
2026년에 접하는 대부분의 JEPA 월드 모델은 백만 시간 분량의 영상으로 학습한 수십억 파라미터 시스템입니다. DVD-JEPA는 반대로 갑니다. 노트북 CPU에서 튀어 다니는 스크린세이버 로고의 물리를 학습하고, 그 모든 줄을 직접 읽어볼 수 있습니다.
DVD-JEPA란?
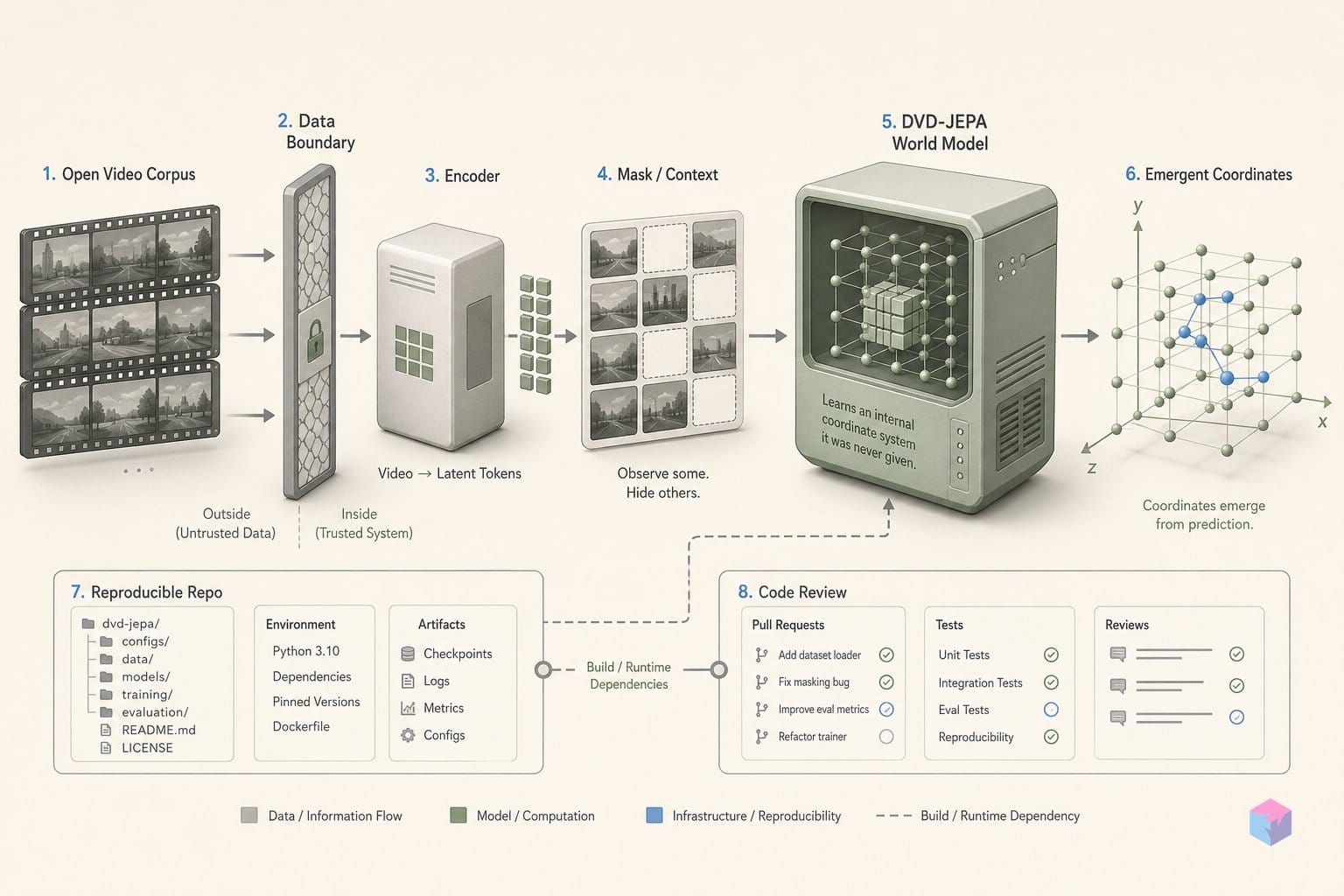
DVD-JEPA는 MIT 라이선스의 최소형 Joint-Embedding Predictive Architecture(JEPA) 월드 모델입니다. 고전적인 DVD 스크린세이버 로고의 움직임을 좌표 라벨 없이, 오직 픽셀만으로 학습합니다. 독립 개발자 Mandar Wagh(GitHub: mandarwagh9)가 2026년 6월 13일 공개했으며 PyTorch 기반으로 만들어졌습니다 . 저자는 이를 JEPA 원리를 보여주는 “가장 작은 정직한 데모”라고 설명하며, 학습된 모델은 서버도 GPU도 없이 브라우저에서 클라이언트 측으로 실행됩니다 .
