
. 600점대 중반이라는 수치가 유용한 기준점입니다. 실제 공개 활동 이력이 있는 현직 기자도 아이콘급 인물보다는 훨씬 낮은 곳에 자리하며, 그들과 가까운 수준은 아닙니다.
996과 988이라는 수치 사이의 작은 차이는 두 기사 사이에 리더보드 순위가 움직였거나 기준점이 달랐기 때문일 가능성이 큽니다. 현재 점수에 대한 유일한 권위 있는 출처는 라이브 사이트입니다 .
이 점수는 한 모델의 의견이 아닙니다. In the Weights는 10개가 넘는 시스템에 동시에 질의한 뒤 그 분포를 최종 숫자로 압축하며, 프런티어 모델과 소형 오픈웨이트 모델을 나란히 놓습니다.
- 프런티어 독점 모델: Grok, Gemini, GPT-5.5, Claude Opus 4.8
- 소형 독점 모델: GPT-5.4 Mini 변형
- 오픈웨이트: Meta의 Llama 시리즈, GLM, Qwen3 8B
이들을 함께 돌리는 것이 핵심입니다. 같은 이름도 대형 모델에서는 높은 점수를 받고 소형 모델에서는 사라질 수 있으며, 다음 섹션은 바로 그 대비를 풀어봅니다 .
| 기준점 | 대략적인 강도 점수 | 의미 |
|---|---|---|
| 리더보드 상한선(Mozart, Shakespeare, Taylor Swift) | 996 | 질의된 모든 모델에 전 세계적으로 기억된 상태 |
| Macaulay Culkin(출시 주간 최상위 항목) | 988 | A급 인지도이지만 상한선에는 약간 못 미침 |
| Anthony Ha(TechCrunch 필자) | 641 | 중간급 공인, 대략 상위 6% |
| 흔하거나 철자가 틀린 이름 | 낮음 / 모호함 | 모델이 구분하지 못해 결과가 무너짐 |
| 사적 개인 | ~0 | 가중치 안에 전혀 존재하지 않음 |
이 숫자는 평판 점수가 아니라 신뢰도에 가까운 지표로 읽어야 합니다. 641은 네 개 이상의 프런티어 및 오픈 모델이 브라우징 없이 그 이름을 떠올린다는 뜻이고, 0에 가까운 값은 가중치 안에 떠올릴 정보가 없다는 뜻입니다.
소형 7B 모델이 당신을 안다는 것이 더 강한 신호인 이유
소형 모델이 당신의 이름을 떠올린다면, 프런티어 모델이 같은 일을 하는 것보다 더 큰 의미가 있습니다. 작은 모델은 기억할 공간 자체가 훨씬 적기 때문입니다. Qwen3 8B 같은 80억 파라미터 오픈 모델은 프런티어 시스템이 담고 있는 사실의 극히 일부만 보유하므로, 그 안에 남는 사람들은 전 세계적으로 가장 두드러진 일부에 치우칩니다 .
In the Weights는 이 비대칭성을 중심에 두고 만들어졌습니다. Qwen3 8B나 GLM 같은 소형 오픈 모델에 등장한다는 것은 문화권을 넘어 대량으로 기억되었다는 뜻입니다. 강한 압축을 견디고 이름이 살아남은 것입니다. 반대로 GPT-5.5나 Claude Opus 4.8 같은 대형 모델에만 등장한다면, 모델에 여유 용량이 있어 주변부 엔티티까지 보존한 긴 꼬리 범위의 결과일 수 있습니다 .
이 사이트의 종합 점수는 그 논리를 직접 반영합니다. 더 작은 모델에서 기억될수록 전체 강도 수치가 불균형하게 크게 올라갑니다. 제작자들이 소형 모델에 존재한다는 사실을 관련성에 대한 더 강한 증거로 보기 때문입니다 . 웹상 흔적이 동일한 두 사람도 한 명은 오픈웨이트 층까지 살아남고 다른 한 명은 그렇지 않다면 점수가 크게 벌어질 수 있습니다.
