
MiniMax shipped a model that does something most open-weight releases avoid: it pairs a million-token context with native multimodality and agentic coding in one artifact — and replaces the attention mechanism that usually makes that combination too expensive to run.
What Is MiniMax M3?
MiniMax M3 is a natively multimodal, open-weight Mixture-of-Experts model released on June 1, 2026 . It carries roughly 428B total parameters with about 23B activated per token, and accepts up to 1,048,576 (2^20) positions — a window made affordable by MiniMax Sparse Attention (MSA), a blockwise sparse mechanism rather than standard quadratic full attention .
Quick Answer: MiniMax M3 is an open-weight Mixture-of-Experts model (~428B total / ~23B activated) released June 1, 2026, with a 1,048,576-token context built on blockwise sparse attention, native text/image/video input, and an Anthropic-compatible API priced from $0.30 per million input tokens.
The model is multimodal in a single request. The Anthropic-compatible API accepts JPEG/PNG/GIF/WEBP images up to 10 MB and MP4/AVI/MOV/MKV video up to 50 MB inline (or 512 MB via the Files API), alongside text and tool-use blocks . The API is live at platform.minimax.io with a guaranteed 512K-token minimum context, and standard usage starts at $0.30 per million input and $1.20 per million output tokens for inputs up to 512K . Subscription tiers run $20 (Plus), $50 (Max), and $120 (Ultra) per month .
M3 succeeds MiniMax M2, the late-2025 compact coding model with 10B activated / 230B total parameters, roughly a 205K-position window, and pricing of $0.50/$2.20 per million tokens . The jump is structural: M2 scored just below Claude Sonnet 4.5 on Artificial Analysis indices, and M3 raises both context length and modality coverage while activating roughly double the parameters per token. Whether its frontier benchmark claims hold up is a separate question — every headline number at launch was vendor-run, with independent replication still pending.
How MSA Replaces Quadratic Attention: The Block-Selection Method
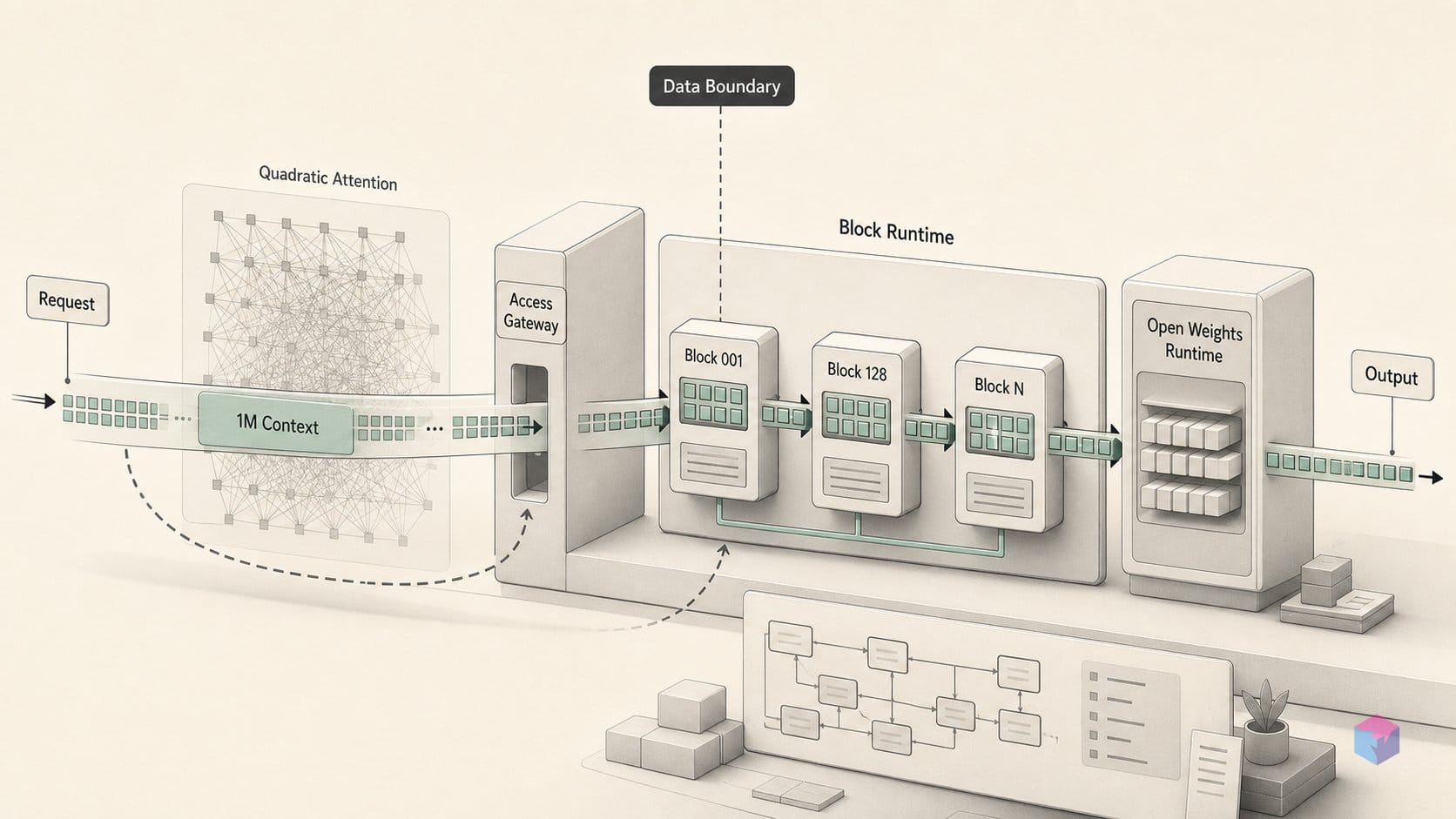
The mechanism that makes a million-token window economical is MiniMax Sparse Attention (MSA), a blockwise sparse attention scheme that replaces standard quadratic full attention. Standard attention scales O(n²): doubling the sequence length quadruples the compute, so at 1M positions the attention term alone becomes prohibitive on any current accelerator. MSA sidesteps that wall by attending to a selected subset of key-value blocks rather than every token pair, and it does so without dropping to a linear-attention approximation .