핵심 전제는 Yann LeCun의 2022년 JEPA 입장 논문을 따릅니다. 다음 상태를 픽셀 재구성이 아니라 잠재 벡터로 예측한다는 것입니다. DVD-JEPA에서는 예측기 자체가 월드 모델입니다. 다음 임베딩을 상상하고, 선택 사항인 디코더는 그 “꿈”을 시각화할 때만 쓰입니다. 이미지를 다시 만드는 대신 표현 공간에서 예측하는 것이 이 모델의 핵심입니다.
학습은 python -m dvd_jepa.train 한 줄로 실행되며 CPU에서 약 10초 만에 끝납니다. 내보낸 모델은 약 40줄의 JavaScript로 브라우저에서 제공됩니다 . 공개 당시 저장소에는 커밋 6개와 약 30개의 스타가 있었고, 논문의 LaTeX 소스와 그림 생성 스크립트도 함께 제공되어 보고된 모든 수치를 다시 생성할 수 있습니다 . 유지보수되는 라이브러리라기보다 엄밀한 교육용 산출물로 보는 편이 맞습니다. 자체 보고 지표는 아직 제3자 벤치마킹을 거치지 않았습니다.
DVD-JEPA의 예측기, EMA 타깃, VICReg 정규화
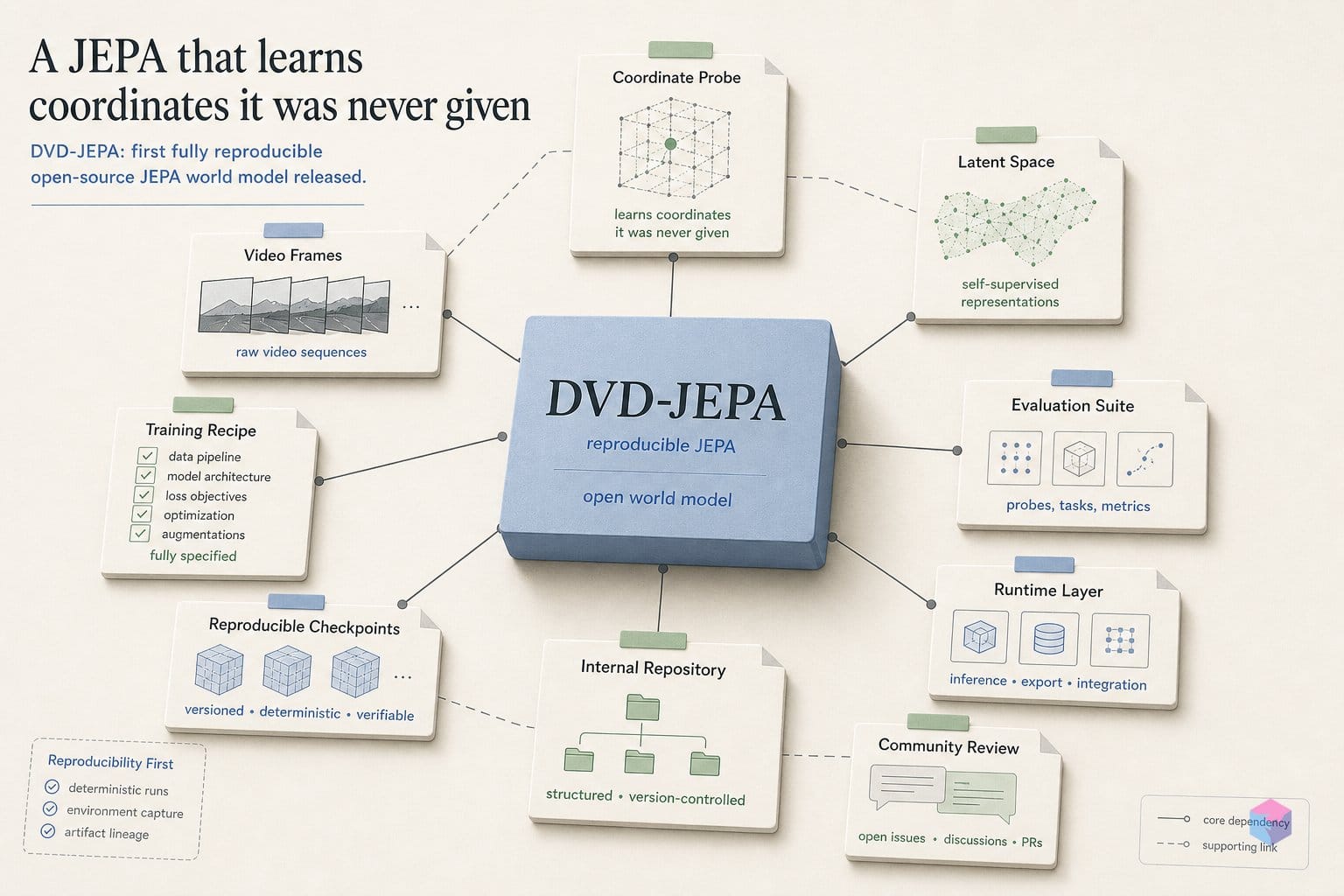
DVD-JEPA는 표준 JEPA 템플릿에 그대로 대응되는 네 개의 작은 모듈로 구성됩니다. 이 작은 크기 자체가 핵심입니다. 표현 경로의 모든 텐서를 손으로 확인할 수 있을 정도로 작기 때문입니다. 컨텍스트 인코더 E_θ는 2×16×16 픽셀 패치를 받아 256 → 128 → 32를 거쳐 32차원 잠재 표현으로 압축합니다 . 모든 예측은 픽셀 버퍼가 아니라 이 잠재 표현에서 일어납니다. 이것이 생성형 비디오 모델과 구조적으로 다른 지점입니다.
| 모듈 | 형태 | 역할 |
|---|---|---|
컨텍스트 인코더 E_θ | 2×16×16 → 256 → 128 → 32 | 현재 프레임을 32차원 잠재 표현으로 인코딩 |
타깃 인코더 E_ema | E_θ의 EMA 복사본 | 안정적인 예측 타깃을 만드는 stop-gradient 방식의 느리게 움직이는 복사본 |