모델 계층별로 보면 기억 신호는 대략 이렇게 쌓입니다.
| 모델 계층 | 예시 모델 | 주로 살아남는 대상 | 기억될 때의 신호 |
|---|---|---|---|
| 소형(약 7B-8B, 오픈웨이트) | Qwen3 8B, GLM | 전 세계적으로 유명한 인물: 작곡가, 역사적 인물, 최상위 유명인 | 가장 강함: 희소한 용량, 높은 기준 |
| 중간급 | GPT-5.4 Mini, Llama 시리즈 | 문서화가 잘 된 공인, 주목받는 창업자, 기자 | 중간 수준, 의미는 있지만 더 넓음 |
| 프런티어(대형) | GPT-5.5, Claude Opus 4.8, Gemini, Grok | 긴 꼬리 엔티티: 틈새 전문가, 지역 인물 | 가장 약함: 넓은 포괄 범위가 신호를 희석함 |
이것이 왜 상한선에 가까운 점수를 꾸며내기 어려운지 설명합니다. 리더보드 최상단의 이름들(Mozart, Shakespeare, Taylor Swift, 모두 최대치 996에 가까움)은 기억을 가장 엄격하게 배분하는 소형 모델까지 포함해 어디서나 떠올려집니다 . 대부분의 빌더와 크리에이터에게 실용적인 핵심은 소형 계층을 지켜보는 것입니다. 그것이 진짜 교차 모델 기억과 우연한 긴 꼬리 포괄을 가르는 문턱입니다.
GEO와 SEO: AI 발자국은 크롤링되는 것이 아니라 고정됩니다
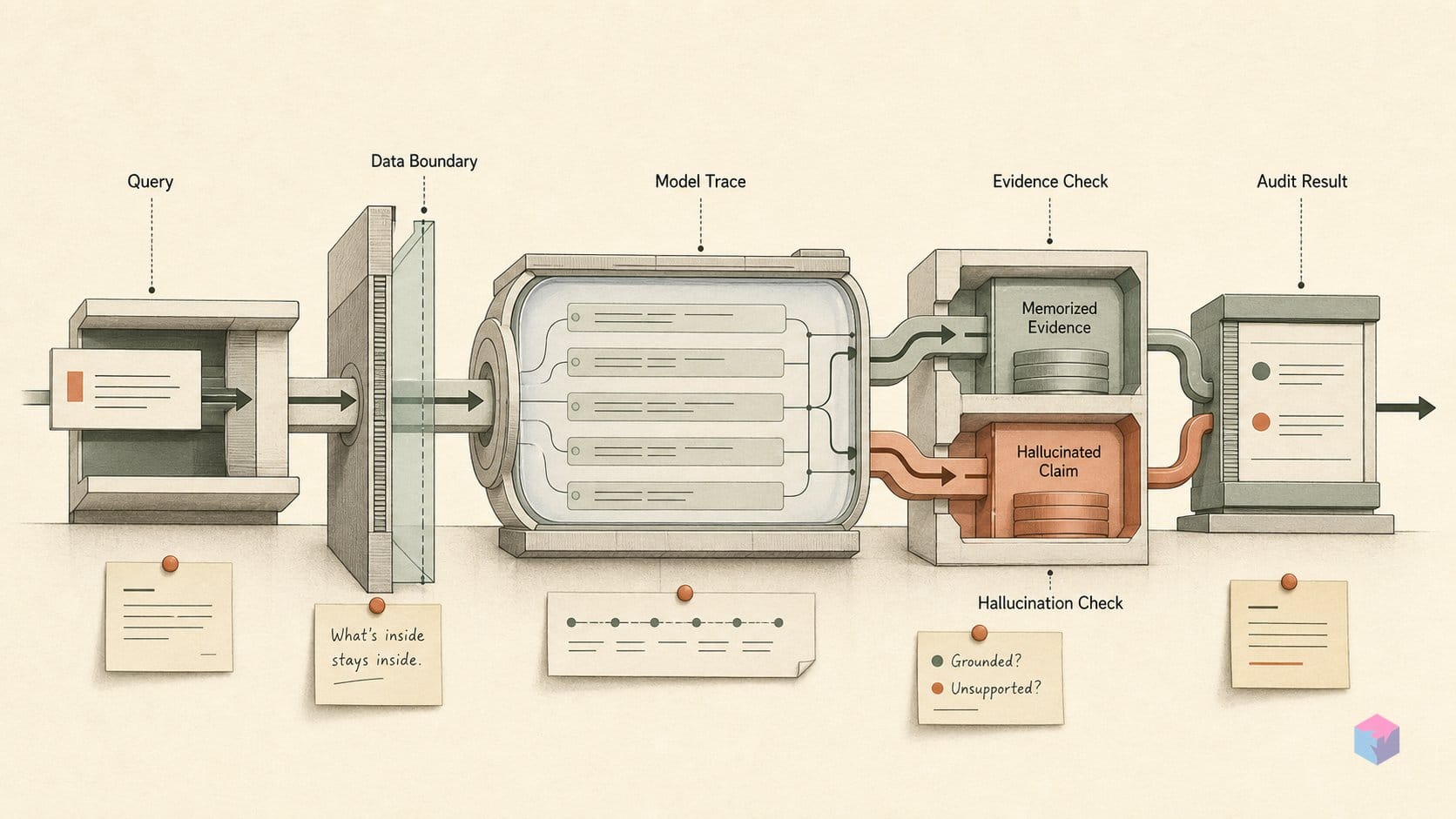
컴팩트 티어 기준이 중요한 이유는 구조적입니다. AI 발자국은 검색 발자국과 전혀 다르게 작동합니다. SEO는 살아 있는 인덱스를 기반으로 움직입니다. 글을 발행하고, 링크를 얻고, 다시 크롤링되기를 기다리면 며칠에서 몇 주 안에 루프가 닫힙니다. 반면 모델의 기억은 학습 컷오프 시점에 고정됩니다. 공개된 가중치에 새겨진 지식은 당신이 아무리 많이 발행해도 움직이지 않습니다 .
이 차이가 바로 웹이 아니라 가중치를 측정해야 하는 이유입니다. 구글에서 자기 이름을 검색하면 계속 업데이트되는 인덱스를 읽는 것이지만, In the Weights는 사전 학습 때 잠기고 다음 모델이 나올 때까지 그대로 남아 있는 파라미터를 찌릅니다 . 웹은 필요할 때 다시 크롤링할 수 있습니다. 가중치는 그럴 수 없습니다.
