
대형 언어 모델이 텍스트를 생성하는 주된 방식, 즉 토큰을 하나씩 왼쪽에서 오른쪽으로 엄격하게 만들어 가는 방식만이 유일한 길은 아닙니다. 2026년 2월 24일 발표된 Inception의 Mercury 2는 이 제약을 완전히 걷어냈고, 개발자들이 주목해야 할 이유는 이 모델이 제시한 처리량 수치에 있습니다.
확산 디코딩: Mercury 2가 왼쪽에서 오른쪽 예측을 건너뛰는 이유
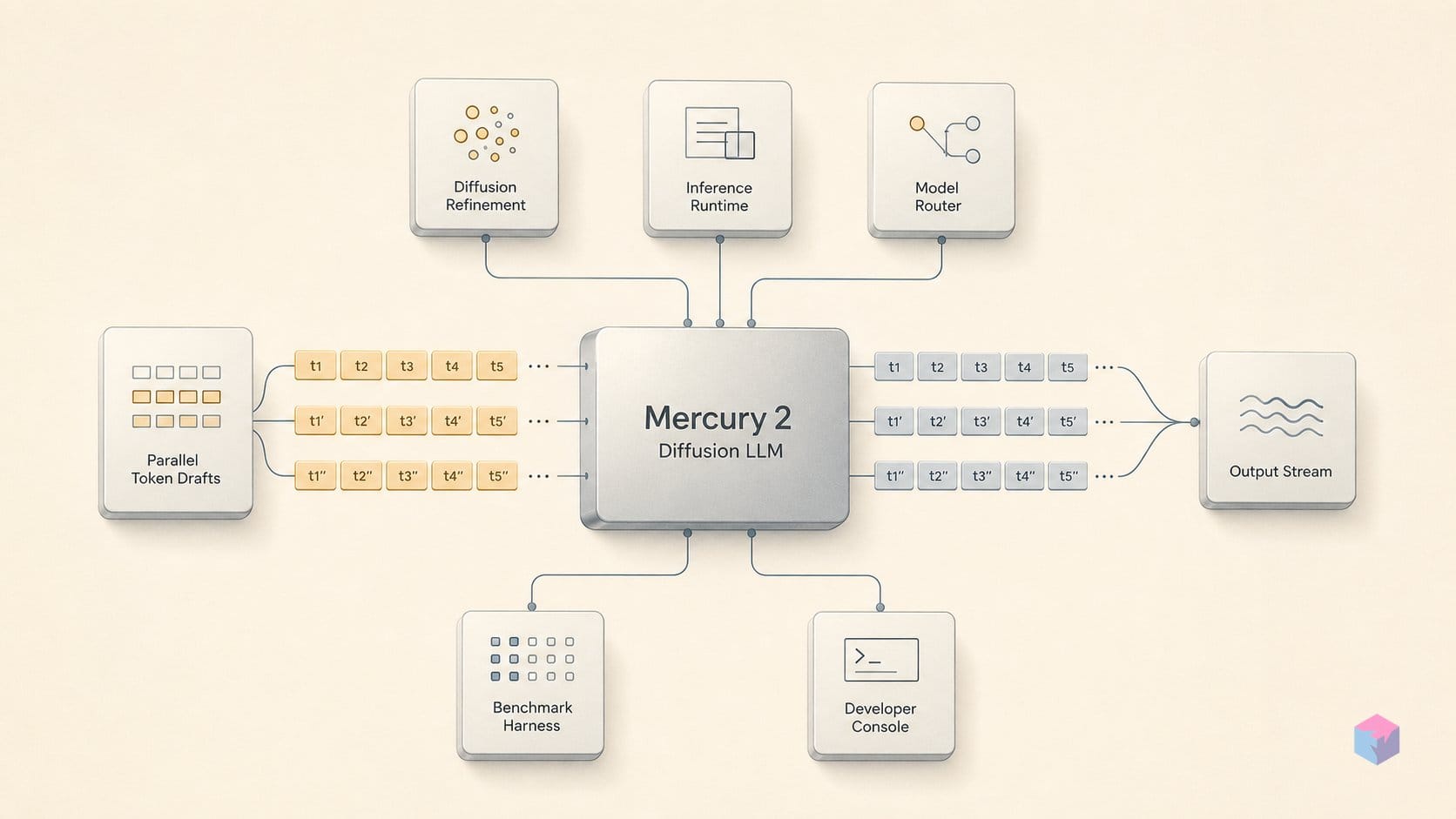
Mercury 2는 확산 기반 대형 언어 모델입니다. 다음 토큰을 순차적으로 예측하는 대신, 완전히 마스킹되었거나 노이즈가 섞인 시퀀스에서 시작해 작고 고정된 횟수의 forward pass 동안 모든 위치를 병렬로 반복 디노이징하며 출력이 수렴할 때까지 다듬습니다. Inception은 NVIDIA Blackwell GPU에서 1,009 tok/s, 즉 초당 1,000토큰 이상에 도달한다고 보고했습니다. 이는 프런티어 자기회귀 모델에서 일반적으로 보이는 약 100 tok/s와 대비됩니다 . 이 속도 차이가 이 제품의 핵심 논지입니다.
아키텍처 자체는 여전히 Transformer입니다. 달라지는 것은 생성 목표입니다. 각 디노이징 pass는 부분 답변에 토큰을 덧붙이는 대신 전체 출력을 동시에 정제합니다. 이는 Stable Diffusion 같은 이미지 생성기의 바탕에 있는 거친 형태에서 세부 형태로 수렴하는 원리를 텍스트에 적용한 것입니다. Inception은 Mercury를 시퀀스가 안정될 때까지 여러 토큰을 병렬로 예측하도록 학습된 Transformer 기반 확산 LLM이라고 설명합니다 . 