
The dominant way large language models produce text — one token at a time, strictly left to right — is not the only way. Inception's Mercury 2, announced February 24, 2026, drops that constraint entirely, and the throughput numbers it reports are the reason developers should look closely.
Diffusion Decoding: Why Mercury 2 Skips Left-to-Right Prediction
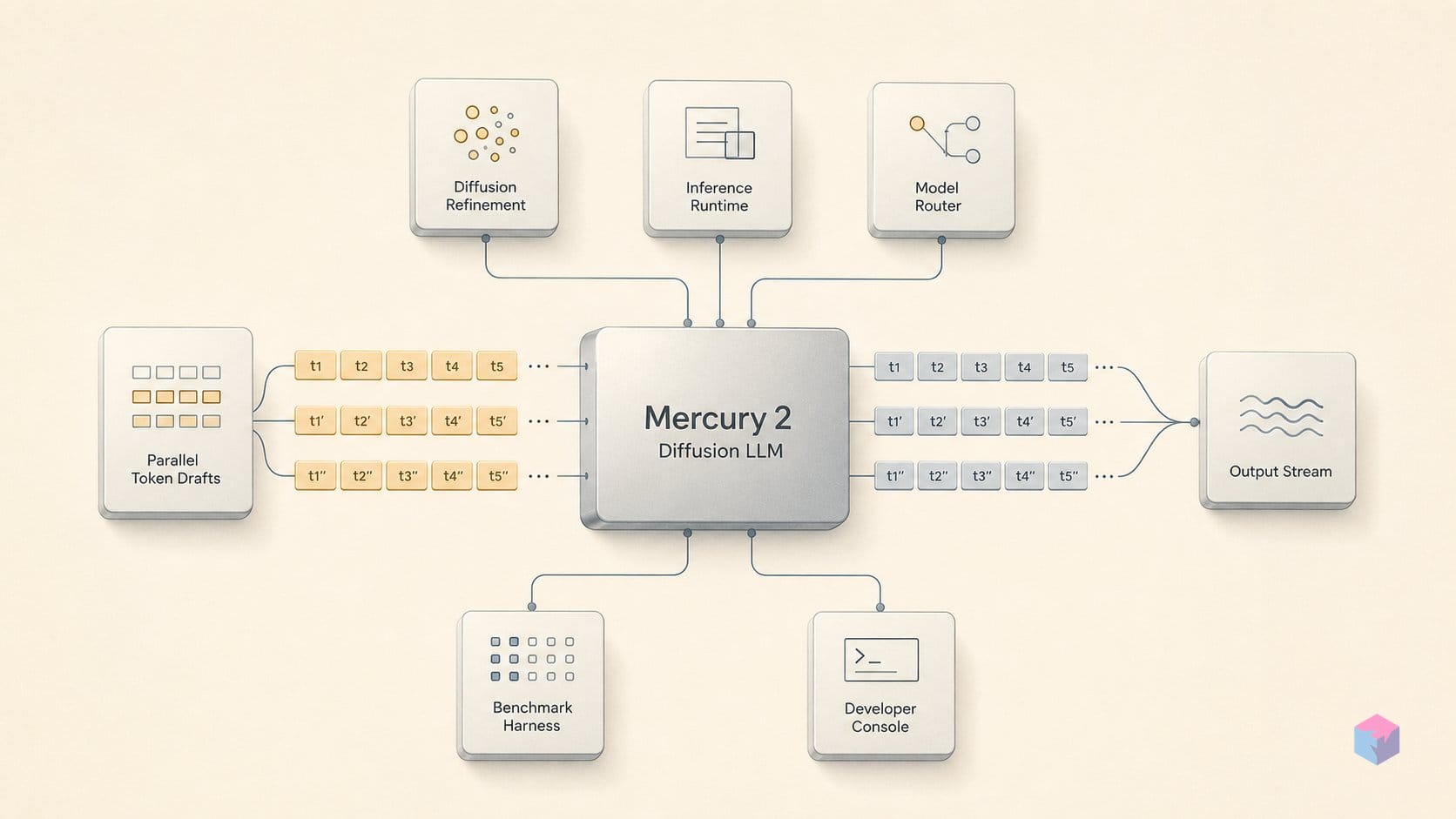
Mercury 2 is a diffusion-based large language model: instead of predicting the next token sequentially, it starts from a fully masked or noisy sequence and iteratively denoises every position in parallel across a small, fixed number of forward passes until the output converges. Inception reports it reaches more than 1,000 tokens/sec — specifically 1,009 tok/s on NVIDIA Blackwell GPUs — versus the roughly 100 tok/s typical of frontier autoregressive models . That speed gap is the entire thesis of the product.