그래서 갱신 주기는 크게 갈라집니다:
- 웹/SEO: 새 페이지나 백링크는 며칠에서 몇 주 안에 인덱스에 반영됩니다. 피드백 루프가 짧고, 필요할 때 작동합니다.
- 가중치/GEO: 오늘 무엇을 발행해도 이미 배포된 모델은 바뀌지 않습니다. 당신에 대한 모델의 그림은 향후 사전 학습이나 파인튜닝에서만 수정될 수 있고, 그 주기는 버튼 하나로 당길 수 있는 것이 아니라 몇 달에서 몇 년 단위입니다 .
- 지연: 모델 컷오프 이후 유명해진 사람은 실시간 웹 존재감이 아무리 강해도 다음 학습 주기가 따라잡기 전까지 그 모델 안에서는 사실상 보이지 않습니다.
제작자들은 검색엔진에서 LLM으로 관심이 이동하는 이 변화를 중심에 두고 도구 전체를 설명하며, The Decoder의 출시 기사에서 언급하듯 가중치 안의 존재감은 웹상의 존재감과 별개의 자산이라고 분명히 말합니다 . TechCrunch는 직접 써본 리뷰에서 이 실험이 예전의 '내 이름 구글링하기' 습관을 새로운 질문으로 바꾼다고 말합니다. 웹이 당신에 대해 무엇을 말하는지가 아니라, 모델이 무엇을 기억하고 있는지를 묻는 질문입니다.
공적 존재감을 쌓는 사람들, 예를 들어 창업자, 기자, 연구자에게 결론은 실무적입니다. 온라인 발자국과 AI 발자국은 시간이 갈수록 서로 벌어지는 두 개의 별도 자산이며, 각각 다른 전략이 필요합니다. 하나를 최적화한다고 해서 다른 하나가 같은 시계로 따라오지는 않습니다. 이번 분기에 실시간 인덱스를 장악하더라도, 프런티어 모델의 다음 학습이 도착하기 전까지는 그 모델 안에 계속 없을 수 있습니다.
확신은 진실이 아닙니다: 환각은 어디서 들어오는가
강도 점수가 높다는 것은 모델이 확신한다는 뜻이지, 그 내용이 맞다는 뜻은 아닙니다. In the Weights가 측정하는 것은 확신이며, 확신과 정확도는 서로 다른 변수입니다. 제작자들도 이 점을 분명히 말합니다. 이 수치는 모델이 어떤 이름을 얼마나 강하게 떠올리는지에 대한 대리 지표일 뿐, 그 사람이 누구인지 검증한 설명이 아닙니다 . 출처가 아니라 신호로 봐야 합니다.