이 모델은 토큰 하나를 만든 뒤 그 토큰을 조건으로 다음 토큰을 생성하지 않습니다. forward pass마다 여러 위치를 함께 업데이트합니다.
호출 수준에서 보면 이 차이는 구체적으로 드러납니다. 자기회귀 모델은 부분 응답을 내보내고 이를 확장합니다. Mercury 2는 완성된 답변으로 수렴합니다. 이 차이는 스트리밍 API에서도 보입니다. diffusing: true를 설정하면 증가분 토큰 델타가 아니라 중간 디노이징 상태가 스트리밍되며, 이는 여기서의 생성이 표준 스트리밍 텍스트 엔드포인트와 구조적으로 다르다는 제품 수준의 신호입니다 . 답변이 타이핑되는 것이 아니라 서서히 해상도를 얻는 모습을 보게 됩니다.
앞에서 짚고 넘어가야 할 열린 질문이 하나 있습니다. 이후의 논지가 여기에 기대고 있기 때문입니다. 위치를 병렬로 업데이트한다고 해서 출력에 제약이 없다는 뜻은 아니지만, 짧은 시퀀스 길이에서의 수렴 동작과 품질은 다음 토큰 예측과 다릅니다. 그 절충은 특정 추론 체인에서 나타나는 경향이 있으며, 확산 LLM에는 알려진 구조적 비용도 있습니다. 추론이 더 빠르더라도 학습 효율은 자기회귀 모델보다 떨어진다는 점입니다 . 그 속도가 실제 배포 우위로 이어지는지는 워크로드 형태, 동시성, 프롬프트 길이, 그리고 설정한 품질 기준에 달려 있습니다. 다음 섹션들은 바로 그 질문들을 살펴봅니다.