예측기 P | 32 → 64 → 32 | 월드 모델: 현재 잠재 표현에서 다음 잠재 표현을 예측 |
디코더 D (선택) | 32 → 64 → 256 → 256 | 모델의 “꿈”을 시각화하며, 학습 신호에는 관여하지 않음 |
타깃 인코더 E_ema는 E_θ의 지수이동평균, stop-gradient 복사본입니다 . 이는 지름길 해법을 막기 위한 표준 JEPA 장치입니다. 타깃이 온라인 인코더를 천천히 따라가고 그래디언트를 받지 않기 때문에, 네트워크가 양쪽을 같은 상수로 쉽게 붕괴시켜 손실을 0으로 만드는 일이 어렵습니다. 이후 예측기 P(32 → 64 → 32)는 다음 임베딩을 직접 상상하도록 학습하며, 계획과 롤아웃은 전부 표현 공간 안에서 이뤄집니다.
학습 목표는 잠재 예측 오류와 VICReg 스타일의 분산 정규화 항을 함께 사용합니다. 이 정규화는 각 잠재 차원이 활성 상태를 유지하도록 하며 표현 붕괴를 막습니다 . 디코더 D(32 → 64 → 256 → 256)는 모델이 다음 프레임을 꿈꿀 때 무엇을 “보는지” 렌더링하기 위해서만 존재합니다. 손실에는 아무것도 기여하지 않으므로 제거해도 시각화만 달라질 뿐 학습된 동역학은 바뀌지 않습니다. 프로젝트가 강조하는 개념적 요지는 모델이 미래를 그림이 아니라 벡터로 예측한다는 점입니다 .
0.73px 프로브와 88배 서프라이즈 스파이크 읽기
DVD-JEPA가 제시하는 세 가지 핵심 수치는 각각 벡터 예측의 서로 다른 성질을 검증하므로 따로 읽어야 합니다. 고정된 32차원 잠재 표현 위에 학습한 선형 프로브는 로고의 위치를 약 0.73px 오차로 복원합니다 . 이것이 가장 중요한 결과입니다. 선형 맵은 좌표를 스스로 계산하기에는 너무 약하므로, 그 좌표를 깔끔하게 읽어낼 수 있다면 인코더가 이미 좌표 정보를 저장하고 있었다는 뜻입니다. 모델은 좌표를 한 번도 제공받지 않았지만, 비지도 표현은 좌표를 인코딩합니다. 이 저장소에서 JEPA 표현 품질 주장을 가장 직접적으로 뒷받침하는 증거입니다 .
