
. That mid-600s figure is the useful calibration point: a working journalist with a real public footprint lands well below the icons, not near them.
The slight gap between the 996 and 988 figures likely reflects leaderboard movement between the two articles, or different reference points; the live site is the only authoritative source for current scores .
The score is not one model's opinion. In the Weights queries more than ten systems in parallel and condenses the spread into the final number, placing frontier and compact open-weight models side by side:
- Frontier proprietary: Grok, Gemini, GPT-5.5, and Claude Opus 4.8
- Smaller proprietary: a GPT-5.4 Mini variant
- Open-weight: Meta's Llama series, GLM, and Qwen3 8B
Running them together is the point: the same name can score high on a large model and vanish on a small one, and that contrast is what the next section unpacks .
| Reference point | Approx. strength score | What it tells you |
|---|---|---|
| Leaderboard ceiling (Mozart, Shakespeare, Taylor Swift) | 996 | Globally memorized across every model queried |
| Macaulay Culkin (launch-week top entry) | 988 | A-list recognition, still just shy of the ceiling |
| Anthony Ha (TechCrunch writer) | 641 | Mid-tier public figure, roughly top 6% |
| Common or misspelled name | Low / ambiguous | Model cannot disambiguate; results collapse |
| Private individual | ~0 | Not present in the weights at all |
Read the number as a confidence proxy, not a reputation grade. A 641 says four-plus frontier and open models recall the name without browsing; a near-zero says the weights hold nothing to recall.
Why a compact 7B model knowing you is a stronger signal
A compact model recalling your name is worth more than a frontier model doing the same, because small models simply have less room to memorize. An 8-billion-parameter open model like Qwen3 8B holds a tiny fraction of the facts a frontier system carries, so the people it retains are skewed toward the most globally prominent subset .
This is the asymmetry In the Weights is built around. Appearing in a small open model such as Qwen3 8B or GLM implies cross-cultural, high-volume memorization: your name survived aggressive compression. Appearing only in a large model like GPT-5.5 or Claude Opus 4.8 may just reflect broad long-tail coverage, where the model had spare capacity to retain a marginal entity .
The site's composite scoring reflects that logic directly: recall from a smaller model boosts the overall strength figure disproportionately, because the creators treat compact-model presence as the stronger evidence of relevance . Two people with identical web footprints can land far apart if one survives into the open-weight tier and the other does not.
Read across model tiers, the memorization signal roughly stacks like this:
| Model tier | Example models | Who tends to survive | Signal if recalled |
|---|---|---|---|
| Compact (≈7B-8B, open-weight) | Qwen3 8B, GLM | Globally famous: composers, historical figures, top celebrities | Strongest: scarce capacity, high bar |
| Mid-range | GPT-5.4 Mini, Llama series | Well-documented public figures, notable founders, journalists | Moderate, meaningful but broader |
| Frontier (large) | GPT-5.5, Claude Opus 4.8, Gemini, Grok | Long-tail entities: niche professionals, regional figures | Weakest: broad coverage dilutes the signal |
It explains why a near-ceiling score is hard to fake. Names at the top of the leaderboard (Mozart, Shakespeare, Taylor Swift, all near the 996 maximum) are recalled everywhere, including the small models that ration their memory hardest . For most builders and creators, the practical takeaway is to watch the compact tier: it is the threshold that separates true cross-model memorization from incidental long-tail coverage.
