
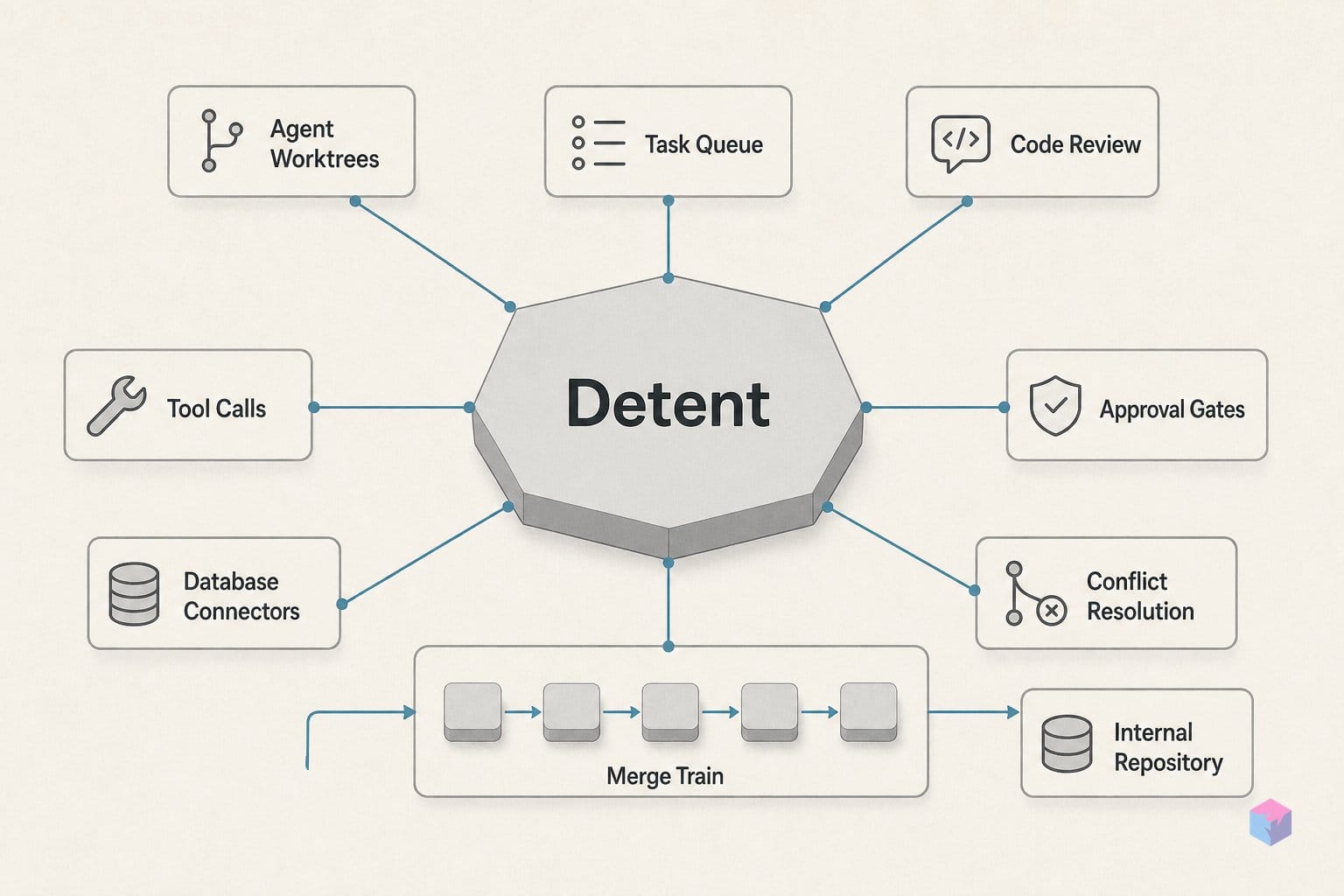
같은 저장소에서 코딩 에이전트 다섯 개를 동시에 돌리면 어려운 지점은 생성이 아닙니다. 다섯 묶음의 변경사항을 서로 덮어쓰지 않게 main에 안착시키는 일입니다. 전용 git worktree와 merge queue를 함께 쓰면 이 과정을 안전하게 만들 수 있습니다.
전용 worktree와 merge queue를 함께 쓰면 무엇이 달라질까요?
전용 worktree와 merge queue가 주는 보장은 두 가지입니다. 병렬로 움직이는 에이전트들이 작업 중 서로의 파일을 덮어쓰지 않고, 각 브랜치가 한 번에 하나씩 통합되어 충돌이 trunk를 조용히 망가뜨리는 대신 공개적으로 드러난다는 점입니다. worktree는 격리를 맡고, queue는 순서를 맡습니다. 둘을 함께 쓰면 혼란스러운 동시 편집이 검토 가능한 git merge의 순서 있는 흐름으로 바뀝니다.
빠른 답변: git worktree는 하나의 object database를 공유하되 자체 HEAD와 index를 유지하는 연결된 checkout입니다. 그래서 worktree-A의 수정은 worktree-B의 tracked file을 건드리지 않습니다. 그다음 merge queue가 어떤 브랜치가 먼저 들어갈지 직렬화합니다. 이 순서가 중요한 이유는 AI 에이전트 PR의 27.67% 가 merge conflict를 만나기 때문입니다.