예측기는 드리프트가 쌓이기 전까지 약 20스텝을 앞으로 굴릴 수 있습니다 . 이는 일반적인 비디오 예측 수치가 아니라 튀는 로고 도메인에서의 유효 계획 지평으로 읽어야 합니다. 상상한 임베딩이 다시 자기 자신에게 입력될 때마다 오류가 누적되며, 20스텝이라는 값은 실제 영상이 아니라 결정적이고 엔트로피가 낮은 장면을 반영합니다.
로고를 순간이동시키면 예측 오류 “서프라이즈” 미터가 약 88배 치솟습니다 . 예측기는 부드러운 튕김을 기대하므로, 모델링한 적 없는 불연속은 큰 잠재 잔차로 기록됩니다. 덕분에 이 도메인 안에서는 예측 오류 자체를 이상 신호로 쓸 수 있습니다. 라이브 데모에서는 순간이동을 직접 실행하고 미터가 반응하는 모습을 볼 수 있습니다 .
세 수치 모두에 적용되는 단서가 하나 있습니다. 저자가 이 프로젝트를 JEPA 원리의 “가장 작은 정직한 데모”라고 설명하듯이 , 정직함은 양방향으로 작동합니다. 여기의 모든 수치는 저장소와 데모 사이트가 자체 보고한 것이며, 공개 시점에는 독립 벤치마킹이나 동료 평가가 없었습니다. 0.73px, 20스텝, 88배라는 숫자는 JEPA가 어떻게 작동하는지 이해하기 위한 교육적 지표로 보아야 하며, 다른 월드 모델과 비교하는 증거로 삼기에는 부족합니다.
EB-JEPA는 2월에 공개됐습니다 — DVD-JEPA의 자리는 더 좁습니다
DVD-JEPA는 최초의 오픈소스 JEPA 월드 모델이 아니며, 그런 설명은 2026년 공개 이력을 보면 유지되기 어렵습니다. Meta/FAIR의 EB-JEPA — Energy-Based JEPA를 위한 공식 Apache-2.0 라이브러리 — 는 DVD-JEPA가 2026년 6월 13일 공개되기 몇 달 전인 2026년 2월 3일 날짜의 arXiv 논문에서 소개됐습니다. 따라서 DVD-JEPA에 대해 방어 가능한 최상급 표현은 "최초"보다 훨씬 좁습니다. 브라우저 추론을 갖춘, 완전히 재현 가능한 가장 작은 장난감 JEPA 월드 모델이라는 정도입니다. "최초의 오픈소스 JEPA"라는 주장은 성립하지 않습니다.
EB-JEPA는 난도가 점진적으로 높아지는 세 가지 예제 — 이미지 표현 학습, 비디오 예측, 행동 조건부 계획 — 를 제공하며, 각각 몇 시간 안에 단일 GPU로 학습할 수 있게 구성돼 있습니다. 이 프로젝트는 최대 91.02% CIFAR-10 linear-probe 정확도(SIGReg), 다단계 Moving MNIST 예측, Two Rooms 환경에서 97% 계획 성공률을 보고합니다. 크롤링 시점의 저장소에는 715개 스타와 85개 포크가 표시됐습니다. DVD-JEPA의 약 30개 스타와는 독자층과 규모가 다릅니다.
그뿐만이 아닙니다. JEPA-WMs(facebookresearch, 2025년 12월 30일)는 다섯 가지 로봇 환경에 걸쳐 사전학습 체크포인트가 포함된 행동 조건부 월드 모델을 공개했으며, 내비게이션과 조작 작업에서 DINO-WM 및 V-JEPA-2-AC를 능가한다고 보고됐습니다. 다만 CC-BY-NC 4.0 라이선스 때문에 상업적 사용은 불가능합니다. LeWorldModel(약 1,500만 개 파라미터, arXiv 2603.19312)도 픽셀 입력부터 끝까지 구성된 JEPA로, 단일 GPU에서 몇 시간 안에 학습할 수 있습니다.