GEO vs. SEO: your AI footprint is frozen, not crawlable
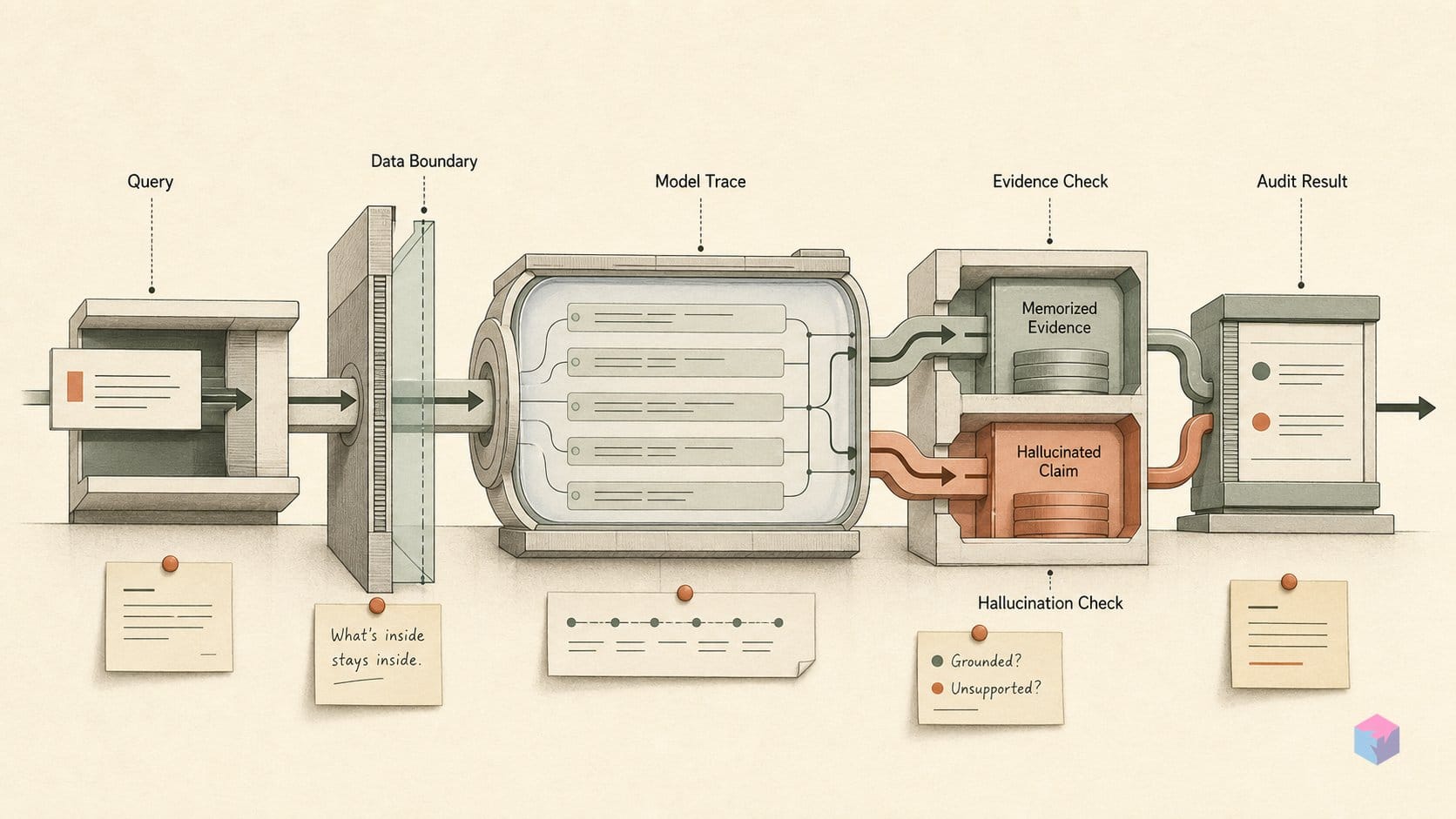
The reason that compact-tier threshold matters so much is structural: an AI footprint behaves nothing like a search footprint. SEO runs on a live index. You publish a post, earn a link, wait for a re-crawl, and the loop closes in days to weeks. Model memorization is frozen at the training cutoff: the knowledge baked into released weights does not move when you publish, no matter how much you publish .
That distinction is the whole point of measuring weights instead of the web. A Google vanity search reads a constantly-updated index; In the Weights probes parameters that were locked at pre-training and will stay locked until the next model ships . The web can be re-crawled on demand. Weights cannot.
So the refresh cycles diverge sharply:
- Web/SEO: a new page or backlink propagates through the index in days to weeks. The feedback loop is short and on demand.
- Weights/GEO: nothing you publish today changes a shipped model. Only a future pre-training run or a fine-tune can revise its picture of you, and that cadence is months to years out, not a button you press .
- Lag: a person who became notable after a model's cutoff is effectively invisible to that model until the next training cycle catches up, regardless of how strong their live web presence is.
The creators frame the whole tool around this shift in attention from search engines toward LLMs, and they are explicit that presence in weights is a separate asset from presence on the web, as The Decoder notes in its launch write-up . As TechCrunch puts it in its first-hand review, the exercise reframes the old 'Google yourself' habit into a new question: not what the web says about you, but what the model has memorized.
For anyone building a public presence (founders, journalists, researchers), the takeaway is operational: your online footprint and your AI footprint are two distinct assets that drift apart over time and need separate strategy. Optimizing one does not feed the other on the same clock. You can dominate the live index this quarter and remain absent from a frontier model until its next training run lands.
Confidence ≠ truth: where hallucinations enter
A high strength score tells you the model is confident, not that it is correct. In the Weights measures conviction, and conviction and accuracy are different variables. The creators are explicit on this point: the figure is a proxy for how strongly a model recalls a name, never a verified account of who that person is . Treat it as a signal, not a source.