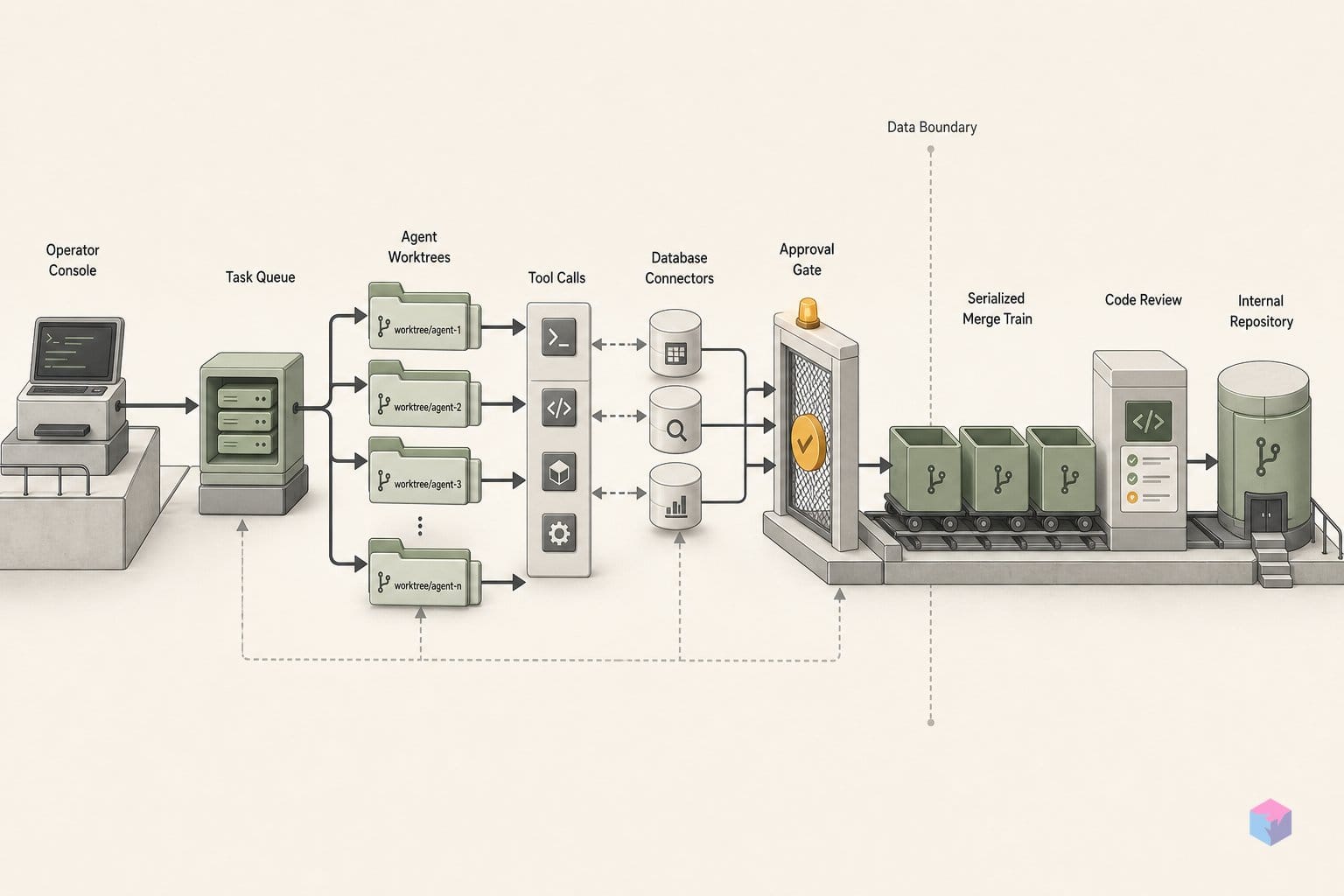
먼저 격리부터 봐야 합니다. worktree는 하나의 저장소에 여러 working tree를 붙이는 Git의 공식 메커니즘입니다. 연결된 각 worktree는 하나의 repository object database를 공유하면서도 worktree별 HEAD와 index를 따로 유지합니다 . 실제로는 각 에이전트가 자기 디렉터리와 브랜치를 받는다는 뜻입니다. 그래서 두 에이전트가 같은 순간 auth.py를 편집하더라도 하나의 index나 lock을 두고 다투지 않습니다. worktree-A의 쓰기는 통합 전까지 worktree-B에 보이지 않습니다 .
이 격리는 충돌을 없애는 것이 아니라 충돌의 성격을 바꿉니다. 각 에이전트가 별도 브랜치에 커밋하기 때문에 같은 파일에 대한 수정이 실시간 file-lock 경합으로 부딪히지 않습니다. 대신 충돌은 merge 시점으로 미뤄지고, 그때 표준 git 도구가 이를 감지해 읽고 해결할 수 있는 명시적인 conflict marker를 남깁니다. 잠재적인 런타임 손상이 눈에 보이고 검토 가능한 diff로 바뀌는 셈입니다.
Anthropic의 Claude Code 문서도 바로 이 구성을 권장합니다. claude --worktree feature-auth를 실행하면 자체 브랜치 위에 별도 checkout이 만들어지므로, 한 세션이 기능을 만드는 동안 두 번째 세션은 편집 충돌 없이 버그를 고칠 수 있습니다 . 이를 네다섯 개 세션으로 늘리면 하나의 fleet이 됩니다. 하지만 브랜치의 fleet도 결국 trunk에 도달해야 합니다.
그 일을 merge queue가 맡습니다. queue는 진입을 직렬화합니다. branch-1을 먼저 merge하면 branch-2의 pipeline은 이제 branch-1의 변경사항이 이미 들어간 main을 기준으로 실행됩니다. 그래서 충돌은 한 번에 얽힌 묶음으로 터지지 않고 단계적으로 드러납니다. GitHub의 merge queue는 pull request에 이 방식을 적용합니다. FIFO 순서, 최신 base branch와 앞선 PR들을 포함한 검증, 1부터 100까지 설정 가능한 build concurrency와 merge limit을 제공합니다 . worktree는 에이전트들을 분리하고, queue는 누가 먼저 들어갈지 결정적으로 정합니다.