| 공개 모델 | 날짜 | 라이선스 | 대표 결과 |
|---|---|---|---|
| EB-JEPA | 2026-02-03 | Apache-2.0 | 91% CIFAR-10 probe; 97% Two Rooms planning |
| JEPA-WMs | 2025-12-30 | CC-BY-NC 4.0 | 로봇 작업에서 DINO-WM, V-JEPA-2-AC를 능가 |
| DVD-JEPA | 2026-06-13 | MIT | 브라우저 추론을 갖춘 가장 작은 장난감 JEPA |
LeCun의 공동 연구자들이 에너지 기반 계열을 설명하는 방식에 따르면, EB-JEPA는 Energy-Based JEPA를 위한 "가벼운 라이브러리이자 튜토리얼"입니다 (source: Terver et al., FAIR, 2026-02). 이 관점에서 보면 DVD-JEPA의 가치는 우선권이 아니라 교육적 접근성에 있습니다.
DVD-JEPA와 2026년 JEPA 지형
DVD-JEPA의 위치를 제대로 보려면, 이 프로젝트가 의도적으로 피한 계산량 중심의 끝단과 비교해야 합니다. 2025년 6월 11일 발표된 Meta의 V-JEPA 2는 12억 개 파라미터 규모의 월드 모델로, 100만 시간 이상의 비디오와 100만 장의 이미지로 사전학습한 뒤 62시간 분량의 DROID 로봇 데이터로 행동 조건부 학습을 거쳤습니다 . 이 모델은 Something-Something v2에서 top-1 77.3을, 새로운 물체와 환경의 pick-and-place 작업에서 65~80% 성공률을 보고합니다 . 이는 완전히 다른 종류의 산출물입니다. 강력하지만, 단일 개발자가 CPU에서 끝까지 들여다볼 수 있는 물건은 아닙니다.
두 번째 기준점은 2024년 11월의 DINO-WM입니다. 이 모델은 고정된 DINOv2 패치 특징 위에 잠재 시각 동역학 모델을 만들고, 여섯 가지 환경에서 제로샷 행동 시퀀스 최적화를 수행합니다 . 재현성 측면의 타협점도 DVD-JEPA와 다릅니다. 파인튜닝은 필요 없지만, 모든 모듈을 처음부터 학습하는 대신 DINOv2 사전학습 가중치에 의존하게 됩니다.
이 공개 사례들을 함께 보면, 2026년의 흐름은 재현성 스펙트럼이 건강하게 다양해지는 방향입니다. 크지만 부분적으로만 재현 가능한 모델에서 더 작고 완결성 높은 패키지로 이동하고 있습니다. EB-JEPA는 허용적 라이선스의 교육용 라이브러리 역할을 하고, JEPA-WMs는 계획을 위한 체크포인트와 데이터셋을 제공하며, DVD-JEPA는 브라우저 추론을 갖춘 최소 장난감 모델의 자리를 차지합니다. 저자는 자신의 모델을 미래를 "그림이 아니라 벡터로" 예측하는 방식이라고 설명합니다 — Mandar Wagh, DVD-JEPA author (source: GitHub, 2026-06). 이는 더 큰 시스템들이 사용하는 동일한 붕괴 회피 장치를 읽기 쉽게 만든 형태입니다.
이 분야에 본격적으로 뛰어들기 전에 구현들을 훑어보려는 개발자에게는, 커뮤니티가 관리하는 awesome-jepa 트래커가 각 구현의 라이선스 조건, 계산 요구사항, 재현성 수준을 확인하는 실용적인 색인입니다.
DVD-JEPA를 클론할 때와 EB-JEPA를 선택할 때
목표가 이해라면 DVD-JEPA를, 실제 배포라면 EB-JEPA를 고르세요. DVD-JEPA의 가치는 붕괴를 피하는 전체 구조, 즉 EMA 타깃 인코더와 VICReg 스타일 분산 항이 200줄 미만의 Python 안에 들어가고 CPU에서도 대략 10초 안에 학습된다는 데 있습니다 . 반면 EB-JEPA는 Meta/FAIR가 관리하는 Apache-2.0 라이브러리로, 단일 GPU 예제와 실제 벤치마크를 갖추고 있습니다 . 빠르게 판단하려면 이렇게 보면 됩니다.