Mechanically, MSA is built on grouped-query attention (GQA) and runs in two branches. A lightweight index branch scores relevance per GQA group and selects the top-k key-value blocks; a main branch then performs exact block-sparse softmax attention only over those selected blocks . The selection is exact within the chosen blocks — this is not an approximation of the softmax, only a restriction of which blocks enter it.
The detail that matters for throughput is that selection happens at the block level, not the token level. Block granularity maps onto how GPUs read contiguous memory, so the sparse kernel issues coalesced loads instead of the scattered, irregular gathers that token-level pruning produces. That is the structural difference from both token-level pruning and linear-attention methods: MSA keeps exact attention math and wins on memory-access patterns rather than on a cheaper approximation .
The supporting numbers come from the MSA technical report, arXiv:2606.13392, submitted June 11 2026 and evaluated on a 109B-parameter natively multimodal model. It reports per-token attention compute reduced 28.4x at 1M positions versus GQA while preserving quality, plus 14.2x prefill and 7.6x decode wall-clock speedups on H800 hardware . Keep these distinct from the shipped M3 model card's own figures — ~9x faster prefill, ~15x faster decode versus M2 at 1M context, cutting per-token compute to roughly 1/20 — which were measured on a different model and should not be conflated with the paper's .
| Approach | Attention scaling | What enters the softmax | Behavior at 1M context |
|---|---|---|---|
| Full attention | O(n²) | Every token pair | Baseline; compute quadruples per context doubling — prohibitive |
| GQA | O(n²), fewer KV heads | Every token pair, shared KV groups | Lowers KV memory but keeps quadratic compute term |
| MSA | Near-linear via block selection | Exact softmax over top-k selected KV blocks per GQA group | ~28.4x less attention compute than GQA, quality preserved |
One caveat for anyone planning to reuse the kernels: the public MSA repository targets NVIDIA SM100 with dense FlashAttention and sparse top-k paths, requires CUDA and Linux x86_64, and is infrastructure rather than a universal drop-in runtime — useful if you already build on that stack, less so otherwise .