AgenticFlict의 27.67%: AI 생성 PR에서 충돌은 얼마나 자주 일어날까
AI가 작성한 pull request는 대략 네 개 중 하나꼴로 merge에서 충돌합니다. AIware 2026에 채택된 AgenticFlict는 5만9천 개 이상의 저장소에서 가져온 10만7천 개 이상의 AI 작성 PR을 대상으로 deterministic merge simulation을 실행했고, 33만6천 개 이상의 세분화된 conflict region에서 27.67%의 merge-conflict rate를 측정했습니다 . 이것이 격리와 순서 있는 queue가 필요한 실증적 이유입니다. 에이전트 기반 개발에서 충돌은 예외 상황이 아니라, 규모가 커질수록 중심에 놓이는 결과입니다.
이 수치를 신뢰할 때 중요한 부분은 "deterministic merge simulation"입니다. AgenticFlict는 자기 보고식 마찰을 설문으로 모은 것이 아니라 실제 브랜치를 git의 merge machinery로 재생했습니다. 따라서 conflict region은 휴리스틱 추정이 아니라 git이 실제로 자동 해결을 거부한 영역입니다 . 연구가 출발점으로 삼은 AI-agent PR은 14만2천 개 이상이었고, 그중 깔끔하게 시뮬레이션할 수 있는 10만7천 개 이상으로 필터링되었습니다. 그래서 27.67%는 과장된 헤드라인 수치라기보다 보수적인 하한에 가깝습니다.
이 문제가 단순한 흥미거리가 아니라 거버넌스 문제인 이유는 규모 때문입니다. 2026년 2월 9일 제출된 AIDev dataset은 OpenAI Codex, Devin, GitHub Copilot, Cursor, Claude Code 전반에 걸쳐 11만6,211개 저장소와 7만2,189명의 개발자가 만든 93만2,791개의 agent-authored PR을 정리했습니다 . 이런 규모에 AgenticFlict의 비율을 적용하면 conflict resolution은 PR 하나의 성가신 일이 아니라 통합 경로에서 반복되는 비용이 됩니다. 누군가, 혹은 어떤 merge train이 이 비용을 결정적으로 흡수해야 합니다.
| Dataset | AI 작성 PR | 저장소 | 핵심 결과 |
|---|---|---|---|
| AgenticFlict (AIware 2026) | 142K+ 분석, 107K+ merge simulation | 59K+ | 27.67% 충돌률 · 336K+ conflict region |
| AIDev (Feb 9, 2026) | 932,791 | 116,211 | 에이전트 5개(Codex, Devin, Copilot, Cursor, Claude Code) · 개발자 72,189명 |
이 비율이 다섯 도구에 고르게 분포되어 있을까요? 공개 수치는 27.67%를 에이전트 vendor별이나 repository-size bracket별로 나누어 제공하지 않습니다. 따라서 도구별 충돌 표를 만들면 측정값이 아니라 창작이 됩니다. 이 점은 짚고 넘어갈 필요가 있습니다. 충돌 메커니즘은 특정 vendor의 문제가 아니라 구조적 문제이기 때문입니다. 충돌 표면적은 저장소 공유와 함께 커집니다. 같은 코드베이스에 쓰는 동시 세션이 많을수록 임의의 두 브랜치가 같은 파일과 같은 hunk를 건드릴 확률이 높아집니다. 조용한 저장소에서 단일 에이전트가 스스로와 충돌하는 일은 드뭅니다. 하지만 뜨거운 모듈에 다섯 에이전트를 펼쳐 놓으면 어떤 모델이 코드를 썼는지와 무관하게 겹칠 가능성이 통계적으로 높습니다.
이렇게 보면 헤드라인의 의미도 달라집니다. 27.67%는 특정 코딩 에이전트에 대한 고발이 아닙니다. 조율된 landing 없이 병렬 저작을 했을 때 예상되는 출력입니다. worktree는 쓰기를 서로 떨어뜨려 놓지만, 33만6천 개 이상의 충돌 하나하나를 merge 시점으로 미룹니다. 운영상 남는 질문은 누가 어떤 순서로 이를 해결하느냐입니다. 바로 그 일을 하려고 직렬화된 merge train이 존재합니다.
CAID의 코디네이터 주도 분해가 PaperBench에서 거둔 성과
CAID는 이 운영상의 질문에 직접 답한다. 매니저 세션이 작업을 분해하고, 각 하위 작업을 main에서 분리된 자체 git worktree에서 실행되는 워커 세션에 넘긴 뒤, 각 워커가 자체 검증을 마치면 결과 커밋을 순서대로 병합한다. 2026년 3월 23일 제출된 논문 "Effective Strategies for Asynchronous Software Engineering Agents"는 이 구조가 단일 세션 기준선보다 PaperBench에서 26.7%포인트, Commit0에서 14.3%포인트 앞섰다고 보고한다. 이 향상은 더 강한 모델 때문이 아니라 중앙화된 작업 위임과 구조화된 통합 덕분으로 설명된다. 직렬화된 merge train이 당기는 두 가지 지렛대와 같다.
