 그러나 PostTrainBench에서는 37.1로 Opus 4.7(42.4)과 GPT-5.5(39.3)에 이어 3위에 그쳤습니다 . 한 벤치마크에서는 1위, 다른 벤치마크에서는 3위인 모델은 실제 릴리스의 전형적인 모습이지, 완벽한 압승이 아닙니다.
에이전틱 시연은 동료 검토를 거친 결과가 아닌 예시적 사례입니다. 18번의 커밋과 23개 그림을 포함한 ICLR 2025 논문 12시간 재현 실험과, 1,959번의 도구 호출을 기록하며 하드웨어 활용률이 7.6%에서 71.3%로 상승한 약 24시간의 CUDA FP8 GEMM 실행이 이에 해당합니다 . 장기 작업에서의 지속성은 보여주지만, 실시간 검색에서 이를 독립적으로 재현한 페이지는 발견되지 않았습니다(영상: The AI Reporter).
"M3는 핵심 벤치마크에서 비용의 5~10% 수준으로 독점 모델 선두권과 대등하거나 이를 앞선다" — VentureBeat (source: VentureBeat).
개발자 관점의 실질적 해석: 발행일 기준 독립적인 재현은 전무했으며, Artificial Analysis와 LMArena도 아직 결과를 게시하지 않은 상태였습니다 . 서드파티 수치가 나오기 전까지는 "GPT-5.5/Gemini를 능가한다"는 모든 헤드라인을 벤더 주장으로 받아들이고, 마이그레이션 전 자신의 워크로드로 직접 검증하는 것이 바람직합니다.
M3의 지원 입력: MP4 동영상, PNG/JPEG, 적응형 리플렉션
M3의 Anthropic 호환 API는 text, image, video, tool-use, tool-result, thinking 등 여섯 가지 콘텐츠 블록 유형을 지원합니다. M2.x는 text와 tool-call 블록만 허용했던 것과 대조적입니다 . 이미지·동영상 입력은 이번 세대에서 실질적으로 새롭게 추가된 기능으로, 기존 M2 래퍼에서 모델 이름만 바꾼다고 멀티모달리티가 자동으로 활성화되지 않습니다. 새로운 블록 유형을 직접 전송해야 합니다.
입력 제한은 구체적이며, 프로덕션에서 문제가 생기기 전에 유효성 검사에 반영해 두는 것이 좋습니다:
- 이미지: URL 또는 base64, JPEG/PNG/GIF/WEBP, 파일당 최대 10 MB .
- 동영상: MP4/AVI/MOV/MKV 인라인 최대 50 MB, Files API 경유 시 최대 512 MB .
- 요청 본문: 전체 요청에 64 MB 상한 적용 .
실질적인 시사점은 이렇습니다. 64 MB 요청 본문 상한이 512 MB 동영상 제한보다 낮으므로, 인라인 크기를 초과하는 클립은 메시지 페이로드에 포함하지 않고 반드시 Files API를 통해 전달해야 합니다. 장편 영상을 분석할 계획이라면, 파이프라인 중간에 한계에 부딪히기 전에 처음부터 청킹과 파일 참조 방식을 설계에 반영하세요. Binary Verse AI가 M3의 100만 토큰 멀티모달 파이프라인을 다룬 워크스루는 이러한 입력이 실제로 어떻게 동작하는지 살펴보기에 유용한 참고 자료입니다 (video: Binary Verse AI).
리플렉션(thinking) 동작도 변경되었습니다. M3에서는 thinking 출력이 기본적으로 비활성화되어 있으며, thinking type: 'adaptive'를 통해 켤 수 있습니다 . 이는 extended thinking을 비활성화할 수 없었던 M2.x와 실질적으로 다른 동작 방식입니다 . 따라서 thinking 블록이 항상 등장한다고 가정하거나 방어적으로 파싱하던 래퍼는 배포 전에 M3를 대상으로 재검증해야 합니다. 광범위한 포맷 정렬 덕분에 Claude API 클라이언트는 대부분 M3를 드롭인 대체재로 사용할 수 있지만, 다음 주의사항은 반드시 고려해야 합니다: 새로운 미디어 블록 유형, 자산별·요청 본문 제한, 그리고 이제 선택적으로 바뀐 thinking 출력.
minimax-community 라이선스: 상업적 귀속 표시와 2,000만 달러 통지 조항

M3의 가중치는 OSI 승인 라이선스가 아닌 minimax-community 라이선스로 배포됩니다. 여기서 '오픈 웨이트'란 다운로드 가능하다는 의미이지 무제한 사용을 뜻하지 않습니다. 비상업적 이용은 무료이지만, 상업적 이용에는 두 가지 필수 조건이 따릅니다. 제품 UI 또는 문서에 "Built with MiniMax M3"를 표시해야 하며, 연간 매출이 미화 2,000만 달러를 초과하는 상업적 사용자는 MiniMax에 일회성 통지를 하거나 사전 서면 승인을 받아야 합니다 . 출시 전에 두 조건 모두 준비해 두세요.