- DVD-JEPA를 클론할 만한 경우: EMA 타깃과 VICReg 메커니즘을 처음부터 끝까지 읽고 싶거나, 내보낸 모델로 브라우저 호환 추론이 필요하거나(데모는 클라이언트 측 JavaScript 약 40줄로 실행됩니다), JEPA 기초를 가르치면서 완전히 들여다볼 수 있는 참고 구현이 필요할 때입니다 .
- EB-JEPA를 선택할 만한 경우: CIFAR-10(선형 프로브 약 91%), Moving MNIST 예측, Two Rooms 계획(성공률 97%)처럼 GPU 규모 예제가 필요하거나, 확장 가능한 유지보수 코드베이스가 필요하거나, 상업적 활용 가능성을 염두에 두고 있다면 EB-JEPA가 맞습니다. 라이선스가 이를 허용합니다 .
- JEPA-WMs 체크포인트를 쓸 만한 경우: 로봇 조작이나 내비게이션을 목표로 하고 jepa_wm_droid, jepa_wm_metaworld 같은 사전학습 가중치가 필요할 때입니다. 다만 제품 작업에 쓰기 전에는 CC-BY-NC 4.0(비상업) 라이선스를 반드시 확인하세요 .
운영 관점의 주의점도 하나 있습니다. 캡처 시점의 DVD-JEPA는 커밋 6개, 단일 작성자, 별 약 30개 규모의 프로젝트였고 독립 벤치마크는 없었습니다 . 자유롭게 포크해도 좋지만, 프로덕션 의존성 트리에 바로 연결하지는 마세요. 함께 제공된 LaTeX 논문과 그림 생성 스크립트를 핵심 산출물로 보아야 합니다. 재현성 주장이 실제로 담긴 곳은 그쪽입니다.
토이 도메인의 한계: 위치만 보는 지표가 일반화되지 않는 이유
튀는 로고 도메인은 결정적이고, 엔트로피가 낮고, 엄격한 2D 환경입니다. 바로 그래서 JEPA 학습 루프를 보여주기에 이상적이지만, 바로 그래서 그 지표는 다른 곳으로 옮겨갈 수 없습니다. 일정한 속도와 반사 벽을 가진 로고는 상태 공간이 매우 작기 때문에 위치를 약 0.73px까지 복원하는 일은 그 세계 안에서는 의미가 있지만, 바깥 세계에 대해서는 아무 말도 해주지 않습니다. 이를 실제 비디오, 로보틱스, 제어 결과로 읽는 것은 범주를 잘못 잡은 것입니다.
이 주의점은 DVD-JEPA를 더 큰 친척 모델들과 나란히 놓을 때 특히 중요합니다. 이 프로브 수치를 I-JEPA나 V-JEPA의 ImageNet 또는 Kinetics 정확도와 비교하는 일, 예를 들어 V-JEPA 2가 12억 파라미터에서 Something-Something v2 top-1 77.3을 보고했다는 사실과 비교하는 일은 서로 다른 정보 밀도의 서로 다른 도메인을 재는 것입니다. 순간이동 시 약 88배로 튀는 surprise 값도 마찬가지로 범위가 제한됩니다. 그 크기는 해당 교란이 이 도메인의 거의 0에 가까운 자연 분산에 비해 얼마나 큰지에 부분적으로 좌우되므로, 더 풍부하고 확률적인 환경에서의 이상 탐지에 대해서는 거의 말해주지 않습니다.
정직한 가치는 다른 곳에 있습니다. DVD-JEPA는 경험적 경쟁력을 내려놓는 대신 개념적 명확성을 얻습니다. EMA 타깃 인코더와 VICReg 정규화로 구성된 붕괴 방지 메커니즘, 잠재 공간 예측, 선형 프로브 평가, surprise 기반 이상 신호를 12억 파라미터 코드베이스에서는 보기 어려운 방식으로 처음부터 끝까지 읽을 수 있게 해줍니다. 결론은 이렇습니다. JEPA가 표현 붕괴를 피하는 방식을 이해하려고 클론하세요. 벤치마크하려고 클론할 것은 아닙니다.
자주 묻는 질문
DVD-JEPA는 무엇이며 Meta의 V-JEPA 2와 어떻게 다른가요?