살펴볼 만한 부분은 충돌 처리 정책이다. 워커의 커밋이 깔끔하게 병합되지 않더라도 CAID는 해결을 매니저에게 넘기지 않는다. 대신 해당 변경을 만든 워커가 최신 main을 가져와 자신의 worktree 안에서 충돌을 로컬로 해결한 뒤 다시 제출한다 . 해결 책임은 변경을 도입한 세션에 남는다. 그 세션이 왜 그 수정을 했는지에 대한 맥락을 갖고 있기 때문이다. 매니저는 병합 심판이 아니라 스케줄러로 남는다. 그래서 워커 수가 늘어나도 코디네이터의 일이 일정 범위 안에 머문다.
이 설계가 읽기 쉬운 이유는 모든 조정 개념이 별도 프로토콜이 아니라 기존 git 기본 요소에 대응되기 때문이다.
- 작업공간 격리 → git worktree. 각 엔지니어 에이전트는 main에서 분기한 자기 checkout을 받으므로, 병렬 쓰기가 실행 중에 서로 충돌하지 않는다(git-worktree 문서).
- 구조화된 인계 → commit / PR. 워커는 커밋을 제출함으로써 "완료했고 자체 검증했다"는 신호를 보낸다. 산출물 자체가 인계 메시지다.
- 순서 있는 통합 → 순차 병합. 매니저는 커밋을 한 번에 하나씩 병합한다. 그래서 이후 워커는 앞서 반영된 모든 변경이 이미 들어간 main을 기준으로 해결한다.
이 대응 관계 덕분에 이 패턴은 프로덕션 도구로도 깔끔하게 옮겨간다. 이미 Claude Code worktree나 OpenAI Codex 병렬 작업을 운영하는 사람이라면 격리의 절반은 갖춘 셈이고, CAID는 새 인프라가 아니라 순서를 강제하는 규율로서 통합의 절반을 제공한다.
"중앙화된 작업 위임, 비동기 실행, 격리된 작업공간, 구조화된 통합"은 CAID가 단일 에이전트 실행 대비 정확도 향상을 이끈다고 지목한 네 가지 속성이다. "Effective Strategies for Asynchronous Software Engineering Agents"의 저자들, 2026년 (source: arXiv:2603.21489).
CAID가 받아들이는 비용은 앞 절에서 언급한 바로 그것이다. 충돌은 워커가 이미 작업을 끝내고 자체 검증까지 마친 뒤, 병합 시점에 발견된다. 두 워커가 같은 영역을 수정했다면 둘 중 하나는 main을 가져와 완료했다고 생각했던 작업을 다시 해야 한다. CAID의 측정 결과는 PaperBench와 Commit0 워크로드에서는 순서 있는 순차 반영이 이런 가끔의 재작업 비용을 충분히 상쇄한다는 점을 보여준다. 하지만 이 "해결하고 다시 제출하기" 루프야말로 다음 접근법인 STORM이 쓰기 시점에 충돌을 잡아 제거하려는 마찰이다.
STORM의 조기 충돌 중재: 지연된 worktree 방식의 대안
STORM은 병합 시점이 아니라 쓰기 시점에 에이전트 충돌을 잡는 조정 계층이다. 2026년 5월 19일 제출된 이 논문은 에이전트마다 하나의 worktree를 두는 격리 방식이 충돌 감지를 비싼 사후 병합 단계로 미룬다고 주장하며, 대신 공유 작업공간 상호작용을 중재해 두 세션이 겹치는 상태를 건드리는 순간 충돌이 드러나게 한다 . 핵심은 타이밍이다. 앞선 작업이 곧 무효화할 브랜치에 세션이 큰 계산 비용을 투자하기 전에 충돌을 드러내자는 것이다.
STORM이 겨냥하는 실패 양상은 구체적이다. 지연된 worktree 방식에서는 에이전트가 전체 작업을 끝까지 수행할 수 있다. 코드를 생성하고, 자체 검증을 하고, PR을 연 뒤에야 병합 단계에서 먼저 반영된 브랜치가 같은 영역을 이미 다시 썼다는 사실을 알게 된다. 그 세션의 작업은 이제 낡은 상태가 되고, "main을 가져오고, 해결하고, 다시 제출하는" 루프가 에이전트 시간 몇 분을 버린다. STORM의 주장은 늦은 충돌 발견이 worktree 패턴의 부수적 예외가 아니라 핵심 비용이며, 두 세션이 함께 읽고 쓸 수 있는 공유 상태 계층이 그 대부분을 제거한다는 것이다 .
"에이전트마다 하나의 worktree를 두면 충돌 감지가 비싼 사후 병합 단계로 미뤄진다. 공유 작업공간 상호작용을 중재하면 쓰기 시점에 충돌을 잡을 수 있다." — STORM, "submitted May 19, 2026 (source: arXiv:2605.20563).
보고된 수치는 더 어려운 통합 워크로드에서 즉시 중재 방식에 유리하다. STORM은 Commit0-Lite에서 git-worktree 다중 세션 기준선보다 +18.7%포인트, PaperBench에서 +1.4%포인트를 기록했고, 단일 세션과 STORM을 결합한 구성은 두 벤치마크에서 각각 87.6과 78.2의 최고 점수에 도달했다 . PaperBench의 완만한 상승에 비해 Commit0-Lite의 큰 상승이 단서다. STORM은 독립적 수정이 자주 겹치는 곳에서 가장 도움이 되고, 작업이 이미 잘 분리되어 있는 곳에서는 효과가 작다. 이는 순서 있는 순차 반영이 같은 워크로드에서 효과를 낸다는 CAID의 발견과도 맞물린다. 두 논문은 통합 거버넌스가 중요한지 여부가 아니라, *언제* 감지할지를 두고 갈린다.
