
Spin up five coding agents on the same repo and the hard part isn't generation — it's landing all five sets of changes on main without one clobbering the next. A dedicated git worktree plus a merge queue is the pairing that makes that safe.
What does a dedicated worktree plus a merge queue give you?
A dedicated worktree plus a merge queue gives you two guarantees: parallel agents never overwrite each other's files while they work, and their branches integrate one at a time so conflicts surface in the open instead of silently corrupting trunk. The worktree handles isolation; the queue handles ordering. Together they convert chaotic concurrent edits into a sequence of reviewable git merges.
Quick Answer: A git worktree is a linked checkout that shares one object database but keeps its own HEAD and index, so edits in worktree-A never touch worktree-B's tracked files. A merge queue then serializes which branch lands first — and that ordering matters, because 27.67% of AI-agent PRs hit a merge conflict.
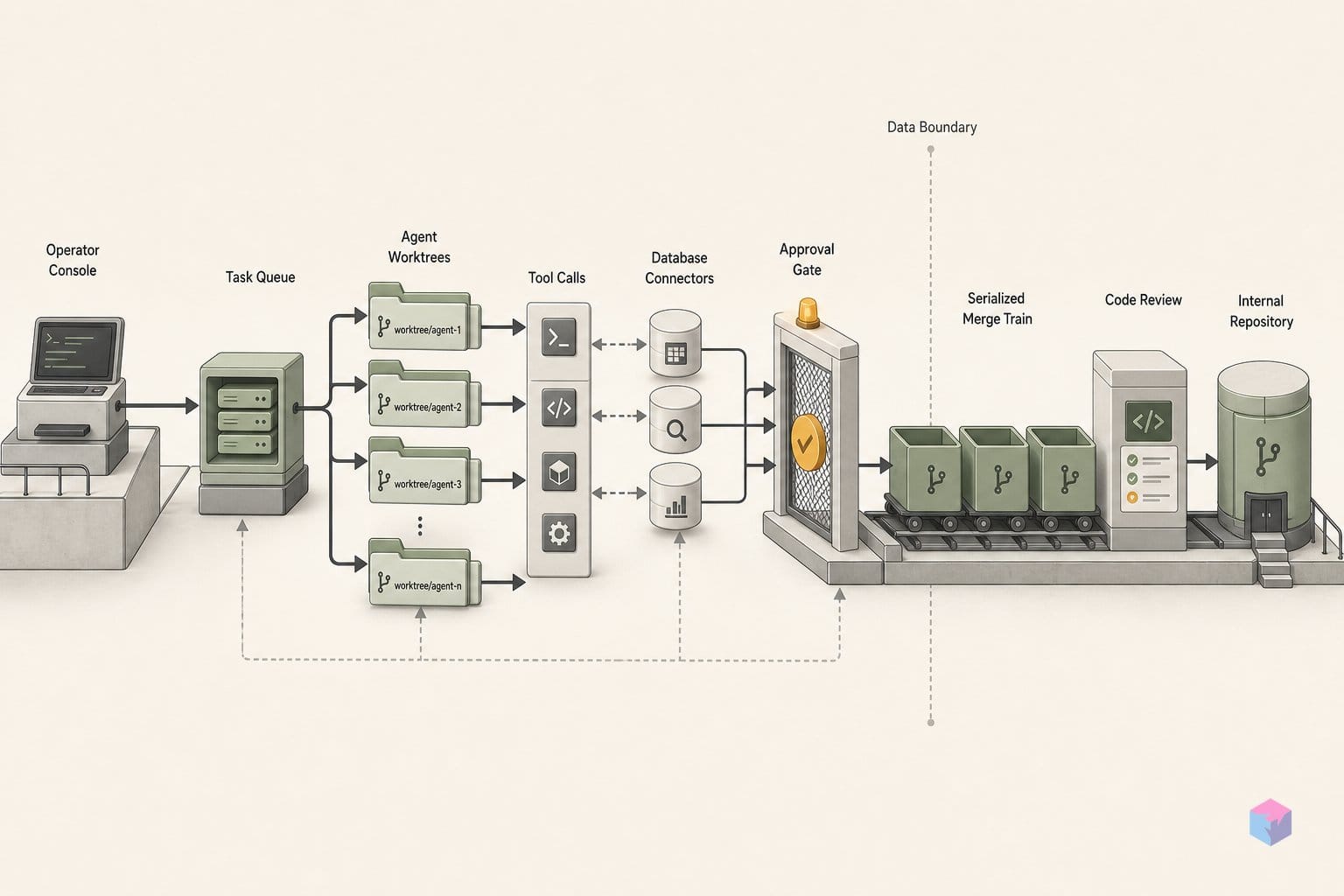
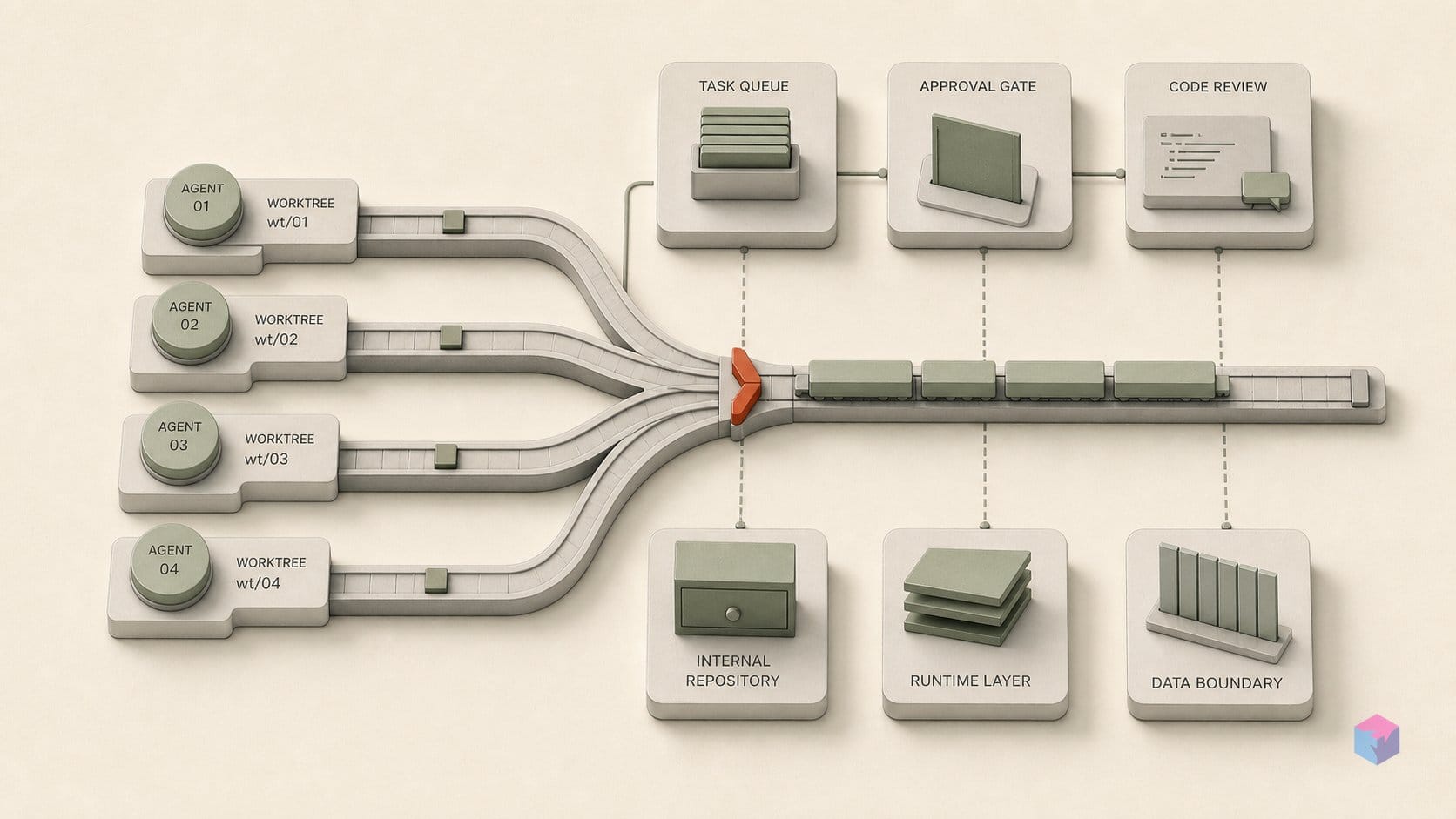
Start with isolation. A worktree is an official Git mechanism for attaching multiple working trees to a single repository: each linked worktree keeps its own per-worktree HEAD and index while sharing the one repository object database . Practically, each agent gets its own directory and branch, so two agents editing auth.py at the same moment never contend over a single index or lock — worktree-A's writes are invisible to worktree-B until integration .