DVD-JEPA는 튀어 다니는 DVD 화면 보호기 로고의 물리를 픽셀만으로 학습하는 최소형 장난감 Joint-Embedding Predictive Architecture입니다. 32차원 잠재 공간을 사용하며 CPU에서 약 10초 만에 학습됩니다 . 2025년 6월 11일 발표된 Meta의 V-JEPA 2는 스펙트럼의 정반대 끝에 있습니다. 12억 개 매개변수를 100만 시간 이상의 비디오와 100만 장의 이미지로 사전 학습한 뒤, 62시간 분량의 DROID 로봇 데이터로 행동 조건 학습을 거쳤습니다 . 둘 다 JEPA의 핵심 방식, 즉 잠재 공간에서 예측하고 EMA 타깃 인코더로 붕괴를 막는다는 점은 같지만, 규모와 연산량은 대략 7자릿수 차이가 납니다. 하나는 처음부터 끝까지 읽어볼 수 있는 학습용 산출물이고, 다른 하나는 실제 영상과 제어를 위한 연구급 월드 모델입니다.
DVD-JEPA가 정말 최초의 오픈소스 JEPA 월드 모델인가요?
아닙니다. "최초의 완전 재현 가능한 오픈소스 JEPA 월드 모델"이라는 표현은 이 프로젝트 포지셔닝에서 가장 취약한 부분입니다. Meta/FAIR의 EB-JEPA는 2026년 2월 3일 Apache-2.0 라이선스로 공개되었고, 이미지, 비디오, 계획 예제를 함께 제공했습니다 . facebookresearch/jepa-wms 릴리스도 PyTorch 코드, 사전 학습 체크포인트, 11.1GB 데이터셋을 포함해 2025년 12월에 나왔습니다 . DVD-JEPA가 방어할 수 있는 더 좁은 위치는 클라이언트 측 브라우저 추론을 갖춘 가장 작은 완전 재현 가능 장난감 JEPA 월드 모델이라는 점입니다 .
DVD-JEPA에서 VICReg는 어떤 역할을 하며 왜 필요한가요?
VICReg는 표현 붕괴를 막습니다. 표현 붕괴란 인코더가 모든 입력을 같은 벡터로 매핑해 예측 오차는 쉽게 줄이지만 실제로는 유용한 것을 전혀 배우지 못하는 실패 모드입니다. VICReg는 분산이 낮은 잠재 차원에 벌점을 주는 분산 항과 차원 간 상관을 줄이는 공분산 항을 더해, 32차원 임베딩이 계속 정보를 담도록 강제합니다 . DVD-JEPA는 여기에 보완적인 붕괴 방지 신호를 함께 씁니다. EMA 타깃 인코더는 컨텍스트 인코더의 stop-gradient 지수이동평균 복사본이어서, 예측 타깃을 최적화 중인 매개변수와 분리합니다. 따라서 모델이 양쪽을 함께 상수로 줄이는 방식으로 속일 수 없습니다 . 이 둘이 함께 작동하기 때문에 비지도 잠재 표현만으로도 로고 위치를 약 0.73px 수준까지 복원할 수 있습니다.
DVD-JEPA를 상업 프로젝트에 사용할 수 있나요?
MIT 라이선스는 상업적 사용을 허용하지만, 현실적으로는 권장하지 않습니다. DVD-JEPA는 공개 릴리스가 없는 6커밋짜리 교육용 산출물입니다. 학습용으로는 괜찮지만 프로덕션 의존성으로는 적합하지 않습니다 . 상업용 JEPA 작업에는 유지 관리되는 라이브러리와 단일 GPU 예제를 갖춘 EB-JEPA(Apache-2.0)가 적절한 출발점입니다 . JEPA-WMs는 CC-BY-NC 4.0 라이선스이며, 데이터셋 접근도 연락처 제출 뒤에 열리므로 상업적으로 사용해서는 안 됩니다 .
0.73px 선형 프로브 결과를 처음부터 재현하려면 어떻게 하나요?
단일 학습 명령인 python -m dvd_jepa.train을 실행하면 됩니다. PyTorch를 사용해 CPU에서 약 10초 만에 끝납니다. 그런 다음 포함된 선형 프로브 평가 스크립트를 고정된 32차원 잠재 표현에 대해 실행하면 로고 위치를 약 0.73px까지 복원할 수 있습니다 . 이 저장소에는 논문의 LaTeX 소스와 그림 생성 스크립트도 포함되어 있어, 보고된 모든 수치, 즉 프로브 정확도, 약 20스텝 롤아웃 지평, 약 88배의 surprise spike를 처음부터 끝까지 다시 생성할 수 있습니다. 이것이 "완전 재현 가능"이라는 표현의 근거입니다 .