트레이드오프는 구조적이며, 실제로 빌더가 내려야 하는 결정도 여기에 있다. Worktree는 설정이 쉽다. 디렉터리 하나와 브랜치 하나면 몇 초 안에 격리가 생긴다. 하지만 그 단순함의 대가는 충돌이 늦게 드러날 때마다 세션 작업이 낭비된다는 점이다. 즉시 중재는 비용의 방향을 뒤집는다. 투자한 작업이 sunk cost가 되기 전에 문제를 잡지만, 모든 세션이 통신하는 공유 상태 계층이 필요하다. 이는 평범한 `git worktree`와 병합 단계보다 구축, 운영, 추론해야 할 인프라가 더 많다는 뜻이다. 겹침이 적은 작업 묶음에서는 지연된 worktree가 여전히 경쟁력 있고 더 단순하다. 에이전트가 같은 파일을 반복적으로 건드리는 조밀하고 경합이 많은 코드베이스에서는 쓰기 시점 접근법에 측정된 이득이 집중된다.
머지 트레인이 랜딩 브랜치를 받아들이고 검증하고 순서를 정하는 방식
머지 트레인은 여러 에이전트 브랜치를 정해진 랜딩 순서로 바꾸는 admission-control 계층입니다. 각 후보는 오래된 trunk 스냅샷이 아니라 대상 브랜치에 자기보다 앞서 큐에 들어간 모든 브랜치를 더한 상태를 기준으로 검증됩니다. 그래서 실제로 머지될 변경은 자신이 올라갈 정확한 상태 위에서 이미 테스트된 셈입니다. AI 에이전트가 만들어내는 규모에서도 직렬화된 통합이 안전해지는 이유가 여기에 있습니다. 브랜치는 자신의 파이프라인이 통과하고 앞선 모든 항목이 랜딩된 뒤에만 머지되므로, 머지 시점의 충돌도 한 번에 뒤엉킨 묶음으로 터지지 않고 단계적으로 드러납니다.
빠른 답변: 머지 트레인은 큐에 들어온 각 변경을 대상 브랜치와 그 앞에 줄 서 있는 모든 변경을 합친 상태에서 검증하고, 해당 파이프라인이 통과한 뒤에만 머지합니다. GitLab은 트레인당 병렬 파이프라인 기본값이 20개이며, 완전한 직렬 처리를 위한 최소값은 1입니다 ; GitHub의 merge queue는 빌드 동시성을 1부터 100까지 설정할 수 있습니다 .
GitLab merge train은 누적 검증 모델을 명확하게 드러냅니다. Premium 및 Ultimate 티어에서 사용할 수 있고, GitLab.com, Self-Managed, Dedicated에서 지원됩니다. 머지 리퀘스트가 큐에 들어가면 각 요청은 앞선 요청들과 대상 브랜치를 합친 상태와 비교됩니다. 두 번째 트레인 파이프라인은 MR-1과 MR-2에 대상 브랜치를 더한 상태에서 실행되고, 세 번째는 MR-1, MR-2, MR-3에 대상 브랜치를 더한 상태에서 실행되는 식입니다 . 각 MR은 자신의 파이프라인이 성공하고 앞서 큐에 있던 모든 MR이 머지된 뒤에만 머지됩니다. 트레인당 병렬 파이프라인 최대 기본값 20개가 처리량을 조절하는 손잡이입니다. 이를 최소값인 1로 설정하면 완전히 순차적인 처리가 됩니다 . 직렬화된 트레인은 결국 그 최소값을 쓰는 방식입니다. 병렬 파이프라인 비용을 줄이는 대신 엄격하게 하나씩만 받아들이는 것입니다.
GitHub의 merge queue도 풀 리퀘스트에 같은 거버넌스를 적용합니다. FIFO 순서를 강제하고, 임시 merge_group 브랜치를 만들며, 각 PR을 최신 base 브랜치와 큐에서 앞선 PR들을 합친 상태에서 검증합니다. 빌드 동시성과 머지 제한은 1부터 100까지 설정할 수 있습니다 . 에이전트 플릿에서 남는 설계 질문은 실패 처리입니다. 큐에 있는 항목의 파이프라인이 실패했을 때 트레인이 그 뒤의 전체 줄을 막을 것인지, 아니면 실패한 항목을 내보내고 더 짧아진 새 큐를 기준으로 후속 항목을 다시 검증할 것인지가 핵심입니다.
| 차원 | GitLab merge train | GitHub merge queue |
|---|---|---|
| 순서 모델 | 큐에 들어간 MR을 앞선 MR + 대상 브랜치 기준으로 검증 | FIFO; PR을 최신 base + 앞선 PR 기준으로 검증 |
| 격리 단위 | MR 위치마다 트레인 파이프라인 | 임시 merge_group 브랜치 |
| 최대 동시성 | 병렬 파이프라인 20개(기본값); 최소 1 = 완전 직렬 | 빌드 동시성 1–100(설정 가능) |
| 실패 처리 | 실패한 MR은 트레인에서 제거되고, 이후 MR은 다시 검증 | 실패한 PR은 제거되고, 후속 항목은 새 base 기준으로 재확인 |
| 티어 요구 사항 | Premium / Ultimate | GitHub에서 사용 가능(repo branch-protection 설정) |
에이전트 결과물을 랜딩하는 오케스트레이터 입장에서는 적용 방식이 직접적입니다. 에이전트를 격리된 worktree에서 실행한 다음, 그 브랜치들을 코드베이스가 감당할 수 있는 직렬화 수준으로 설정된 큐에 태우면 됩니다. 충돌 가능성이 낮은 작업 묶음은 처리량을 위해 여러 파이프라인을 병렬로 돌릴 수 있습니다. 반대로 밀도가 높고 자주 충돌하는 저장소라면 최소값 1의 직렬 모드가 적합합니다. 그러면 각 에이전트는 자신의 검증이 실행되기 전에 앞선 머지를 반영한 상태를 보게 됩니다. CI/CD 원시 기능은 이미 존재합니다. 오케스트레이션에서 해야 할 일은 새로운 장치를 만드는 것이 아니라 admission policy를 정하는 것입니다.