The architecture is still a Transformer. What changes is the generation objective: each denoising pass refines the whole output simultaneously rather than appending to a partial answer. This is the coarse-to-fine convergence principle behind image generators like Stable Diffusion, applied to text — Inception describes Mercury as a Transformer-based diffusion LLM trained to predict multiple tokens in parallel until the sequence stabilizes . The model does not produce a token and then condition the next one on it; it updates many positions per forward pass.
At the call level, this distinction is concrete. An autoregressive model emits a partial response and extends it; Mercury 2 converges on a complete answer. That difference even surfaces in the streaming API: setting diffusing: true streams intermediate denoising states rather than incremental token deltas, a product-level signal that generation here is structurally different from a standard streaming text endpoint . You watch the answer resolve, not type out.
One open question deserves flagging up front, because the rest of this thesis hinges on it. Parallel position updates do not imply unconstrained output, but convergence behavior and quality at short sequence lengths differ from next-token prediction. The tradeoff tends to appear in certain reasoning chains, and diffusion LLMs carry a known structural cost — training inefficiency relative to autoregressive models, even when inference is faster . Whether that speed translates into a real deployment edge depends on workload shape, concurrency, prompt length, and the quality bar you set — the questions the following sections work through.
The 1,009/s Figure: Where Inception's Claim Comes From
The 1,009 tokens/sec headline comes from Inception's own reporting on NVIDIA Blackwell GPUs, citing Artificial Analysis evaluations — a vendor-cited measurement, not a fully independent replication . The number sits in a lineage: the June 2025 technical report measured Mercury Coder Mini at 1,109 tok/s on H100 GPUs , and Mercury 2 carries the same throughput-first framing onto newer hardware. Model weights, parameter counts, and the full training corpus are not disclosed in the official sources, so the speed claim rests on those evaluation harnesses rather than on a reproducible open artifact.
What makes the figure legible is the gap at the capability tier Mercury 2 targets. In the same Inception-reported comparisons, GPT-4o Mini runs around 59 tok/s and Claude 3.5 Haiku around 61 tok/s — roughly a 17× difference against models in the same small-and-fast bracket. Inception frames Mercury 2's reasoning scores as competitive with Claude 4.5 Haiku and GPT-5.2 Mini while delivering about an order of magnitude more throughput .
The reported benchmark scores (Inception-sourced) are AIME 2025 ~91.1, GPQA ~73.6, IFBench ~71.3, LiveCodeBench ~67.3, and SciCode ~38.4 . Read them as the vendor's own quality positioning, not as third-party verification.
| Metric | Mercury 2 | GPT-4o Mini | Claude 3.5 Haiku |
|---|---|---|---|
| Throughput (tok/s) | ~1,009 (Blackwell) | ~59 | ~61 |
| AIME 2025 | ~91.1 | n/a | n/a |
| GPQA | ~73.6 | n/a | n/a |
| LiveCodeBench | ~67.3 | n/a | n/a |
| Output price (per 1M) | $0.75 | n/a | n/a |
Throughput and benchmark figures are Inception-reported via Artificial Analysis; comparator throughput from Inception's Mercury comparisons .
"Fastest reasoning LLM" is the label Inception attaches to the launch — vendor positioning, not a formal benchmark category. The most credible independent signal to date predates Mercury 2: in Copilot Arena, Mercury Coder Mini placed second on quality and first on latency at about 0.25 seconds . That is a head-to-head test users rank, not a self-reported throughput number — useful as a directional read on whether the speed advantage survives outside Inception's harness, even if it doesn't yet cover the Mercury 2 generation directly.