1,009/s 수치는 어디에서 나왔나
초당 1,009토큰이라는 헤드라인은 NVIDIA Blackwell GPU에서 측정했다는 Inception 자체 보고에서 나온 것으로, Artificial Analysis 평가를 인용합니다. 완전히 독립적으로 재현된 결과가 아니라 벤더가 인용한 측정치입니다 . 이 숫자에는 앞선 흐름이 있습니다. 2025년 6월 기술 보고서는 H100 GPU에서 Mercury Coder Mini가 1,109 tok/s를 기록했다고 측정했고 , Mercury 2는 같은 처리량 우선 프레이밍을 더 새로운 하드웨어로 이어갑니다. 공식 출처에서는 모델 가중치, 파라미터 수, 전체 학습 코퍼스를 공개하지 않았기 때문에, 이 속도 주장은 재현 가능한 공개 산출물이 아니라 해당 평가 하네스에 기대고 있습니다.
이 수치가 의미 있게 읽히는 이유는 Mercury 2가 겨냥하는 성능 계층에서의 격차 때문입니다. Inception이 보고한 같은 비교에서 GPT-4o Mini는 약 59 tok/s, Claude 3.5 Haiku는 약 61 tok/s로 동작합니다 . 같은 작고 빠른 모델 범주에서 대략 17배 차이가 나는 셈입니다. Inception은 Mercury 2의 추론 점수가 Claude 4.5 Haiku 및 GPT-5.2 Mini와 경쟁 가능하면서도 처리량은 약 한 자릿수 배 이상 높다고 설명합니다 .
보고된 벤치마크 점수, 즉 Inception 출처의 수치는 AIME 2025 약 91.1, GPQA 약 73.6, IFBench 약 71.3, LiveCodeBench 약 67.3, SciCode 약 38.4입니다 . 이는 제3자 검증이 아니라 벤더가 제시한 품질 포지셔닝으로 읽는 편이 맞습니다.
| 지표 | Mercury 2 | GPT-4o Mini | Claude 3.5 Haiku |
|---|---|---|---|
| 처리량(tok/s) | ~1,009 (Blackwell) | ~59 | ~61 |
| AIME 2025 | ~91.1 | n/a | n/a |
| GPQA | ~73.6 | n/a | n/a |
| LiveCodeBench | ~67.3 | n/a | n/a |
| 출력 가격(100만 토큰당) | $0.75 | n/a | n/a |
처리량과 벤치마크 수치는 Artificial Analysis를 통해 Inception이 보고한 값이며, 비교 모델 처리량은 Inception의 Mercury 비교에서 가져온 것입니다 .
"Fastest reasoning LLM"은 Inception이 이번 출시에 붙인 라벨입니다 . 공식 벤치마크 범주가 아니라 벤더의 포지셔닝입니다. 현재까지 가장 신뢰할 만한 독립 신호는 Mercury 2보다 앞서 나온 것입니다. Copilot Arena에서 Mercury Coder Mini는 품질 2위, 지연 시간 1위를 기록했으며 지연 시간은 약 0.25초였습니다 . 이는 자체 보고 처리량 수치가 아니라 사용자가 순위를 매기는 정면 비교 테스트입니다. 아직 Mercury 2 세대 자체를 직접 다루지는 않지만, 속도 우위가 Inception의 하네스 밖에서도 유지되는지를 방향성 있게 읽는 데 유용합니다.
Mercury의 중간 상태에서 diffusing: true가 보여주는 것
Mercury 2는 OpenAI 호환 API 뒤에서 제공되므로, 전환은 대부분 재작성이라기보다 설정 변경에 가깝다. 공식 문서는 표준 v1/chat/completions 경로에 모델 ID mercury-2를 배정한다 . 즉 기존 OpenAI SDK 코드는 Inception의 base URL을 가리키기만 하면 일반 completion에서는 그대로 실행된다. 앞선 섹션에서 다룬 diffusion 메커니즘은 개발자가 이미 쓰고 있는 동일한 요청 및 응답 형태 뒤에 숨겨진다.