Batty, Augment Intent, Composio 오케스트레이터는 병합을 어떻게 직렬화하나
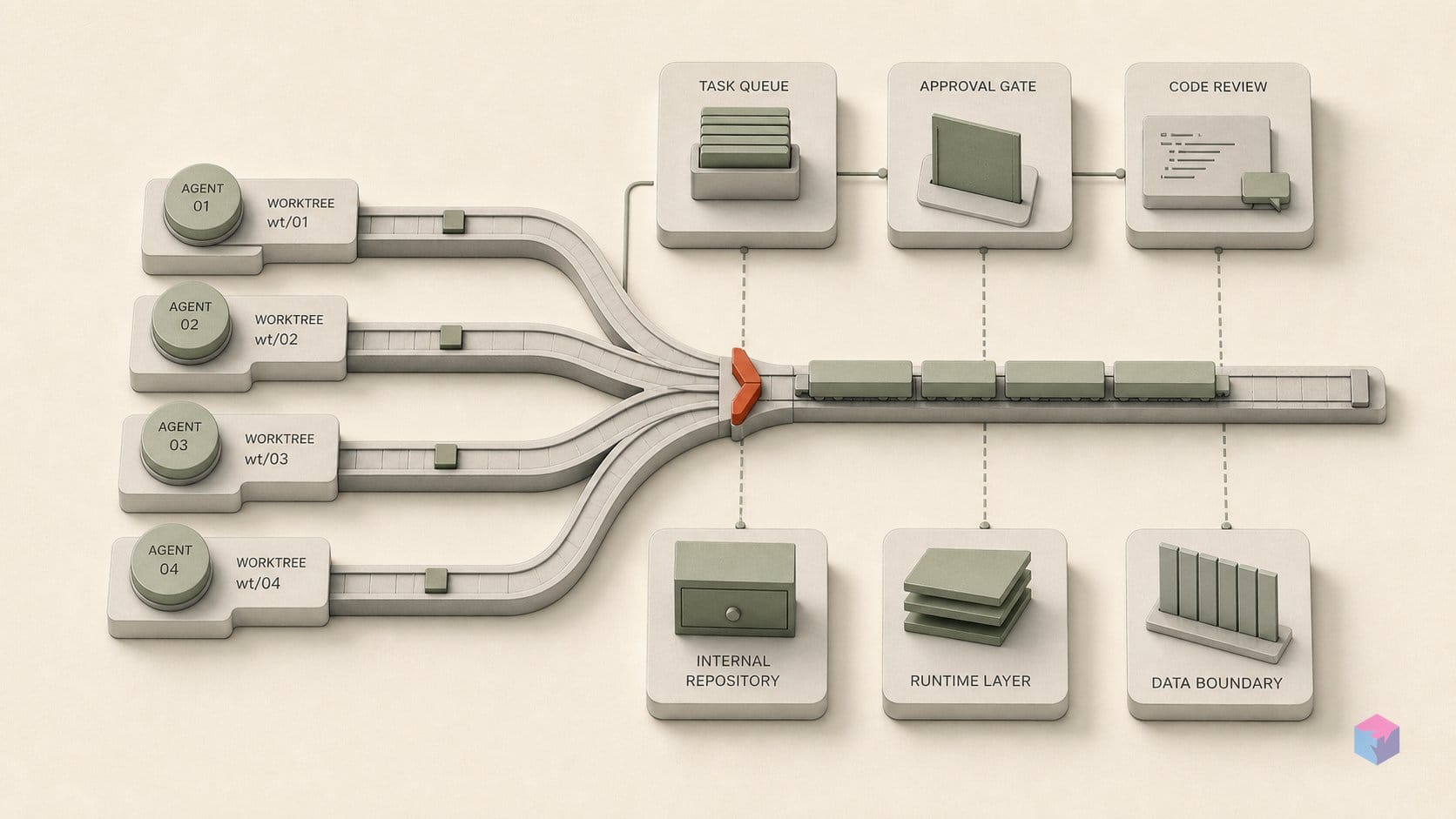
이런 승인 정책 작업이야말로 현재 오케스트레이터들이 인코딩하는 핵심이며, 각 도구는 이를 매우 다른 수준의 명시성으로 구현합니다. 조사한 도구들 가운데 Batty는 가장 분명한 독립형 머지 트레인 기본 요소입니다. 세션별 영구 worktree를 실행하고, Markdown 칸반 파일에서 작업 목록을 가져오며, 각 브랜치를 병합 전 테스트 뒤에 세우고, 결정적으로 "serializes concurrent merges with a file lock" 해서 두 에이전트가 동시에 trunk에 착륙하지 못하게 합니다. 그 락이 곧 트레인입니다. 상류 작업은 모두 병렬이지만, 통합 지점은 단일 파일로 강제됩니다. 앞 절에서 minimum-1 직렬 모드의 최소 메커니즘이라고 설명한 바로 그 방식입니다.