What diffusing: true Reveals in Mercury's Intermediate States
Mercury 2 ships behind an OpenAI-compatible API, so the switch is mostly a config change, not a rewrite. The official docs assign model ID mercury-2 to the standard v1/chat/completions route , which means existing OpenAI SDK code points at Inception's base URL and runs unchanged for normal completions. The diffusion mechanics from the previous sections stay hidden behind the same request and response shapes developers already use.
The one API behavior that exposes the underlying model is the diffusing: true streaming flag. With it set, the server streams each intermediate denoising state rather than incremental token deltas . That is a meaningful difference: a standard streaming client expects monotonic token-by-token growth, while Mercury emits successively refined drafts of the whole sequence. Practically, it gives you two things — a way to observe and debug convergence behavior, and a way to drive a typing indicator that reflects actual generation instead of faking progress with a spinner.
Mercury Edit 2 is a separate product, not a drop-in for chat. It carries model ID mercury-edit-2 and exposes v1/fim/completions for fill-in-the-middle and v1/edit/completions for next-edit prediction . Its context window is 32K, against 128K for Mercury 2 chat — a reminder that the editing model targets local code spans, not long conversational state.
Pricing is identical across both models, which simplifies budgeting. Inception lists:
- $0.25 per 1M input tokens
- $0.025 per 1M cached input tokens
- $0.75 per 1M output tokens
New API accounts also receive 10 million free tokens — enough headroom to benchmark diffusing: true against your own latency targets before committing.
Mercury Edit 2: Fill-in-the-Middle and KTO-Aligned Selectivity
Mercury Edit 2 is a diffusion LLM purpose-built for next-edit prediction, launched March 30, 2026 . Instead of completing a single span left-to-right, it ingests recent edits plus surrounding codebase context and generates candidate edits in parallel through diffusion. Inception reports the model improves accepted edits by 48% and is 27% more selective in the edits it displays after preference alignment . That second number matters as much as the first for IDE work.
The selectivity gain comes from a KTO step. KTO — Kahneman-Tversky Optimization — aligns the model on human preference feedback to favor fewer, higher-confidence suggestions rather than maximizing the number of completions shown (video: AI Revolution). For editor integration this is the practical lever: suggestion fatigue is a real adoption constraint, and a model that surfaces three accurate edits beats one that surfaces ten you have to dismiss. The 27% higher selectivity is directionally the right tradeoff for tools where every wrong popup trains users to ignore the next one .
Mercury Edit 2 exposes two endpoints under model ID mercury-edit-2: v1/fim/completions for fill-in-the-middle and v1/edit/completions for next-edit prediction . The FIM endpoint takes a standard prefix/suffix structure, so it drops into existing autocomplete plumbing with little change. The next-edit endpoint is the more distinctive one: it is designed for editors where the surrounding edit stream provides implicit context, so you do not hand-build a prompt describing what the user just changed — the recent diffs are the signal.
Context is 32K for both FIM and next-edit modes, narrower than Mercury 2's 128K chat window because the model targets local code spans rather than long conversational state . Worth noting the 48% and 27% figures are self-reported and tied to Inception's own preference dataset, so treat them as vendor-framed until independent editor benchmarks land.
Bull vs Bear: When Diffusion Decoding Wins and When It Doesn't
Diffusion decoding wins decisively on high-concurrency, latency-bound workloads and loses ground wherever frontier reasoning depth or self-hosted control matters more than speed. The bull case rests on a measurable throughput gap: Inception cites 1,009 tokens/sec for Mercury 2 on NVIDIA Blackwell GPUs against the roughly 100 tokens/sec typical of frontier autoregressive models . At comparable benchmark scores, that becomes a cost-per-request argument, not just a latency one.
The workloads that benefit most are the ones built from many short, repeated calls where every millisecond and every token is billed at scale:
- Autocomplete and next-edit prediction — sub-second responses are the product, and Mercury Coder Mini already ranked first on latency at about 0.25 seconds in Copilot Arena .
- Agentic loops — chains that fire dozens of model calls per task compound any per-call latency saving.
- Real-time voice, RAG summarization, and structured extraction — throughput and schema compliance dominate the quality bar here, not deep multi-step reasoning.
For routing and extraction specifically, Mercury 2's 128,000-token context window paired with native JSON-schema structured output makes it a plausibly drop-in replacement . When you need a router to return a valid enum fast, frontier reasoning is overkill and Mercury's throughput is the deciding factor.