기저 모델을 드러내는 API 동작은 diffusing: true 스트리밍 플래그 하나다. 이 값을 설정하면 서버는 점진적인 토큰 delta 대신 각 중간 denoising 상태를 스트리밍한다 . 이는 의미 있는 차이다. 표준 스트리밍 클라이언트는 토큰 단위로 단조롭게 늘어나는 출력을 기대하지만, Mercury는 전체 시퀀스의 초안을 차례로 정제해 내보낸다. 실제로는 두 가지를 얻는다. 수렴 동작을 관찰하고 디버그할 방법, 그리고 스피너로 진행 중인 척하는 대신 실제 생성 상태를 반영하는 입력 표시기를 구동할 방법이다.
Mercury Edit 2는 별도 제품이며, 채팅용 드롭인 대체품이 아니다. 모델 ID는 mercury-edit-2이고, fill-in-the-middle용 v1/fim/completions와 next-edit prediction용 v1/edit/completions를 제공한다 . 컨텍스트 창은 32K로, Mercury 2 채팅의 128K보다 작다 . 이는 편집 모델이 긴 대화 상태가 아니라 로컬 코드 범위를 겨냥한다는 점을 보여준다.
가격은 두 모델 모두 동일해 예산 산정이 단순하다. Inception이 제시한 가격은 다음과 같다.
- 입력 토큰 100만 개당 $0.25
- 캐시된 입력 토큰 100만 개당 $0.025
- 출력 토큰 100만 개당 $0.75
신규 API 계정은 무료 토큰 1,000만 개도 받는다 . 도입을 확정하기 전에 자체 지연 시간 목표를 기준으로 diffusing: true를 벤치마크하기에 충분한 여유다.
Mercury Edit 2: Fill-in-the-Middle와 KTO로 조정한 선별성
Mercury Edit 2는 next-edit prediction을 위해 설계된 diffusion LLM으로, 2026년 3월 30일 출시됐다 . 단일 범위를 왼쪽에서 오른쪽으로 완성하는 대신, 최근 편집 내용과 주변 코드베이스 컨텍스트를 함께 입력받아 diffusion을 통해 후보 편집을 병렬로 생성한다. Inception은 이 모델이 수락된 편집을 48% 늘리고, preference alignment 이후 표시하는 편집을 27% 더 선별적으로 만들었다고 보고한다 . IDE 작업에서는 두 번째 수치도 첫 번째만큼 중요하다.
선별성 향상은 KTO 단계에서 나온다. KTO, 즉 Kahneman-Tversky Optimization은 표시되는 completion 수를 최대화하기보다 더 적고 신뢰도 높은 제안을 선호하도록 인간 선호 피드백에 맞춰 모델을 정렬한다(video: AI Revolution). 에디터 통합에서 이것이 실질적인 지렛대다. 제안 피로는 실제 도입을 막는 제약이고, 정확한 편집 세 개를 보여주는 모델이 사용자가 닫아야 하는 제안 열 개를 띄우는 모델보다 낫다. 27% 더 높은 선별성은 잘못된 팝업 하나하나가 다음 팝업을 무시하도록 사용자를 학습시키는 도구에서 방향상 맞는 절충이다 .
Mercury Edit 2는 모델 ID mercury-edit-2 아래 두 엔드포인트를 제공한다. fill-in-the-middle용 v1/fim/completions와 next-edit prediction용 v1/edit/completions다 . FIM 엔드포인트는 표준 prefix/suffix 구조를 받기 때문에 기존 자동완성 배관에 큰 변경 없이 들어간다. next-edit 엔드포인트가 더 독특하다. 주변 편집 흐름이 암묵적 컨텍스트를 제공하는 에디터를 위해 만들어졌으므로, 사용자가 방금 무엇을 바꿨는지 설명하는 프롬프트를 직접 만들 필요가 없다. 최근 diff 자체가 신호다.