Augment Code의 Intent 오케스트레이션(2026년 4월 7일 공개, 2026년 6월 18일 업데이트)은 같은 규율을 3계층 구조 안에 넣습니다 . Coordinator가 의존성 순서에 따라 작업을 분해하고, specialist agent들은 격리된 worktree에서 실행되며, Verifier가 병합 전에 결과를 명세와 대조합니다. 따라서 직렬화는 원시 파일 락이 아니라 검증 게이트에서 일어납니다. 용량 계획에는 구체적인 숫자가 중요합니다. 이 문서는 최대 5개의 동시 Claude 세션, 초 단위 worktree 생성, 3100–9999 범위의 결정적 포트 할당, 400,000개 이상 파일을 가진 저장소를 언급합니다 . 의존성 순서에 따른 분해와 명세 검증은 이름만 다를 뿐 승인 순서 지정입니다. 트레인은 도착순이 아니라 준비 상태에 따라 순서를 정합니다.
Composio의 Agent Orchestrator는 제품화된 쪽 끝에 있으며 가장 널리 채택된 도구입니다. GitHub 스타는 약 7.6k, 최신 릴리스는 2026년 5월 23일자의 v0.9.2, 코드의 약 90%는 TypeScript입니다 . 이 도구는 각자의 worktree에서 병렬 세션을 띄우고, 세션마다 브랜치와 pull request를 할당하며, CI 재시도, 병합 충돌 해결, 코드 리뷰를 처리합니다. 짚고 넘어갈 빈틈은 README가 내부 머지 트레인 순서를 문서화하지 않는다는 점입니다. 격리와 브랜치별 PR은 기본으로 제공되지만, 실제 착륙 순서, 즉 실패 시 차단할지 건너뛸지, 병렬 파이프라인인지 엄격한 직렬인지가 명시되어 있지 않습니다. 따라서 밀도가 높은 저장소를 가진 팀은 경합 상황에서 신뢰하기 전에 승인 동작을 검증해야 합니다.
Superset(2026년 3월 1일 출시, Apache-2.0)은 병렬성을 더 밀어붙여 로컬 동시 세션 10개 이상을 내세웁니다 . 이는 코드베이스 자체가 병목이 되기 시작하는 3–5개의 적정 구간을 넘어섭니다. 2026년 6월 기준 병합 직렬화 세부 사항은 공개 문서에 없습니다. 여기서 반복되는 패턴은 분명합니다. 격리는 해결되어 홍보되지만, 통합 순서 지정은 조용한 파일 락(Batty), 검증 게이트(Augment), 또는 문서화되지 않은 상태(Composio, Superset)로 남아 있습니다.
빌더에게 주는 핵심은 이렇습니다. 이런 도구를 평가할 때 worktree 이야기는 안전성에 대해 거의 아무것도 말해주지 않습니다. 락이 어디에 있는지 물어보세요. 파일 락, 병합 전 검증, 명시적 큐처럼 이름 붙은 직렬화 기본 요소가 실제로 trunk를 깨끗하게 유지하는 부분이며, 벤더들이 공개하는 데 가장 일관성이 없는 부분도 바로 그것입니다.
코드베이스 나누기: 무엇을 분리할지 정하는 독립성 검사
두 번째 worktree를 띄우기 전에 독립성 검사를 하세요. 두 작업은 한쪽이 쓰는 파일을 다른 쪽이 읽지 않을 때만 병렬화해도 안전합니다. 에이전트 A가 auth handler를 수정하는 동안 에이전트 B가 auth가 import하는 util을 리팩터링한다면, 둘은 독립적이지 않습니다. B의 변경이 A의 브랜치를 조용히 깨뜨릴 수 있고, 그 사실은 병합 시점에야 알게 됩니다. 이 검사는 사후가 아니라 분해 단계에서 적용해야 합니다. 공유 설정 파일, lockfile, 스키마 마이그레이션은 거의 항상 이 검사를 통과하지 못합니다. 거의 모든 작업이 읽거나 쓰기 때문에, 두 에이전트가 이를 건드리는 순간 기능 작업이 겉보기에는 아무 관련 없어 보여도 서로 결합됩니다.
빠른 답변: 두 작업 사이에 쓰기/읽기 파일 의존성이 없을 때만, 즉 독립성 검사를 통과할 때만 작업을 나누세요. 동시성은 worktree 3–5개로 제한하세요. 5개를 넘으면 공유 파일과 횡단 관심사가 병합 큐를 깊게 만들어 벽시계 시간이 더 이상 줄지 않습니다. AgenticFlict는 142K개 이상의 AI 에이전트 PR에서 27.67%의 병합 충돌률을 측정했으므로, 승인 순서 지정이 중요합니다.
그런 결합 때문에 실무적인 상한은 낮게 잡힙니다. 조사한 도구 전반의 가이드는 동시 worktree 3–5개가 적정 구간이라는 데 모입니다. 5개를 넘으면 공유 파일과 횡단 관심사가 충분히 깊은 병합 큐를 만들어 벽시계 시간이 더 이상 개선되지 않고, 코드베이스 자체가 병목이 됩니다 . 경험적 최저선도 이런 주의를 뒷받침합니다. AgenticFlict가 59K개 이상 저장소의 142K개 이상 AI 에이전트 PR을 분석한 결과, 336K개 이상 충돌 영역에서 27.67%의 병합 충돌률이 확인되었습니다 . 에이전트를 더 늘린다고 이 문제가 사라지지는 않습니다. 그 문제 앞에 줄을 설 뿐입니다.
격리만으로 부족한 곳에서는 containment가 도움이 됩니다. 2025년 10월 5일 글에서 Simon Willison은 Claude Code, Codex CLI, Codex Cloud, Copilot, Jules를 병렬로 자주 실행한다고 밝혔고, 구체적인 가드레일 하나를 권했습니다.
"I'll often run them in a Docker container — that way if they go rogue they can't do too much damage. It's about limiting the blast radius," — Simon Willison, 병렬 코딩 에이전트에 대해 (source: simonwillison.net, 2025-10).