That isolation changes the nature of a conflict rather than eliminating it. Because each agent commits to a separate branch, edits to the same file no longer collide live as file-lock races; the collision is deferred to merge time, where standard git tooling detects it and writes explicit conflict markers you can read and resolve. A latent runtime corruption becomes a visible, reviewable diff.
Anthropic's Claude Code documentation recommends exactly this setup. Running claude --worktree feature-auth creates a separate checkout on its own branch, so one session can build a feature while a second fixes a bug without colliding edits . Multiply that to four or five sessions and you have a fleet — but a fleet of branches still has to reach trunk.
That is the merge queue's job. A queue serializes admission: merge branch-1 first, and branch-2's pipeline now runs against a main that already contains branch-1's changes, so conflicts appear incrementally instead of in one tangled batch. GitHub's merge queue implements this for pull requests — FIFO order, validation against the latest base branch plus the PRs ahead, with build-concurrency and merge limits configurable from 1 to 100 . Worktrees keep the agents apart; the queue decides, deterministically, who lands first.
AgenticFlict's 27.67%: conflict frequency in AI-generated PRs
Roughly one in four AI-authored pull requests collides on merge. AgenticFlict — accepted at AIware 2026 — ran deterministic merge simulation over 107K+ AI-authored PRs drawn from 59K+ repositories and measured a 27.67% merge-conflict rate across 336K+ fine-grained conflict regions . That is the empirical case for isolation plus an ordered queue: conflicts are not an edge case in agent-driven development, they are the median outcome at scale.
The "deterministic merge simulation" detail matters for trusting the number. Rather than surveying self-reported friction, AgenticFlict replayed real branches through git's own merge machinery, so a conflict region is a region git actually refused to auto-resolve — not a heuristic estimate . The 142K+ AI-agent PRs the study started from were filtered to the 107K+ that could be cleanly simulated, which makes 27.67% a conservative floor rather than an inflated headline figure.
Scale is why this is a governance problem and not a curiosity. The AIDev dataset (submitted February 9, 2026) catalogs 932,791 agent-authored PRs across OpenAI Codex, Devin, GitHub Copilot, Cursor, and Claude Code, spanning 116,211 repositories and 72,189 developers . Apply AgenticFlict's rate to a volume like that and conflict resolution stops being a per-PR annoyance and becomes a recurring cost on the integration path that someone — or some merge train — has to absorb deterministically.
| Dataset | AI-authored PRs | Repositories | Headline finding |
|---|---|---|---|
| AgenticFlict (AIware 2026) | 142K+ analyzed, 107K+ merge-simulated | 59K+ | 27.67% conflict rate · 336K+ conflict regions |
| AIDev (Feb 9, 2026) | 932,791 | 116,211 | 5 agents (Codex, Devin, Copilot, Cursor, Claude Code) · 72,189 developers |
Is the rate evenly distributed across those five tools? The public figures do not break the 27.67% down by agent vendor or by repository-size bracket, so any per-tool conflict table would be invented rather than measured — worth flagging, because the collision mechanism is structural, not vendor-specific. Conflict surface area scales with repo-sharing: the more concurrent sessions write to the same codebase, the higher the probability that any two branches touch the same file and the same hunk. A single agent on a quiet repo rarely conflicts with itself; five agents fanned across a hot module are statistically likely to overlap regardless of which model wrote the code.