FIM과 next-edit 모드 모두 컨텍스트는 32K다. Mercury 2의 128K 채팅 창보다 좁은데, 모델이 긴 대화 상태가 아니라 로컬 코드 범위를 겨냥하기 때문이다 . 48%와 27% 수치는 자체 보고이며 Inception의 자체 선호 데이터셋과 연결돼 있다는 점도 짚어둘 필요가 있다. 독립적인 에디터 벤치마크가 나오기 전까지는 벤더 관점의 수치로 보는 편이 맞다.
확산 디코딩이 이기는 경우와 그렇지 않은 경우
확산 디코딩은 동시 요청이 많고 지연 시간이 병목인 워크로드에서는 확실히 우세하지만, 프런티어급 추론 깊이나 자체 호스팅 제어권이 속도보다 더 중요한 곳에서는 힘이 빠진다. 낙관론의 근거는 측정 가능한 처리량 격차다. Inception은 NVIDIA Blackwell GPU에서 Mercury 2가 초당 1,009토큰을 처리한다고 밝히며, 프런티어 자기회귀 모델의 일반적인 처리 속도인 초당 약 100토큰과 대비한다 . 벤치마크 점수가 비슷하다면, 이는 단순한 지연 시간 문제가 아니라 요청당 비용 문제로 바뀐다.
가장 큰 이점을 얻는 워크로드는 짧고 반복적인 호출이 많고, 모든 밀리초와 모든 토큰이 대규모로 과금되는 유형이다.
- 자동완성과 다음 편집 예측 — 1초 미만 응답 자체가 제품 가치이며, Mercury Coder Mini는 이미 Copilot Arena에서 약 0.25초의 지연 시간으로 1위를 기록했다 .
- 에이전트 루프 — 작업 하나에 수십 번의 모델 호출을 날리는 체인에서는 호출당 지연 시간 절감이 그대로 누적된다.
- 실시간 음성, RAG 요약, 구조화 추출 — 이 영역에서는 깊은 다단계 추론보다 처리량과 스키마 준수가 품질 기준을 좌우한다.
특히 라우팅과 추출에서는 Mercury 2의 128,000토큰 컨텍스트 창과 네이티브 JSON 스키마 구조화 출력이 결합되어, 꽤 현실적인 드롭인 대체재가 된다 . 라우터가 유효한 enum을 빠르게 반환하기만 하면 되는 상황이라면 프런티어급 추론은 과하고, Mercury의 처리량이 결정적 요인이 된다.
비관론은 구조적인 문제에서 나온다. 확산 언어 모델에는 잘 알려진 학습 비효율 페널티가 있다. 자기회귀 모델과 같은 역량에 도달하려면 더 많은 학습 컴퓨팅이 필요하며, Inception도 이 트레이드오프를 인정한다(동영상: AI Marketing Navigator). 이 아키텍처를 바라보는 업계의 한 표현을 빌리면 다음과 같다.
"The inference speed-up is real, but it's bought with training inefficiency — that's the diffusion tax," — Inception 자체 브리핑에서 논의된 트레이드오프를 풀어 말한 표현 (source: AI Marketing Navigator).
이 비용은 Inception이 파인튜닝을 얼마나 공격적으로 반복하거나 맞춤형 데이터 어댑터를 출시할 수 있는지를 제약한다.
빌더 입장에서 더 깊은 문제는 검증 가능성이다. 공식 출처에는 모델 가중치, 파라미터 수, 전체 학습 코퍼스 세부 정보가 공개되지 않았다 . 그 결과 독립적인 벤치마크 재현은 불가능하고, 파인튜닝 가능성은 평가할 수 없으며, 자체 호스팅 추론 비용 추정도 막힌다. 전체 검증 사슬, 즉 AIME 2025 약 91.1, GPQA 약 73.6, LiveCodeBench 약 67.3이라는 수치 는 Inception이 제공한 평가와 Artificial Analysis 및 Copilot Arena 인용이라는 얇은 층을 신뢰하는 데 달려 있다. 지연 시간이 병목인 작업이라면 받아들일 만한 베팅이지만, 감사 가능성이나 온프레미스 제어가 필요한 작업에서는 바로 그 지점에서 확산 모델의 우위가 멈춘다.