실패 양상은 구체적입니다. TechCrunch가 이 도구를 실행했을 때 GPT-5.4 Mini는 실제로 활동 중인 기자인 'Anthony Ha'를 'A.H.A.라는 이니셜을 가진 여러 사람을 가리킬 수 있는 모호한 이름 형태'라고 설명했습니다 . 이는 확신에 찬 식별 실패입니다. 데이터가 부족했다기보다, 그 이름이 어떤 사람을 가리키는지 풀어내지 못한 것입니다.
흔한 이름일수록 이런 문제가 커집니다. 모델은 자신에게 없는 맥락 없이는 올바른 개인을 고를 수 없기 때문에, 여러 사람을 하나의 흐릿한 설명으로 합치거나 애매하게 물러섭니다 . 여기서 두 가지 실패 경로가 나옵니다:
- 병합: 서로 다른 실제 인물들이 하나의 확신에 찬 프로필로 뭉개지며, 각기 다른 사람에게 속한 이력이 뒤섞입니다.
- 유보: 모델이 단정하지 않고 물러서면서, 실제로 가중치 안에 존재하는 사람에게도 낮거나 거의 0에 가까운 수치를 반환합니다.
입력의 취약성도 또 다른 함정입니다. 오타 하나만 있어도 수치가 급격히 내려갑니다. 전 세계적으로 유명한 이름도 철자 하나가 틀리면 거의 0에 가까운 결과가 나올 수 있는데, 모델이 근본적인 정체성이 아니라 표면 토큰을 맞추고 있기 때문입니다 . 같은 사람도 철자에 따라 높은 점수를 받거나 보이지 않는 존재가 됩니다.
또한 이 도구는 어떤 사실이 어떻게 가중치에 들어갔는지도 보여주지 못합니다. The Decoder가 출시 기사에서 지적했듯, 이 시스템은 '기억된 사실과 환각된 사실을 구분하지 않고, 모델이 얼마나 확신하는지만 본다'는 한계가 있습니다 . 자신의 발자국을 점검하는 빌더에게 실무 원칙은 간단합니다. 점수는 확신도로 읽고, 모델이 실제로 주장하는 내용은 직접 검증해야 합니다.
온라인 존재감과 AI 풋프린트의 격차가 의미하는 것

온라인 존재감과 AI 풋프린트 사이의 격차는 결국 타이밍의 문제다. 웹은 계속 업데이트되지만, 모델 가중치는 학습 컷오프 시점에 멈추고 새 모델이 학습될 때에만 갱신된다. 그래서 AI 풋프린트는 온라인 풋프린트보다 대략 한 번의 전체 학습 주기만큼 뒤처지며, 지금의 당신과 모델이 '알고 있는' 당신 사이에는 흔히 몇 달의 어긋남이 생긴다. 전 OpenAI 빌더 Thomas Dimson과 Joey Flynn이 2026년 6월 19-20일 공개한 In the Weights 는 최신성이 아니라 확신도를 점수화해 이 지연을 눈에 보이게 만든다.
이 차이를 이해하면, 당신이 어떤 사람인지에 따라 대응 방식도 달라진다.
- 꾸준히 발행하는 기자와 창업자: 모델은 실제 성과를 뒤늦게 따라온다고 봐야 한다. 최근 작업이나 직책 변화는 다음 사전학습 실행에 포함되기 전까지 거의 반영되지 않는다.
- SEO가 강한 신흥 필자: 검색 순위가 높다고 해서 모델이 기억한다는 뜻은 아니다. 검색 결과 페이지를 장악해도 점수는 거의 0에 가까울 수 있고, 모델은 재학습되기 전까지 당신이 누구인지 전혀 모를 수 있다.
- 흔한 이름을 가진 사람: 동명이인 구분은 구조적으로 어려운 문제다. 사이트가 여러 사람을 하나의 혼란스러운 묶음으로 섞을 수 있고, GPT-5.4 Mini 같은 프런티어 모델도 유보적으로 답할 수 있다. 보도에 따르면 이 모델은 "Anthony Ha"를 "A.H.A. 이니셜을 가진 여러 사람을 가리킬 수 있는 모호한 이름 형태"로 태그했다
실제로 중요한 지점은 GEO 타이밍이다. 가중치는 고정되어 있으므로, 미래 모델이 기억하길 원하는 정보는 다음 학습 컷오프 전에 널리 스크랩되는 권위 높은 출처에 들어가야 한다. 동료심사 논문, 도메인 권위가 높은 매체, Wikipedia가 가장 큰 비중을 갖고, 컷오프 이후에 추가한 블로그 글은 그 세대 모델에는 아무런 영향을 주지 않는다 .