That reframes the headline. The 27.67% is not an indictment of any one coding agent — it is the expected output of parallel authorship without coordinated landing. Worktrees keep the writes apart, but they defer every one of those 336K+ conflicts to merge time. The open operational question is who resolves them and in what order, which is exactly the job a serialized merge train exists to do.
What CAID's coordinator-led decomposition achieved on PaperBench
CAID answers that operational question directly: a manager session decomposes the work, hands each subtask to a worker session running in its own isolated git worktree from main, and merges the resulting commits sequentially once each worker has self-verified. The paper — "Effective Strategies for Asynchronous Software Engineering Agents," submitted March 23, 2026 — reports that this structure beats a single-session baseline by 26.7 percentage points on PaperBench and 14.3 points on Commit0. The gains are attributed not to a stronger model but to centralized task delegation plus structured integration — the same two levers a serialized merge train pulls.
The conflict-handling policy is the part worth studying. When a worker's commit fails to merge cleanly, CAID does not route resolution to the manager. Instead, the producing worker pulls the latest main, resolves the conflict locally inside its own worktree, and resubmits . Resolution responsibility stays with the session that introduced the change, because that session holds the context for why the edit was made. The manager stays a scheduler, not a merge referee — which keeps the coordinator's job bounded as the worker count grows.
What makes the design legible is that every coordination concept maps onto an existing git primitive rather than a bespoke protocol:
- Workspace isolation → git worktree. Each engineer agent gets its own checkout branched from main, so parallel writes never collide live (git-worktree docs).
- Structured handoff → commit / PR. A worker signals "done and self-verified" by submitting a commit; the artifact itself is the handoff message.
- Ordered integration → sequential merge. The manager merges one commit at a time, so each subsequent worker resolves against a main that already contains everything landed before it.
That mapping is why the pattern transfers cleanly to production tooling: anyone who already runs Claude Code worktrees or OpenAI Codex parallel tasks has the isolation half; CAID supplies the integration half as an ordering discipline rather than new infrastructure.
"Centralized task delegation, asynchronous execution, isolated workspaces, and structured integration" are the four properties CAID identifies as driving its accuracy gains over single-agent execution — the authors of "Effective Strategies for Asynchronous Software Engineering Agents," 2026 (source: arXiv:2603.21489).
The cost CAID accepts is the one named in the previous section: conflicts are discovered at merge time, after a worker has already finished and self-verified. If two workers edited the same region, one of them will pull main and redo work it thought was complete. CAID's measured gains say that for the PaperBench and Commit0 workloads, ordered sequential landing more than pays for that occasional rework — but the "resolve and resubmit" loop is precisely the friction that the next approach, STORM, tries to remove by catching collisions at write time instead.
STORM's early-conflict mediation: an alternative to deferred worktrees
STORM is a coordination layer that catches agent collisions at write time instead of at merge time. Submitted May 19, 2026, the paper argues that one-worktree-per-agent isolation defers conflict detection to an expensive post-hoc merge step, and it instead mediates shared-workspace interactions so a conflict surfaces the moment two sessions touch overlapping state . The wager is timing: surface the collision before a session has invested significant compute in a branch that a predecessor is about to invalidate.
The failure mode STORM targets is concrete. Under deferred worktrees, an agent can run a full task to completion — generate code, self-verify, open a PR — only to learn at the merge step that an earlier-landing branch already rewrote the same region. That session's work is now stale, and the "pull main, resolve, resubmit" loop discards minutes of agent time. STORM's claim is that late conflict discovery is the central cost of the worktree pattern, not an incidental edge case, and that a shared-state layer both sessions can read and write through removes most of it .