The bear case is structural. Diffusion language models carry a known training-inefficiency penalty — they cost more compute to reach the same capability as an autoregressive model, a tradeoff Inception itself acknowledges (video: AI Marketing Navigator). As one industry framing of the architecture puts it:
"The inference speed-up is real, but it's bought with training inefficiency — that's the diffusion tax," — paraphrasing the tradeoff discussed in Inception's own briefing (source: AI Marketing Navigator).
That tax constrains how aggressively Inception can iterate on fine-tuning or ship custom data adapters.
The deeper problem for builders is verifiability. Model weights, parameter counts, and full training-corpus details were not disclosed in the official sources . That makes independent benchmark replication impossible, fine-tuning feasibility unassessable, and self-hosted inference-cost estimation a dead end. The entire verification chain — AIME 2025 near 91.1, GPQA near 73.6, LiveCodeBench near 67.3 — rests on trusting Inception-sourced evaluations plus a thin layer of Artificial Analysis and Copilot Arena citations. For latency-bound work that's an acceptable bet; for anything requiring auditability or on-prem control, it is the line where diffusion stops winning.
What to Migrate and What to Leave Autoregressive

Migrate the workloads where p95 latency is the binding constraint and AIME/GPQA-tier quality clears your floor; leave autoregressive everything that depends on long, interdependent reasoning chains or proprietary fine-tuning. Mercury 2 runs near 1,009 tokens/sec on Blackwell against roughly 100 tok/s for frontier autoregressive models , so the migration question is purely about whether your task tolerates parallel denoising over strict left-to-right conditioning.
Quick Answer: Move high-volume autocomplete, fill-in-the-middle, 50+ call agentic loops, voice routing, and structured extraction to Mercury 2 when p95 latency under 250ms is the constraint. Keep deep reasoning chains and fine-tuned workloads autoregressive — Mercury 2 fine-tuning is not offered, and output runs $0.75 per 1M tokens .
The clear migration candidates are latency- and cost-bound: high-volume coding autocomplete, fill-in-the-middle, refactoring, agentic loops that fire 50-plus repeated calls per session, real-time voice routing, RAG, summarization, and structured extraction — the workload shapes Inception itself targets . These share a profile: many small calls where shaving per-call latency compounds, and where AIME 2025 near 91.1 and LiveCodeBench near 67.3 are enough .
Leave autoregressive the cases where the model's edge doesn't help. Long chains of interdependent reasoning, where each step conditions heavily on prior output, fit left-to-right generation better than parallel refinement. Anything needing proprietary fine-tuning is out — Mercury 2 fine-tuning is not available. And frontier-quality open-ended creative work sits above the band Mercury 2 advertises as "competitive range" rather than best-in-class.
The decision heuristic is concrete: if your p95 latency budget per call is under 250ms and a quality floor of AIME ~91 / LiveCodeBench ~67 covers you, Mercury 2 is worth a direct A/B at $0.75 per 1M output tokens against your current provider . Otherwise, the autoregressive default still earns its place.
| Workload type | Recommended approach | Latency signal | Quality floor | Fine-tuning |
|---|---|---|---|---|
| High-volume coding autocomplete / FIM | Mercury 2 (Edit 2) | p95 < 250ms | LiveCodeBench ~67 sufficient | Not available |
| Agentic loops, 50+ calls/session | Mercury 2 | Latency × call count dominates | AIME ~91 sufficient | Not available |
| Real-time voice routing / RAG / extraction | Mercury 2 | p95 binding | GPQA ~73 sufficient | Not available |
| Long interdependent reasoning chains | Autoregressive | Latency secondary | Step-on-step accuracy critical | As provider allows |
| Domain-specific tuned models | Autoregressive | Variable | Custom | Required |
| Frontier creative / open-ended | Autoregressive | Latency secondary | Above competitive band | As provider allows |
| Mixed pipelines | Hybrid (route by call) | Per-stage | Per-stage | Per-stage |
Mercury 2 on AWS SageMaker, Azure Foundry, and Inception's Own Signup
Mercury 2 reaches builders through three routes, and the route you pick changes both latency and billing. The direct path is Inception's own OpenAI-compatible endpoint at inceptionlabs.ai, which grants 10 million free tokens on signup and keeps Mercury 1 available for existing customers who have not migrated . For teams that want managed infrastructure instead, the two major clouds carry the family.