M3's Parameter Ratio: 428B Total, 23B Activated
M3 is a Mixture-of-Experts model with ~428B total parameters and ~23B activated per forward pass, an activation ratio near 5.4% . In plain terms: the router holds a large capacity reserve but only fires a small slice of it for each token, so marginal compute per token stays low while the model can draw on far more learned specialization than its predecessor. That predecessor, M2, ran 10B activated of 230B total with a ~205K context . M3 roughly doubles total capacity and more than doubles activated parameters, then pushes the context ceiling to 1,048,576 tokens.
MiniMax pairs that scale-up with speed claims on its model card: versus M2 at 1M-position capacity, M3 is said to deliver ~9x faster prefill, ~15x faster decode, and per-position compute cut to roughly 1/20th . These are vendor figures, not independently verified — note they are distinct from the arXiv paper's 28.4x compute and 14.2x/7.6x wall-clock numbers measured on a separate 109B model, and the two sets should not be conflated. Reviewers covering the release have repeated the ~15x decode framing without independent timing of their own (video: Binary Verse AI).
If you intend to reuse the attention kernels rather than the hosted API, scope expectations carefully. The public MSA kernel (MiniMaxAI/MiniMax-Text-01-MSA) ships dense FlashAttention plus sparse top-k paths targeting NVIDIA SM100 (Blackwell), with BF16/FP8/NVFP4/FP4 numeric paths, and runs on Linux x86_64 only — useful infrastructure on that exact stack, not a general-purpose drop-in . The weights themselves are a ~854 GB artifact spread across 59 safetensors shards, so serving M3 means a multi-GPU cluster, not a single accelerator .
| Spec | MiniMax M2 | MiniMax M3 |
|---|---|---|
| Total parameters | 230B | ~428B |
| Activated per token | 10B | ~23B (~5.4%) |
| Max context positions | ~205K | 1,048,576 (1M) |
| API input price (≤512K, /M tokens) | $0.50 | $0.30 |
| API output price (≤512K, /M tokens) | $2.20 | $1.20 |
The pricing comparison is notable: despite roughly double the parameters, M3's discounted ≤512K rates ($0.30 input / $1.20 output per million tokens) undercut M2's $0.50 / $2.20 — the MoE sparsity and MSA are what make that economically possible . Above 512K input, rates double to $0.60 / $2.40, and MiniMax describes that tier as limited for now.
How to Read M3's Leaderboard Standings: MiniMax-Reported, Awaiting Replication
Every headline benchmark for M3 is vendor-run, so read the standings as MiniMax's own claims pending independent replication. The flagship number is SWE-Bench Pro at 59.0%, which MiniMax says edges GPT-5.5 (~58.6%) and Gemini 3.1 Pro while trailing Claude Opus (~69.2%) . The methodological detail matters: those runs executed on MiniMax infrastructure using Claude Code scaffolding "aligned to official methodology," against company-selected baselines . On agentic evals, scaffolding and baseline choice can move scores by several points, so a 0.4-point lead over GPT-5.5 sits well inside the noise that harness selection introduces.
Quick Answer: Treat M3's benchmarks as provisional. MiniMax reports SWE-Bench Pro 59.0% (vs. GPT-5.5 ~58.6%, Opus ~69.2%) and BrowseComp 83.5%, all run on its own infrastructure with chosen baselines. Artificial Analysis and LMArena evaluations were still pending at publication .
The fuller scorecard is mixed rather than uniformly dominant. MiniMax's model page reports BrowseComp 83.5%, placing it above Opus 4.7's 79.3, alongside Terminal-Bench 2.1 at 66.0%, MCP Atlas at 74.2%, OSWorld-Verified (computer use) at ~70.0%, and SVG-Bench at 63.7% (claimed to surpass Opus) . On PostTrainBench, though, M3 lands at 37.1 — third, behind Opus 4.7 (42.4) and GPT-5.5 (39.3) . A model that leads one benchmark and ranks third on another is the normal shape of a real release, not a clean sweep.
The agentic demonstrations are illustrative, not peer-reviewed: a 12-hour ICLR 2025 paper reproduction (18 commits, 23 figures) and a ~24-hour CUDA FP8 GEMM run logging 1,959 tool calls while hardware utilization climbed from 7.6% to 71.3% . They show endurance on long-horizon tasks, but no independent page reproducing them surfaced in live search (video: The AI Reporter).
"M3 matches or beats proprietary leaders on a key benchmark at 5–10% of their cost" — VentureBeat (source: VentureBeat).