"One worktree per agent defers conflict detection to an expensive post-hoc merge step; mediating shared-workspace interactions lets conflicts be caught at write time," — STORM, "submitted May 19, 2026 (source: arXiv:2605.20563).
The reported numbers favor eager mediation on the harder integration workload. STORM measures +18.7 percentage points over a git-worktree multi-session baseline on Commit0-Lite and +1.4 percentage points on PaperBench, and a combined single-session-plus-STORM configuration reaches top scores of 87.6 and 78.2 on those two benchmarks . The large Commit0-Lite gain against the modest PaperBench gain is the tell: STORM helps most where independent edits frequently overlap, and helps little where tasks were already separable. That tracks with CAID's own finding that ordered sequential landing pays off on those same workloads — the two papers disagree on *when* to detect, not *whether* integration governance matters.
The tradeoff is structural, and it is the decision a builder actually has to make. Worktrees are cheap to set up — a directory and a branch, isolation in seconds — but they pay for that cheapness with wasted session work whenever a conflict lands late. Eager mediation inverts the cost: it catches issues before the investment is sunk, but it requires a shared-state layer that every session communicates through, which is more infrastructure to build, operate, and reason about than a plain `git worktree` plus a merge step. For low-overlap task sets, deferred worktrees stay competitive and simpler; for dense, contended codebases where agents repeatedly hit the same files, the write-time approach is where the measured gains concentrate.
How merge trains admit, validate, and sequence landing branches
A merge train is the admission-control layer that turns a pile of agent branches into an ordered landing sequence: each candidate is validated not against a stale snapshot of trunk but against the target branch plus every branch queued ahead of it, so the change that lands has already been tested against the exact state it will sit on top of. This is what makes serialized integration safe at the scale AI agents produce — a branch only merges after its pipeline passes and all earlier members have landed, which is why merge-time conflicts surface incrementally rather than in one tangled batch.
Quick Answer: A merge train validates each queued change against the target branch plus all changes ahead of it in line, merging only after that pipeline passes. GitLab defaults to 20 parallel pipelines per train (minimum 1 for fully serial processing) ; GitHub's merge queue makes build concurrency configurable from 1 to 100 .
GitLab merge trains (Premium and Ultimate tiers, available on GitLab.com, Self-Managed, and Dedicated) make the cumulative-validation model explicit. When merge requests queue, each is compared against earlier requests plus the target branch: the second train pipeline runs on MR-1 and MR-2 plus target, the third runs on MR-1, MR-2, and MR-3 plus target, and so on . Each MR merges only after its own pipeline succeeds and every earlier queued MR has merged. The default maximum of 20 parallel pipelines per train is the throughput knob; setting it to its minimum of 1 produces fully sequential processing . A serialized train is simply that minimum — trade parallel pipeline cost for strict, one-at-a-time admission.
GitHub's merge queue applies the same governance to pull requests. It enforces FIFO order, builds temporary merge_group branches, and validates each PR against the latest base branch plus the PRs ahead of it in the queue, with a build-concurrency and merge limit configurable from 1 to 100 . The open design question for agent fleets is failure behavior: when a queued member's pipeline fails, does the train block the whole line behind it, or eject the failing member and re-validate its successors against the new, shorter queue?
| Dimension | GitLab merge train | GitHub merge queue |
|---|---|---|
| Ordering model | Queued MRs validated against earlier MRs + target branch | FIFO; PRs validated against latest base + PRs ahead |
| Isolation unit | Train pipeline per MR position | Temporary merge_group branch |
| Max concurrency | 20 parallel pipelines (default); min 1 = fully serial | 1–100 build concurrency (configurable) |
| Failure behavior | Failing MR drops from train; later MRs re-validate | Failing PR removed; successors re-checked against new base |
| Tier requirement | Premium / Ultimate | Available on GitHub (repo branch-protection setting) |
For an orchestrator landing agent output, the practical mapping is direct: spawn agents in isolated worktrees, then route their branches through a queue set to the serialization level the codebase tolerates. Low-contention task sets can run several pipelines in parallel for throughput; dense, frequently-colliding repositories want the minimum-1 serial mode so each agent sees the prior merge before its own validation runs. The CI/CD primitive already exists — the orchestration work is admission policy, not new machinery.