귀속 표시 요건은 많은 팀이 선택적 브랜딩으로 오해하는 부분입니다. 그렇지 않습니다. "Built with MiniMax M3" 문구는 라이선스 조건이므로, 이를 생략한 상업용 제품은 모델을 아무리 가볍게 사용하더라도 라이선스 위반 상태가 됩니다. 2,000만 달러 조항은 초기 스타트업보다는 성장 단계의 제품을 겨냥한 좁은 범위의 조항입니다. 해당 연간 총매출 기준 이하에서는 통지 의무가 발생하지 않지만, 이를 초과하는 제품은 MiniMax에 일회성 서면 통지를 하거나 사전 서면 승인을 받아야 하며, 라이선스에는 전문을 읽어야 할 금지 사용 조항도 포함되어 있습니다 .
이 지점에서 M3는 허용적 라이선스와 크게 갈립니다. Apache 2.0과 MIT는 UI 내 귀속 표시 의무나 매출 기준 통지 절차 없이 서브라이선스·수정·재배포가 가능합니다. minimax-community는 두 가지 모두 깔끔하게 허용하지 않습니다. 기술 창업자를 위한 실질적 조언은 이렇습니다. M3의 조건을 커스텀 커뮤니티 라이선스로 취급하고, 진정한 오픈소스가 아닌 소스 공개 도구를 다루듯 엔터프라이즈 프로덕션 배포 전에 법무 검토를 거치세요.
관할권도 따져볼 두 번째 축입니다. MiniMax는 상하이 기반 연구소이며, 호스팅 API는 중국 관할권 하에서 운영됩니다. 이는 일부 워크로드에서 중국의 2017년 국가정보법이 데이터 거버넌스 고려 사항으로 적용될 수 있음을 뜻합니다 . 이에 대한 대응책은 릴리스 모델 자체에 내재되어 있습니다. 가중치를 자체 호스팅하면 프롬프트와 데이터가 MiniMax 엔드포인트에 전혀 전송되지 않으므로, 민감한 워크로드에서 해당 리스크를 원천 차단할 수 있습니다.
VentureBeat가 정리한 핵심 가치 명제에 따르면, M3는 주요 벤치마크에서 독점 모델과 대등하거나 앞서는 성능을 "비용의 단 5~10%"에 제공한다고 포지셔닝되었습니다 . 그러나 상업적 배포를 고려한다면, 이 비용 계산은 귀속 표시 의무, 2,000만 달러 통지 조항, 관할권 문제를 따로 떼어 보지 않고 함께 검토해야 합니다.
M3 셀프호스팅: 854 GB, 59개 Safetensors 샤드, SGLang 또는 Docker
API 호출 대신 셀프호스팅을 선택했다면, 가중치의 공식 출처는 Hugging Face입니다 — GitHub이 아닌 MiniMaxAI/MiniMax-M3 저장소가 기준입니다. 저장소 트리에는 약 854 GB 용량이 59개 safetensors 샤드(model-00001-of-00059부터 model-00059-of-00059까지)로 분할되어 있습니다 . 이 규모만 봐도 API 래퍼가 아닌 진짜 대용량 아티팩트 다운로드임을 알 수 있으며, 벤치마크를 보기 전에 하드웨어 최저 사양부터 확인해야 합니다.
문서 간 불일치에도 주의하세요. MiniMax-AI GitHub README에는 M3가 아직 출시되지 않았다고 명시되어 있으며 M2.7을 안내하고 있어, GitHub은 구버전이거나 프리릴리즈 상태인 반면 실제 릴리즈는 Hugging Face에서 이루어지고 있습니다 . 배포 안내는 Hugging Face 저장소 README에 포함되어 있으며, Transformers·vLLM·SGLang·Docker Model Runner를 모두 다룹니다 . 처리량 중심 서빙에는 SGLang 또는 vLLM을, 빠르게 로컬 스모크 테스트를 돌리고 싶다면 Docker Model Runner를 선택하세요.
문제는 스파스 어텐션 커널에 있습니다. 공개된 MSA 커널은 Blackwell 아키텍처인 NVIDIA SM100을 대상으로 하며, Python 3.10 이상, CUDA nvcc 툴체인, Linux x86_64 환경이 필요합니다 . 구형 Ampere 또는 Hopper 노드에서는 공개된 스파스 경로를 그대로 실행할 수 없으므로, 속도 향상 수치는 Blackwell급 실리콘을 전제로 한 것입니다. 그에 맞는 예산을 확보하거나, API를 계속 이용하세요.
가격 면에서 호스팅 API는 하위 구간에서 저렴하게 유지됩니다. 512K 토큰 이하 입력에는 할인율이 적용되어 입력 백만 토큰당 $0.30, 출력 백만 토큰당 $1.20, 프롬프트 캐시 읽기 백만 토큰당 $0.06이며, 512K 초과 입력에는 각각 $0.60, $2.40, $0.12로 오릅니다 . MiniMax는 512K 초과 구간의 용량이 현재 제한적이라고 밝히고 있어 , 백만 토큰 전체 컨텍스트 윈도우를 프로덕션에서 안정적으로 기대하기는 아직 이릅니다.