무엇을 이전하고 무엇을 자기회귀로 남길까

p95 지연 시간이 가장 큰 제약이고 AIME/GPQA급 품질이 최소 기준을 넘는 워크로드는 이전하세요. 긴 상호 의존적 추론 체인이나 독점 파인튜닝에 의존하는 것은 자기회귀 방식으로 남기는 편이 맞습니다. Mercury 2는 Blackwell에서 약 1,009 tokens/sec로 동작하며, 프런티어 자기회귀 모델의 약 100 tok/s와 비교됩니다 . 따라서 이전 여부는 작업이 엄격한 왼쪽-오른쪽 조건화 대신 병렬 디노이징을 허용하느냐의 문제입니다.
Quick Answer: p95 지연 시간을 250ms 미만으로 맞추는 것이 제약이라면 대량 자동완성, fill-in-the-middle, 50회 이상 호출되는 에이전트 루프, 음성 라우팅, 구조화 추출을 Mercury 2로 옮기세요. 깊은 추론 체인과 파인튜닝된 워크로드는 자기회귀로 유지하는 것이 좋습니다. Mercury 2는 파인튜닝을 제공하지 않으며, 출력 비용은 1M 토큰당 $0.75입니다 .
명확한 이전 후보는 지연 시간과 비용에 묶인 워크로드입니다. 대량 코딩 자동완성, fill-in-the-middle, 리팩터링, 세션당 50회 이상 반복 호출을 발생시키는 에이전트 루프, 실시간 음성 라우팅, RAG, 요약, 구조화 추출이 여기에 해당하며, 이는 Inception이 직접 겨냥하는 워크로드 형태이기도 합니다 . 이들은 공통적으로 작은 호출이 많고, 호출당 지연 시간을 줄인 효과가 누적되며, AIME 2025 약 91.1과 LiveCodeBench 약 67.3이면 충분한 경우입니다 .
모델의 장점이 도움이 되지 않는 경우는 자기회귀로 남기세요. 각 단계가 이전 출력에 강하게 의존하는 긴 상호 의존적 추론 체인은 병렬 개선보다 왼쪽에서 오른쪽으로 생성하는 방식에 더 잘 맞습니다. 독점 파인튜닝이 필요한 것도 제외됩니다. Mercury 2 파인튜닝은 제공되지 않습니다. 또한 프런티어급의 개방형 창작 작업은 Mercury 2가 최고 수준이 아니라 "경쟁력 있는 범위"라고 내세우는 구간보다 위에 있습니다.
판단 기준은 구체적입니다. 호출당 p95 지연 시간 예산이 250ms 미만이고, AIME 약 91 / LiveCodeBench 약 67 수준의 품질 하한으로 충분하다면 Mercury 2를 현재 제공업체와 직접 A/B 테스트할 가치가 있습니다. 출력 비용은 1M 토큰당 $0.75입니다 . 그렇지 않다면 자기회귀 기본값은 여전히 제 역할을 합니다.