How Batty, Augment Intent, and the Composio orchestrator serialize merges
That admission-policy work is exactly what the current crop of orchestrators encode, and they do it at very different levels of explicitness. Batty is the clearest standalone merge-train primitive among the surveyed tools: it runs persistent per-session worktrees, pulls its task list from a Markdown-kanban file, gates each branch behind pre-merge tests, and — the decisive detail — "serializes concurrent merges with a file lock" so two agents can never land into trunk at once. The lock is the train. Everything upstream is parallel; the integration point is forced single-file, which is the minimal mechanism the previous section described as minimum-1 serial mode.
Augment Code's Intent orchestration (published April 7, 2026; updated June 18, 2026) builds the same discipline into a three-tier structure . A Coordinator decomposes work with dependency ordering, specialist agents run in isolated worktrees, and a Verifier checks output against spec before any merge — so serialization happens at the verify gate rather than a raw file lock. The concrete numbers matter for capacity planning: it cites up to five simultaneous Claude sessions, worktree creation measured in seconds, deterministic port assignment in the 3100–9999 range, and repositories up to 400,000+ files . Dependency-ordered decomposition plus spec validation is admission ordering by another name — the train sequences on readiness, not arrival.
Composio's Agent Orchestrator sits at the productized end and is the most widely adopted: roughly 7.6k GitHub stars, latest release v0.9.2 dated May 23, 2026, and about 90% TypeScript . It spawns parallel sessions in their own worktrees, assigns each a branch and a pull request, and handles CI retries, merge-conflict resolution, and code reviews. The gap worth flagging: its README does not document the internal merge-train ordering. You get isolation and per-branch PRs out of the box, but the actual landing sequence — block-on-failure versus skip, parallel pipelines versus strict serial — is not specified, so teams with dense repositories must verify the admission behavior before trusting it under contention.
Superset (launched March 1, 2026, Apache-2.0) pushes the parallelism further, pitched at 10+ local concurrent sessions — past the 3–5 sweet spot where the codebase itself becomes the bottleneck. Its merge-serialization details are not publicly documented as of June 2026, which is the recurring pattern here: isolation is solved and advertised, while integration ordering is either a quiet file lock (Batty), a verify gate (Augment), or simply undocumented (Composio, Superset).
The takeaway for builders: when you evaluate one of these tools, the worktree story tells you almost nothing about safety. Ask where the lock is. A named serialization primitive — file lock, verify-before-merge, or an explicit queue — is the part that actually keeps trunk clean, and it is the part vendors are least consistent about disclosing.
Decomposing a codebase: the independence check for deciding what to split
Before you spawn a second worktree, run the independence test: two jobs are safe to parallelize only if neither reads a file the other writes. If agent A edits the auth handler while agent B refactors a util that auth imports, they are not independent — B's change can silently break A's branch, and you will only learn that at merge time. Apply the check at decomposition, not after the fact. Shared config files, lockfiles, and schema migrations almost always fail it: they are read or written by nearly every task, so two agents touching them are coupled no matter how unrelated their feature work looks.
Quick Answer: Split work only when two tasks share no write/read file dependency — the independence test. Keep concurrency to 3–5 worktrees; past five, shared files and cross-cutting concerns deepen the merge queue until wall-clock time stops improving. AgenticFlict measured a 27.67% merge-conflict rate across 142K+ AI-agent PRs, so admission ordering matters.