The practical read for developers: there was zero independent replication at publication date, and Artificial Analysis and LMArena had not yet posted results . Until those third-party numbers land, treat every "beats GPT-5.5/Gemini" headline as a vendor claim worth testing on your own workload before migrating.
M3's Accepted Inputs: MP4 Video, PNG/JPEG, Adaptive Reflection Support
M3's Anthropic-compatible API accepts six content block types — text, image, video, tool-use, tool-result, and thinking — where M2.x accepted only text and tool-call blocks . Image and video inputs are genuinely new in this generation, so existing M2 wrappers will not automatically gain multimodality by swapping the model name; you have to send the new block types yourself.
The input limits are specific and worth wiring into validation before they bite you in production:
- Images: URL or base64, JPEG/PNG/GIF/WEBP, up to 10 MB each .
- Video: MP4/AVI/MOV/MKV up to 50 MB inline, or up to 512 MB via the Files API .
- Request body: a 64 MB ceiling sits over the whole request .
The practical consequence: that 64 MB request-body cap is below the 512 MB video limit, so anything beyond inline-sized clips has to go through the Files API rather than packed into the message payload. If you are analyzing long-form footage, plan for chunking and reference-by-file from the start instead of discovering the ceiling mid-pipeline. The Binary Verse AI walkthrough of M3's 1M-token, multimodal pipeline is a useful reference point for what these inputs look like in practice (video: Binary Verse AI).
The reflection (thinking) behavior also changed. In M3, thinking output is off by default and turned on via thinking type: 'adaptive' . That is a real behavior shift from M2.x, whose extended thinking could not be disabled — so any wrapper that assumed thinking blocks would always appear (or that parsed them defensively) should be retested against M3 before you ship. The upside of the broader format alignment is that Claude API clients can largely point at M3 as a drop-in, provided you account for these caveats: the new media block types, the per-asset and request-body limits, and the now-optional thinking output.
minimax-community License: Commercial Attribution and $20M Notification Clause

M3's weights ship under the minimax-community license, not an OSI-approved one — so "open-weight" here means downloadable, not unrestricted. Non-commercial use is free, but commercial use carries two hard conditions: products must display "Built with MiniMax M3" in their UI or documentation, and any commercial user exceeding US$20 million in yearly revenue must give MiniMax a one-time notice or obtain prior written authorization . Plan for both before you ship.
The attribution requirement is the part teams most often misread as optional branding. It is not: the "Built with MiniMax M3" string is a license condition, so a commercial product that omits it is out of compliance regardless of how lightly it uses the model. The $20M clause is narrower and aimed squarely at scaling products rather than early-stage startups — below that gross-revenue threshold the notice obligation does not trigger, but products crossing it owe MiniMax either a one-time written notice or prior written authorization, and the license also carries prohibited-use restrictions you should read in full .
This is where M3 diverges sharply from permissive licensing. Apache 2.0 and MIT let you sublicense, modify, and redistribute without an attribution-in-UI mandate or a revenue-gated notification step; minimax-community does neither cleanly. The practical takeaway for technical founders: treat M3's terms as a custom community license and route it through legal review before any enterprise production deployment, the same way you would a source-available tool rather than true open source.
Jurisdiction is the second axis worth weighing. MiniMax is a Shanghai-based lab, and its hosted API operates under Chinese jurisdiction — which brings China's 2017 National Intelligence Law into scope as a data-governance consideration for some workloads . The mitigation is built into the release model itself: self-hosting the weights keeps your prompts and data off MiniMax's endpoint entirely, removing that exposure for sensitive workloads.
As VentureBeat framed the broader value proposition, M3 was positioned as matching or beating proprietary leaders on a key benchmark "for just 5–10% of the cost" — but for any commercial deployment, that cost calculus has to be read alongside the attribution mandate, the $20M notice clause, and the jurisdiction question, not in isolation from them.
Hosting M3: 854 GB, 59 Safetensors Shards, SGLang or Docker
If you decide to self-host rather than call the API, the authoritative source for weights is Hugging Face — the MiniMaxAI/MiniMax-M3 repository, not GitHub. The repository tree lists roughly 854 GB split across 59 safetensors shards, model-00001-of-00059 through model-00059-of-00059 . That footprint confirms a genuine large-artifact download rather than an API wrapper, and it sets your hardware floor before you read a single benchmark.