| 워크로드 유형 | 권장 접근 방식 | 지연 시간 신호 | 품질 하한 | 파인튜닝 |
|---|---|---|---|---|
| 대량 코딩 자동완성 / FIM | Mercury 2 (Edit 2) | p95 < 250ms | LiveCodeBench 약 67이면 충분 | 사용 불가 |
| 에이전트 루프, 세션당 50회 이상 호출 | Mercury 2 | 지연 시간 × 호출 수가 지배적 | AIME 약 91이면 충분 | 사용 불가 |
| 실시간 음성 라우팅 / RAG / 추출 | Mercury 2 | p95가 병목 | GPQA 약 73이면 충분 | 사용 불가 |
| 긴 상호 의존적 추론 체인 | 자기회귀 | 지연 시간은 부차적 | 단계별 정확도가 중요 | 제공업체가 허용하는 경우 |
| 도메인 특화 튜닝 모델 | 자기회귀 | 가변적 | 맞춤형 | 필수 |
| 프런티어 창작 / 개방형 작업 | 자기회귀 | 지연 시간은 부차적 | 경쟁력 있는 범위 이상 | 제공업체가 허용하는 경우 |
| 혼합 파이프라인 | 하이브리드(호출별 라우팅) | 단계별 | 단계별 | 단계별 |
AWS SageMaker, Azure Foundry, Inception 자체 가입에서 쓰는 Mercury 2
Mercury 2는 세 가지 경로로 개발자에게 제공되며, 어떤 경로를 고르느냐에 따라 지연 시간과 과금이 모두 달라집니다. 직접 경로는 inceptionlabs.ai의 Inception 자체 OpenAI 호환 엔드포인트입니다. 가입 시 1,000만 무료 토큰을 제공하고, 아직 이전하지 않은 기존 고객에게는 Mercury 1도 계속 제공합니다 . 대신 관리형 인프라를 원하는 팀이라면 두 주요 클라우드에서도 이 모델군을 사용할 수 있습니다.
- AWS: Mercury와 Mercury Coder는 2025년 8월 27일부터 Amazon Bedrock Marketplace와 SageMaker JumpStart를 통해 제공되어 왔습니다. 모델 배포 관리는 필요 없고 AWS 측 요율에 따른 토큰당 과금이 적용됩니다. AWS는 H100 GPU에서 최대 1,100 tokens/sec와 128,000 토큰 컨텍스트를 제시합니다 .
- Azure AI Foundry: 미국 및 캐나다 리전에서 제공되며, 소프트웨어 라이선스는 시간당 $0.78입니다(컴퓨트는 별도 과금). 권장 인스턴스는 ND-H100-v5이며, tool calling과 JSON-schema 구조화 출력도 지원합니다 .
클라우드 호스팅 경로를 확정하기 전에 알아둘 실무상 주의점이 하나 있습니다. 관리형 인프라 계층은 자체 네트워크와 오케스트레이션 오버헤드를 더하므로, 실제 처리량은 Inception의 직접 수치보다 낮게 나옵니다. Blackwell에서 1,009 tokens/sec라는 수치 때문에 평가를 시작한 것이라면 , 표준화하기 전에 각 경로에서 실제 호출 형태에 맞춘 동시성 테스트를 실행하세요. 프롬프트 길이, 배치 크기, 목표 품질까지 맞춰야 합니다. 핵심은 헤드라인 속도를 Inception 자체 엔진이 도달하는 상한으로 보고, 그 숫자가 그대로 옮겨간다고 가정하지 말고 선택한 호스트를 기준으로 벤치마크하라는 것입니다.
자주 묻는 질문
확산 언어 모델은 무엇이며 자기회귀 모델과 어떻게 다른가요?
확산 언어 모델(dLLM)은 마스킹되거나 노이즈가 섞인 전체 길이 시퀀스에서 시작해, 작고 고정된 횟수의 순전파 동안 모든 위치를 병렬로 반복 디노이징하면서 텍스트를 생성합니다. Stable Diffusion 같은 이미지 생성기의 거친 단계에서 세밀한 단계로 가는 원리를 텍스트에 적용한 방식입니다. 자기회귀 모델은 반대로 작동합니다. 토큰을 하나씩, 엄격하게 왼쪽에서 오른쪽으로 예측하므로 N개 토큰에는 대략 N번의 순전파가 필요합니다. Mercury 2는 Transformer 백본은 유지하되 디코딩 루프를 바꿔, 출력이 수렴할 때까지 한 번의 패스에서 여러 토큰을 예측합니다 . 실제 차이는 처리량에서 드러납니다. 병렬 디노이징 덕분에 Inception이 토큰별 생성보다 훨씬 높은 수치를 제시할 수 있습니다.