핵심은 이렇다. In the Weights 점수는 판정이 아니라 후행 지표로 봐야 한다. 모델이 실제로 수집하는 출처에 오래 남는 인용을 만들고, 모델이 당신에 대해 내놓는 주장을 검증해야 한다. 그리고 그 격차를 줄이는 시간 단위는 다음 배포가 아니라 학습 주기라는 점을 받아들여야 한다.
자주 묻는 질문
'In the Weights'는 실제로 무엇을 측정하나요?
대형 언어 모델이 특정 인물을 사전학습만으로 얼마나 강하게 기억하는지를 측정한다. 웹 크롤링도, 브라우징도, 외부 도구도 없이 모델 파라미터 안에 새겨진 지식만 본다 . 결과는 0부터 거의 1000에 가까운 상한까지 이어지는 단일 확신도 수치로 나오며, 전 세계적으로 유명한 최상위 이름들(Mozart, Shakespeare, Taylor Swift)은 996으로 보고됐다 . 확신도 있게 등장한다는 것은 모델이 학습 중 당신을 도구 없이 떠올릴 만큼 관련성 있는 존재로 봤다는 뜻이다.
확신도 수치는 어떻게 계산되나요?
각 모델은 구조화된 프롬프트를 받는다. 대략 'Who is <name>? Give up to 10 results, each with a short description and confidence' 같은 형태이며, 사이트는 비슷한 설명을 묶은 뒤 모델별 강도 점수로 압축한다 . 프런티어 시스템부터 더 작은 오픈 가중치 모델까지 여러 모델을 병렬로 질의하고, 그 결과를 합쳐 사이트 차원의 하나의 수치로 만든다 . 실시간 수치는 매체마다 약간씩 달라질 수 있으므로, 현재 점수에 대한 유일한 권위 있는 출처는 사이트 자체다.
수치가 높으면 AI가 나에 대해 정확한 정보를 갖고 있다는 뜻인가요?
아니다. 확신도와 정확성은 별개다. 모델은 높은 점수에서도 전기적 세부사항을 지어내며 자신 있게 틀릴 수 있다. 제작자들은 높은 수치가 모델의 설명이 맞다는 증거가 아니라, 모델이 확신하고 있다는 뜻일 뿐이라고 명확히 말한다 . 이 수치는 기억 강도를 측정할 뿐 신뢰성을 측정하지 않으며, 이 도구는 실제 학습 데이터와 자신감 있는 허구를 구분할 수 없다 . 모델이 당신에 대해 하는 구체적인 주장은 항상 검증해야 한다.
작은 모델에 등장하는 것이 왜 더 강한 관련성 신호인가요?
Qwen3 8B 같은 소형 오픈 가중치 모델은 보유할 수 있는 사실이 훨씬 적고, 가장 전 세계적으로 두드러진 엔티티만 남기는 경향이 있다. 그래서 이런 모델이 기억한다는 것은 대형 프런티어 시스템에 등장하는 것보다 더 강한 기억 신호다 . 대형 프런티어 모델은 긴 꼬리 지식까지 넓게 다루기 때문에 비교적 작은 인물도 많이 인식한다. 반면 7B-8B 모델은 제한된 용량을 가장 중요한 대상에게 배분해야 한다. In the Weights는 이 희소성을 관련성 필터로 보고, 작은 모델의 회상을 더 크게 가중한다.
콘텐츠를 더 많이 발행하면 수치를 높일 수 있나요?
직접적으로는 아니다. 가중치는 학습 컷오프 시점에 고정되므로, 새 콘텐츠는 현재 모델 세대에는 아무런 영향을 주지 않는다. 새 자료는 미래 모델이 그것으로 학습될 때에만 도움이 된다. 그래서 이 점수는 다음 배포가 아니라 학습 주기로 측정되는 후행 지표다 . 실무적으로는 다음 학습 실행 이후가 아니라 그 이전에, 널리 스크랩되는 권위 높은 출처에 오래 남는 인용을 구축하는 것이 중요하다.