- AWS: Mercury and Mercury Coder have been available via Amazon Bedrock Marketplace and SageMaker JumpStart since August 27, 2025, with no model-deployment management required and per-token billing at AWS-side rates; AWS lists up to 1,100 tokens/sec on H100 GPUs and 128,000 tokens of context .
- Azure AI Foundry: offered in US and Canada regions with a $0.78/hour software license (compute billed separately), a recommended ND-H100-v5 instance, plus tool calling and JSON-schema structured outputs .
One practical caveat before you commit to a cloud-hosted route: the managed infrastructure layer adds its own network and orchestration overhead, so the throughput you see will sit below Inception's direct numbers. If the 1,009 tokens/sec figure on Blackwell is the reason you are evaluating at all , run a concurrency test that matches your real call shape — prompt length, batch size, and target quality — on each route before standardizing. The takeaway: treat the headline speed as the ceiling Inception's own engine reaches, then benchmark your chosen host against it rather than assuming the number travels.
Frequently asked questions
What is a diffusion language model and how does it differ from autoregressive?
A diffusion language model (dLLM) generates text by starting from a masked or noisy full-length sequence and iteratively denoising all positions in parallel over a small, fixed number of forward passes — the coarse-to-fine principle behind image generators like Stable Diffusion, applied to text. Autoregressive models work the opposite way: they predict one token at a time, strictly left-to-right, requiring roughly N forward passes for N tokens. Mercury 2 keeps a Transformer backbone but swaps the decoding loop, predicting multiple tokens per pass until the output converges . The practical consequence is throughput: parallel denoising is what lets Inception cite figures far above token-by-token generation.
What does migration to Mercury 2 require in existing code?
For chat completions, almost nothing structural. Mercury 2 runs behind an OpenAI-compatible API, so you swap the model ID to mercury-2, point your base URL at Inception's endpoint, and standard OpenAI SDK code keeps working against v1/chat/completions . Add diffusing: true only when you want the stream to expose intermediate denoising states rather than plain token deltas . Mercury Edit 2 is not a drop-in for chat: it uses separate endpoint paths (v1/fim/completions and v1/edit/completions) for fill-in-the-middle and next-edit prediction, so IDE-style integrations target those routes specifically.
How does Mercury 2's AIME 91.1 compare to GPT-5.2 Mini and Claude Haiku?
Inception positions Mercury 2 within competitive range of the Haiku/Mini tier on reasoning evals: AIME 2025 about 91.1, GPQA about 73.6, and LiveCodeBench about 67.3, framed as comparable in quality to Claude 4.5 Haiku and GPT-5.2 Mini . The divergence is speed: roughly 1,009 tok/s on Blackwell GPUs versus near 100 tok/s for frontier autoregressive models at a similar capability tier . Treat the benchmark numbers as Inception-sourced — no fully independent replication is available yet, so the quality claim is less verified than the throughput one.
What capabilities does Mercury 2 add beyond raw prediction?
Beyond fast token generation, Mercury 2 ships native tool use, JSON-schema structured output, a 128,000-token context window, and tunable reasoning depth, all behind an OpenAI-compatible chat API . That feature set targets latency- and cost-bound workloads — agentic loops, RAG, routing, and structured extraction — rather than pure text completion. For editor workflows, the companion Mercury Edit 2 adds fill-in-the-middle and next-edit prediction through separate endpoints, with a 32K context window for those modes .
What does Inception omit from the Mercury 2 technical report?
The transparency gaps matter for due diligence. Inception has not released model weights, disclosed the parameter count, or detailed the training corpus in the official sources reviewed, so independent verification rests largely on cited Artificial Analysis and Copilot Arena evaluations . The 1,009 tok/s headline comes from Inception-cited benchmarks, not independent replication, and "fastest reasoning LLM" is vendor positioning rather than a formal benchmark category . Note also that the public arXiv report (2506.17298) covers the earlier Mercury Coder family — Mercury 2 specifics lean on the February 2026 launch announcement .