기존 코드에서 Mercury 2로 이전하려면 무엇이 필요한가요?
채팅 완성 기준으로는 구조적으로 거의 바뀌지 않습니다. Mercury 2는 OpenAI 호환 API 뒤에서 동작하므로 모델 ID를 mercury-2로 바꾸고, base URL을 Inception 엔드포인트로 지정하면 표준 OpenAI SDK 코드가 v1/chat/completions에서 그대로 작동합니다 . 스트림에서 단순한 토큰 델타가 아니라 중간 디노이징 상태를 노출하고 싶을 때만 diffusing: true를 추가하면 됩니다 . Mercury Edit 2는 채팅을 그대로 대체하는 모델이 아닙니다. fill-in-the-middle과 next-edit prediction을 위해 별도 엔드포인트 경로(v1/fim/completions, v1/edit/completions)를 사용하므로 IDE형 통합은 이 라우트들을 직접 대상으로 삼습니다.
Mercury 2의 AIME 91.1은 GPT-5.2 Mini 및 Claude Haiku와 비교해 어떤 수준인가요?
Inception은 Mercury 2를 추론 평가에서 Haiku/Mini 등급과 경쟁 가능한 범위에 놓고 있습니다. AIME 2025는 약 91.1, GPQA는 약 73.6, LiveCodeBench는 약 67.3으로, 품질 면에서 Claude 4.5 Haiku와 GPT-5.2 Mini에 견줄 만하다고 설명합니다 . 차이가 크게 벌어지는 지점은 속도입니다. 비슷한 역량 등급의 프런티어 자기회귀 모델이 약 100 tok/s에 가까운 것과 달리, Blackwell GPU에서 약 1,009 tok/s를 제시합니다 . 다만 벤치마크 수치는 Inception 측 자료로 보아야 합니다. 아직 완전히 독립적인 재현 결과가 없으므로, 품질 주장은 처리량 주장보다 검증 수준이 낮습니다.
Mercury 2는 단순 예측 외에 어떤 기능을 더하나요?
빠른 토큰 생성 외에도 Mercury 2는 네이티브 도구 사용, JSON 스키마 기반 구조화 출력, 128,000토큰 컨텍스트 창, 조절 가능한 추론 깊이를 제공하며, 모두 OpenAI 호환 채팅 API 뒤에서 사용할 수 있습니다 . 이 기능 세트는 순수 텍스트 완성보다는 지연 시간과 비용 제약이 큰 워크로드, 즉 에이전트 루프, RAG, 라우팅, 구조화 추출을 겨냥합니다. 에디터 워크플로의 경우 함께 제공되는 Mercury Edit 2가 별도 엔드포인트를 통해 fill-in-the-middle과 next-edit prediction을 추가하며, 해당 모드에서는 32K 컨텍스트 창을 사용합니다 .
Inception은 Mercury 2 기술 보고서에서 무엇을 공개하지 않았나요?
투명성의 빈틈은 실사 과정에서 중요합니다. 검토한 공식 출처 기준으로 Inception은 모델 가중치를 공개하지 않았고, 파라미터 수나 학습 코퍼스도 상세히 밝히지 않았습니다. 따라서 독립 검증은 상당 부분 인용된 Artificial Analysis와 Copilot Arena 평가에 의존합니다 . 1,009 tok/s라는 대표 수치는 독립 재현이 아니라 Inception이 인용한 벤치마크에서 나온 것이며, “fastest reasoning LLM”도 공식 벤치마크 범주라기보다 공급사 포지셔닝에 가깝습니다 . 또한 공개 arXiv 보고서(2506.17298)는 이전 Mercury Coder 계열을 다루며, Mercury 2의 세부 내용은 2026년 2월 출시 발표에 더 많이 의존한다는 점도 유의해야 합니다 .