아직 풀리지 않은 질문이 하나 있고, 이 질문이 안 좋은 날 트레인이 어떻게 움직일지를 결정합니다. 실패한 브랜치는 트레인을 막아야 할까요, 아니면 건너뛰어야 할까요? 차단은 갈라진 통합을 막습니다. 깨진 구성원이 고쳐질 때까지 아무것도 착륙하지 않습니다. 하지만 그 뒤의 모든 후속 작업이 멈춥니다. 건너뛰기는 처리량을 유지하지만, 후속 작업이 빠진 변경을 제외한 base에 대해 검증된 상태로 남습니다. 이는 나중에 충돌로 다시 떠오를 수 있는 애매한 상태입니다. 도구들은 이 지점에서 갈라져 있으며, 아직 표준은 나오지 않았습니다.
구체적인 결론은 이렇습니다. 독립성 검사로 작업을 분해하고, 에이전트는 3–5개로 제한하며, 각 세션을 sandbox에 넣어 blast radius를 줄이고, 실패한 구성원을 어떻게 처리할지 트레인이 멈춘 뒤가 아니라 시작 전에 정하세요. worktree는 격리를 사게 해줍니다. 깨끗한 trunk를 사게 해주는 것은 이런 규율입니다.
마지막 업데이트: 2026-06-23.
자주 묻는 질문
git worktree란 무엇이며, 왜 코딩 세션마다 하나씩 쓰나요?
git worktree는 하나의 저장소에 연결된 추가 작업 디렉터리입니다. 하나의 객체 데이터베이스를 공유하면서도 각자 별도의 HEAD와 index를 유지합니다 . 코딩 세션마다 별도의 worktree를 쓰면 각 세션이 서로 다른 브랜치를 체크아웃하고, 파일을 수정하고, 독립적으로 커밋할 수 있습니다. 다른 세션의 추적 파일을 덮어쓰거나 하나의 index lock을 두고 다툴 필요가 없습니다. Anthropic의 Claude Code 문서도 이를 직접 권장하며, `claude --worktree feature-auth`로 자체 브랜치의 별도 체크아웃을 띄우는 방식을 제시합니다 .
serialized merge train이란 무엇이며, parallel merge queue와 어떻게 다른가요?
serialized merge train은 브랜치를 엄격하게 하나씩만 통합합니다. 브랜치 N은 브랜치 N-1이 병합된 뒤에야 검증 파이프라인을 시작하므로, 각 브랜치는 바로 앞 브랜치가 이미 main에 들어간 상태를 기준으로 검증됩니다. 반면 parallel merge queue는 여러 브랜치를 동시에 검증합니다. GitLab의 기본 최대값은 train당 병렬 파이프라인 20개이며, 완전한 순차 처리를 원하면 최소값 1로 설정합니다 . GitHub의 merge queue도 pull request에 같은 방식의 제어를 제공하며, 빌드 동시성 한도를 1부터 100까지 설정할 수 있습니다 . 간단히 말해 “serialized”는 그 동시성을 1로 설정한다는 뜻입니다.
STORM의 write-time mediation은 일반적인 worktree 설정과 무엇이 다른가요?
worktree는 충돌 감지를 병합 시점까지 미룹니다. 그래서 두 에이전트가 같은 코드를 건드렸다는 사실은 각자의 브랜치를 통합할 때에야 드러납니다. 반면 STORM(2026년 5월 19일 제출)은 공유 작업공간 상호작용을 중재하고, 세션이 충돌하는 변경을 쓰는 바로 그 순간인 write time에 충돌을 잡아냅니다 . STORM은 git-worktree 기반 다중 에이전트 베이스라인 대비 Commit0-Lite에서 +18.7%포인트, PaperBench에서 +1.4를 보고했습니다 . 단점도 있습니다. worktree가 기본으로 제공하는 느슨한 결합 대신, 두 세션이 함께 통신할 수 있는 공유 상태 중재자가 필요합니다.
병렬 worktree는 몇 개까지 돌리는 것이 효율적인가요?
연구와 실무 경험은 동시 에이전트 3~5개로 수렴합니다. 5개를 넘어서면 병목은 에이전트 자체보다 공유 config, schema migration, merge queue 깊이가 됩니다. 실용적인 접근은 2개에서 시작해 merge queue가 얼마나 깊어지는지 측정하고, queue가 얕게 유지될 때에만 세션을 더 추가하는 것입니다. Simon Willison은 2025년 10월 5일 글에서 Claude Code, Codex CLI, Codex Cloud, Copilot, Jules를 일상적으로 병렬 실행한다고 설명하면서도, 동시성이 높아질수록 Docker를 사용해 “limit the blast radius” 하는 식의 sandboxing이 중요하다고 강조했습니다 .
merge train 중간의 브랜치가 실패하면 어떻게 되나요?
아직 표준 답은 없고, 도구마다 방식이 갈립니다. 실패한 항목에서 막아두면 통합 일관성은 유지되지만, 그 뒤에 있는 모든 브랜치의 처리량이 멈춥니다. 실패를 건너뛰면 처리량은 유지되지만, 뒤따르는 브랜치들이 나중에 실제로 들어갈 변경과 충돌하는 상태에 놓일 수 있습니다. 구체적으로 Batty는 파일 lock으로 동시 merge를 직렬화하고 실패 시 차단합니다 . 반면 GitLab의 merge train은 실패한 merge request를 제거하고, 그 뒤의 항목들을 업데이트된 target 기준으로 다시 queue에 넣습니다 . train을 시작하기 전에 정책을 정해야지, 멈춘 뒤에 정해서는 안 됩니다.