Mind the documentation drift. The MiniMax-AI GitHub README still states M3 is not yet released and points to M2.7, so GitHub reads as stale or pre-release while Hugging Face is the live release location . Deployment instructions ship in the Hugging Face repository README, covering Transformers, vLLM, SGLang, and Docker Model Runner . Pick SGLang or vLLM for throughput serving; Docker Model Runner if you want the fastest path to a local smoke test.
The catch sits in the sparse-attention kernel. The public MSA kernels target NVIDIA SM100 — the Blackwell architecture — and require Python 3.10 or newer, the CUDA nvcc toolchain, and Linux x86_64 . Older Ampere or Hopper nodes cannot run the published sparse path as-is, so the headline speedups assume Blackwell-class silicon. Budget for that, or stay on the API.
On price, the hosted API stays cheap at the bottom tier. For inputs at or below 512K tokens, discounted rates are $0.30 per million input, $1.20 per million output, and $0.06 per million prompt-cache-read tokens; above 512K input, those rise to $0.60, $2.40, and $0.12 respectively . MiniMax describes the over-512K capacity as limited for now , so the full million-token window is not yet a dependable production guarantee.
The practical takeaway: for short-context coding and agentic work, the API at $0.30/$1.20 is the low-friction starting point. Reach for self-hosting only when jurisdiction, attribution, or sustained 1M-token throughput justify Blackwell hardware and an 854 GB pull — and pin your scaffolding to Hugging Face, since GitHub is not yet caught up.
Frequently asked questions
What makes MSA different from standard transformer attention?
Standard full attention computes pairwise dot-products across every token pair, scaling as O(n²) — double the tokens, quadruple the compute. MiniMax Sparse Attention (MSA) instead runs a lightweight index branch that pre-selects the top-k key-value blocks per grouped-query-attention (GQA) group, then performs exact block-sparse softmax only over those selected blocks. Because selection is block-level rather than token-level, it maps cleanly onto contiguous GPU memory access and sidesteps quadratic scaling. The MSA report (arXiv:2606.13392, submitted June 11, 2026) measures a 28.4x per-token attention-compute reduction at 1M positions versus a GQA baseline, while reporting preserved quality.
Is MiniMax M3 actually open-source?
No — M3 is open-weight, not open-source. The weights are freely downloadable for non-commercial use, but the minimax-community license requires commercial products to display "Built with MiniMax M3," and any product or service exceeding US$20 million in yearly revenue needs a one-time notice or prior written authorization. It is not OSI-certified, so it does not meet the formal open-source definition. One practical caveat: the GitHub README is stale and still points to an earlier release; the authoritative download location is Hugging Face (MiniMaxAI/MiniMax-M3).
How much hardware does self-hosting M3 require?
Self-hosting M3 means pulling roughly 854 GB across 59 safetensors shards and running it on a multi-GPU cluster — for example, several H800s or equivalent. The Mixture-of-Experts design activates only ~23B of 428B parameters per forward pass, which cuts compute, but the full 428B weight set must stay resident in memory so the router can reach every expert. This is not feasible on consumer cards or a single-node workstation. See the deployment notes for Transformers, vLLM, SGLang, and Docker paths.
Are M3's benchmark results independently verified?
Not as of publication in June 2026. Every published score — SWE-Bench Pro 59.0%, BrowseComp 83.5%, PostTrainBench 37.1, and OSWorld-Verified ~70% — was produced on MiniMax's own infrastructure with company-selected scaffolding and baselines. Independent evaluations from Artificial Analysis and LMArena were still pending per launch reporting. Treat the "beats GPT-5.5 and Gemini 3.1 Pro" claims as provisional until third-party numbers land.
What is the pricing for prompts over 512K tokens?
Above 512K input tokens, M3's discounted API rates are $0.60 per million input, $2.40 per million output, and $0.12 per million prompt-cache-read tokens. At or below 512K input, the rates halve to $0.30 / $1.20 / $0.06. MiniMax describes the >512K tier as limited capacity for a limited time, with broader public availability expected soon. For comparison, the prior M2 ran $0.50 / $2.20 with a ~205K-token maximum context (video: AICodeKing).