The failure modes are concrete. When TechCrunch ran the tool, GPT-5.4 Mini described 'Anthony Ha', a real working journalist, as 'an ambiguous name form that could refer to multiple people with the initials A.H.A.' . That is a confident disambiguation failure: the model did not lack data so much as fail to resolve which person the name pointed to.
Common names amplify this. The model cannot pick the right individual without context it does not possess, so it merges several people into one blurred description or hedges into ambiguity . Two distinct failure paths follow:
- Merging: multiple real people collapse into a single confident profile, mixing biographies that belong to different individuals.
- Hedging: the model declines to commit, returning a low or near-zero figure even for someone genuinely present in the weights.
Input fragility is the other trap. A typo drags the figure sharply downward: a single misspelling can return near-zero even for a globally prominent name, because the model is matching surface tokens, not the underlying identity . The same person scores high or invisible depending on spelling.
None of this exposes how a fact entered the weights, either. The tool cannot separate memorized training data from confident confabulation, as The Decoder notes in its launch coverage: the system 'does not distinguish memorized facts from hallucinated ones, only how sure the model sounds' . For builders auditing their own footprint, the practical rule is simple: read the score as confidence, then verify the model's actual claims yourself.
What the gap between online presence and AI footprint means

The gap between your online presence and your AI footprint is a timing problem: the web updates continuously, but model weights freeze at the training cutoff and only refresh when a new model is trained. So your AI footprint lags your online footprint by roughly one full training cycle, often months of drift between who you are now and what the model 'knows.' In the Weights, launched June 19-20, 2026 by ex-OpenAI builders Thomas Dimson and Joey Flynn , makes that lag legible by scoring confidence rather than recency.
That distinction reshapes the playbook depending on who you are:
- Journalists and founders publishing consistently: expect the model to trail your real output. Recent work and role changes simply will not register until the next pre-training run incorporates them.
- Newer voices with strong SEO: high search rank does not imply memorization. You can dominate a results page and still score near zero, and the model may have no idea who you are until it is retrained.
- Anyone with a common name: disambiguation is a structural hard problem. The site may blend several people into one confusing cluster, and a frontier model like GPT-5.4 Mini will hedge. It reportedly tagged "Anthony Ha" as an "ambiguous name form that could refer to multiple people with the initials A.H.A."
The actionable angle is GEO timing. Because weights are frozen, anything you want a future model to recall has to land in widely-scraped, high-authority sources before the next training cutoff: peer-reviewed papers, high-DA publications, and Wikipedia carry the most weight; a blog post added after the cutoff does nothing for that generation .
The takeaway: treat your In the Weights score as a lagging indicator, not a verdict. Build durable citations in sources models actually ingest, verify the claims those models make about you, and accept that closing the gap is measured in training cycles, not in your next deploy.
Frequently asked questions
What does 'In the Weights' actually measure?
It measures how strongly a large language model has memorized a specific person purely from pre-training: no web crawl, no browsing, no external tools, just the knowledge baked into the model's parameters . The output is a single confidence figure running from 0 up to a near-1000 ceiling, with the top globally famous names (Mozart, Shakespeare, Taylor Swift) reported at 996 . A confident appearance means the model considered you relevant enough during training to recall you without tools.
How is the confidence figure calculated?
Each model receives a structured prompt (roughly 'Who is <name>? Give up to 10 results, each with a short description and confidence'), and the site clusters similar descriptions together before condensing them into a per-model strength score . Several models are queried in parallel, spanning frontier systems and smaller open-weight ones, and the results combine into one site-level figure . Live numbers shift slightly across outlets, so the site itself is the only authoritative source for a current score.
Does a high figure mean the AI has accurate information about me?
No. Confidence and accuracy are independent: a model can be confidently wrong, hallucinating biographical details even at high scores. The creators are explicit that a high figure is not evidence the model's account of you is correct, only that the model is sure . The figure measures memorization strength, not reliability, and the tool cannot distinguish genuine training data from confident confabulation . Always verify the specific claims a model makes about you.
Why does appearing in a smaller model indicate stronger relevance?
Compact open-weight models such as Qwen3 8B hold far fewer facts and retain only the most globally prominent entities, so being recalled by one is a stronger memorization signal than appearing in a massive frontier system . A large frontier model covers broad long-tail knowledge, so it recognizes many minor figures; a 7B-8B model has to budget its limited capacity on whoever matters most. In the Weights treats that scarcity as a relevance filter, weighting small-model recall more heavily.
Can I improve my figure by publishing more content?
Not directly: weights are frozen at training cutoff, so fresh content does nothing for the current model generation. New material only helps if a future model is trained on it, which makes the score a lagging indicator measured in training cycles, not in your next deploy . The practical move is to build durable, high-authority citations in widely-scraped sources before the next training run, not after.