That coupling is why the practical ceiling sits low. Guidance across the surveyed tooling converges on a sweet spot of three to five concurrent worktrees; beyond five, shared files and cross-cutting concerns produce a merge queue deep enough that wall-clock time stops improving and the codebase itself becomes the bottleneck . The empirical floor backs the caution: AgenticFlict's analysis of 142K+ AI-agent PRs from 59K+ repositories found a 27.67% merge-conflict rate across 336K+ conflict regions . More agents do not dissolve that; they queue against it.
Containment helps where isolation alone does not. In his October 5, 2025 write-up, Simon Willison reported routinely running Claude Code, Codex CLI, Codex Cloud, Copilot, and Jules in parallel, and recommended a specific guardrail.
"I'll often run them in a Docker container — that way if they go rogue they can't do too much damage. It's about limiting the blast radius," — Simon Willison, on parallel coding agents (source: simonwillison.net, 2025-10).
One question stays unresolved, and it decides how your train behaves on a bad day: should a failing branch block the train or be skipped? Blocking prevents divergent integration — nothing lands until the broken member is fixed — but it stalls every successor behind it. Skipping maintains throughput but leaves successors validated against a base that excludes the dropped change, an ambiguous state that can resurface as a later conflict. Tooling is split on this, and no standard has emerged.
The concrete takeaway: decompose by the independence test, cap yourself at three to five agents, sandbox each session to limit blast radius, and decide your failing-member policy before you start the train rather than during a stall. Worktrees buy you isolation; that discipline is what buys you a clean trunk.
Last updated: 2026-06-23.
Frequently asked questions
What is a git worktree and why does each coding session get one?
A git worktree is an additional working directory linked to a single repository: it keeps its own HEAD and index while sharing the one object database . Each coding session gets its own worktree so it can check out a separate branch, edit files, and commit independently — without overwriting another session's tracked files or contending for a single index lock. Anthropic's Claude Code documentation recommends this directly, with `claude --worktree feature-auth` spinning up a separate checkout on its own branch .
What is a serialized merge train and how does it differ from a parallel merge queue?
A serialized merge train integrates branches strictly one at a time: branch N starts its validation pipeline only after branch N-1 has merged, so each branch sees its predecessor already in main. A parallel merge queue instead validates several branches concurrently — GitLab's default maximum is 20 parallel pipelines per train, with a minimum of 1 for fully sequential processing . GitHub's merge queue exposes the same governance for pull requests, with build-concurrency limits configurable from 1 to 100 . In short, "serialized" means setting that concurrency to 1.
How does STORM's write-time mediation differ from the standard worktree setup?
Worktrees defer conflict detection to merge time, so two agents only discover they touched the same code when their branches integrate. STORM (submitted May 19, 2026) instead mediates shared-workspace interactions and catches conflicts at write time, the moment a session makes a colliding change . STORM reported +18.7 percentage points on Commit0-Lite over a git-worktree multi-agent baseline and +1.4 on PaperBench . The trade-off: it requires a shared-state mediator both sessions can communicate through, rather than the loose coupling worktrees give for free.
How many parallel worktrees are worth running before diminishing returns hit?
Research and practitioners converge on three to five concurrent agents. Beyond five, shared config, schema migrations, and merge-queue depth become the bottleneck rather than the agents themselves. A practical approach is to start at two, measure how deep the merge queue gets, and add more sessions only while the queue stays shallow. Simon Willison's October 5, 2025 account of routinely running Claude Code, Codex CLI, Codex Cloud, Copilot, and Jules in parallel also stresses sandboxing — using Docker to "limit the blast radius" as concurrency rises .
What happens when a branch in the middle of the merge train fails?
There is no standard answer yet, and tooling is split. Blocking on the failing member keeps integration consistent but stalls throughput for every branch behind it. Skipping the failure maintains throughput but can leave successors in a state that conflicts with what eventually lands. Concretely, Batty serializes concurrent merges with a file lock and blocks on failure , while GitLab's merge train drops the failing merge request and re-queues its successors against the updated target . Decide your policy before starting the train, not during a stall.