실용적인 결론은 이렇습니다. 짧은 컨텍스트의 코딩·에이전트 작업이라면 $0.30/$1.20의 API가 마찰 없이 시작할 수 있는 출발점입니다. 관할권·귀속 문제 또는 지속적인 1M 토큰 처리량이 Blackwell 하드웨어 비용과 854 GB 다운로드를 정당화할 때만 셀프호스팅을 검토하세요 — 그리고 GitHub은 아직 최신 상태가 아니므로 Hugging Face를 기준으로 스캐폴딩을 고정하세요.
자주 묻는 질문
MSA는 표준 트랜스포머 어텐션과 어떻게 다른가요?
표준 풀 어텐션은 모든 토큰 쌍에 대해 쌍별 내적을 계산하며 O(n²)로 확장됩니다 — 토큰이 두 배가 되면 연산량은 네 배가 됩니다. MiniMax Sparse Attention(MSA)은 대신 경량 인덱스 브랜치를 실행하여 GQA(그룹화된 쿼리 어텐션) 그룹별로 상위 k개의 키-값 블록을 사전 선택한 뒤, 선택된 블록에 대해서만 정확한 블록-스파스 소프트맥스를 수행합니다. 선택이 토큰 단위가 아닌 블록 단위로 이루어지므로 연속적인 GPU 메모리 접근에 깔끔하게 매핑되며 이차 확장 문제를 피할 수 있습니다. MSA 논문(arXiv:2606.13392, 2026년 6월 11일 제출)은 GQA 기준 대비 1M 위치에서 토큰당 어텐션 연산량이 28.4배 감소함을 측정하며, 품질은 유지된다고 보고합니다.
MiniMax M3는 정말 오픈소스인가요?
아닙니다 — M3는 오픈소스가 아닌 오픈 웨이트입니다. 가중치는 비상업적 용도로 무료로 다운로드할 수 있지만, minimax-community 라이선스에 따라 상업용 제품은 "Built with MiniMax M3"를 표시해야 하며, 연간 매출이 US$20 million을 초과하는 제품이나 서비스는 일회성 고지 또는 사전 서면 승인이 필요합니다. OSI 인증을 받지 않았으므로 공식적인 오픈소스 정의를 충족하지 않습니다. 실용적인 주의사항 하나: GitHub README가 오래되어 이전 릴리스를 가리키고 있으므로, 공식 다운로드 위치는 Hugging Face(MiniMaxAI/MiniMax-M3)입니다.
M3 자체 호스팅에 필요한 하드웨어 사양은?
M3를 직접 호스팅하려면 59개 safetensors 샤드에 걸쳐 약 854GB를 받아와 멀티 GPU 클러스터(예: H800 여러 장 또는 동급 사양)에서 실행해야 합니다. MoE(Mixture-of-Experts) 설계는 포워드 패스당 428B 파라미터 중 ~23B만 활성화하여 연산량을 줄이지만, 라우터가 모든 전문가에 접근할 수 있도록 428B 전체 가중치가 메모리에 상주해야 합니다. 일반 소비자용 그래픽 카드나 단일 노드 워크스테이션에서는 실행이 불가능합니다. Transformers, vLLM, SGLang, Docker 배포 경로는 배포 노트를 참조하세요.
M3의 벤치마크 결과는 독립적으로 검증되었나요?
2026년 6월 발표 시점 기준으로는 그렇지 않습니다. 공개된 모든 점수 — SWE-Bench Pro 59.0%, BrowseComp 83.5%, PostTrainBench 37.1, OSWorld-Verified ~70% — 는 MiniMax 자체 인프라에서 회사가 선택한 스캐폴딩과 기준으로 산출된 것입니다. Artificial Analysis와 LMArena의 독립 평가는 출시 보도 기준으로 아직 진행 중이었습니다. 제3자 수치가 공개될 때까지 "GPT-5.5 및 Gemini 3.1 Pro 능가" 주장은 잠정적인 것으로 받아들이시기 바랍니다.
512K 토큰 초과 프롬프트의 요금은?
입력 토큰이 512K를 초과할 경우, M3의 할인 API 요금은 입력 100만 토큰당 $0.60, 출력 100만 토큰당 $2.40, 프롬프트 캐시 읽기 100만 토큰당 $0.12입니다. 512K 이하의 입력은 요금이 절반인 $0.30 / $1.20 / $0.06으로 낮아집니다. MiniMax는 512K 초과 등급을 한시적 제한 용량으로 설명하며, 조만간 더 넓은 공개 이용이 가능해질 것으로 예상합니다. 비교하자면, 이전 모델 M2는 최대 컨텍스트 ~205K 토큰에서 $0.50 / $2.20으로 운영되었습니다(동영상: AICodeKing).








