When a medical AI scores 94% on treatment precision against 67% for board-certified doctors, the instinct is to ask what the test actually measured. Google's latest AMIE study, published in Nature in June 2026, is that test — and the design matters more than the headline.
What the Nature Trial Examined
The Nature trial examined whether a conversational medical AI could manage patients across multiple appointments — not just diagnose them once. The study is Google Research and Google DeepMind's second AMIE (Articulate Medical Intelligence Explorer) paper, first posted as arXiv:2503.06074 in March 2025 and published in Nature, with the Financial Times reporting the journal publication on June 17, 2026. It extends AMIE's mandate from one-off diagnostic dialogue to longitudinal disease management: tracking how symptoms, test results, and treatment plans evolve as a patient returns visit after visit (Google Research).
The evaluation was a randomized, blinded virtual OSCE built on 100 multi-visit case scenarios, each spanning three text-based appointments (Google blog). Visits were spaced at least 24 hours apart — roughly two days operationally — while the narratives represented clinical timelines of weeks to months, so symptoms, treatment responses, and lab results could change between encounters.
Scenarios were split evenly across five specialty groups — cardiology, pulmonology, OB/GYN plus urology, gastroenterology, and neurology — at 20 scenarios each, with cases prepared by providers in Canada and India. AMIE went head-to-head against 21 board-certified primary care physicians (median 9 years post-residency), with 21 trained patient actors playing the cases. The judging was blinded: 10 specialist evaluators (median 5 years post-residency) rated management plans across 15 quality axes — including appropriateness, completeness, guideline adherence, and patient-centeredness — without knowing whether a plan came from AMIE or a human.
Tracking Patients Through Multiple Appointments
The earlier AMIE work, published in 2025, stopped at a single diagnostic conversation — one dialogue, one differential, no continuity . This study changes the unit of evaluation. Each of the 100 cases unfolds across three text-based appointments, so the system has to do what single-turn LLMs handle poorly: track symptom progression, fold in returning test results, adjust treatment as the picture shifts, and schedule follow-up .
That is deliberately the chronic-care problem set — comorbidity tracking, medication adjustment against a changing presentation, and sustained reasoning that has to stay coherent from visit one to visit three rather than restarting cold each turn .
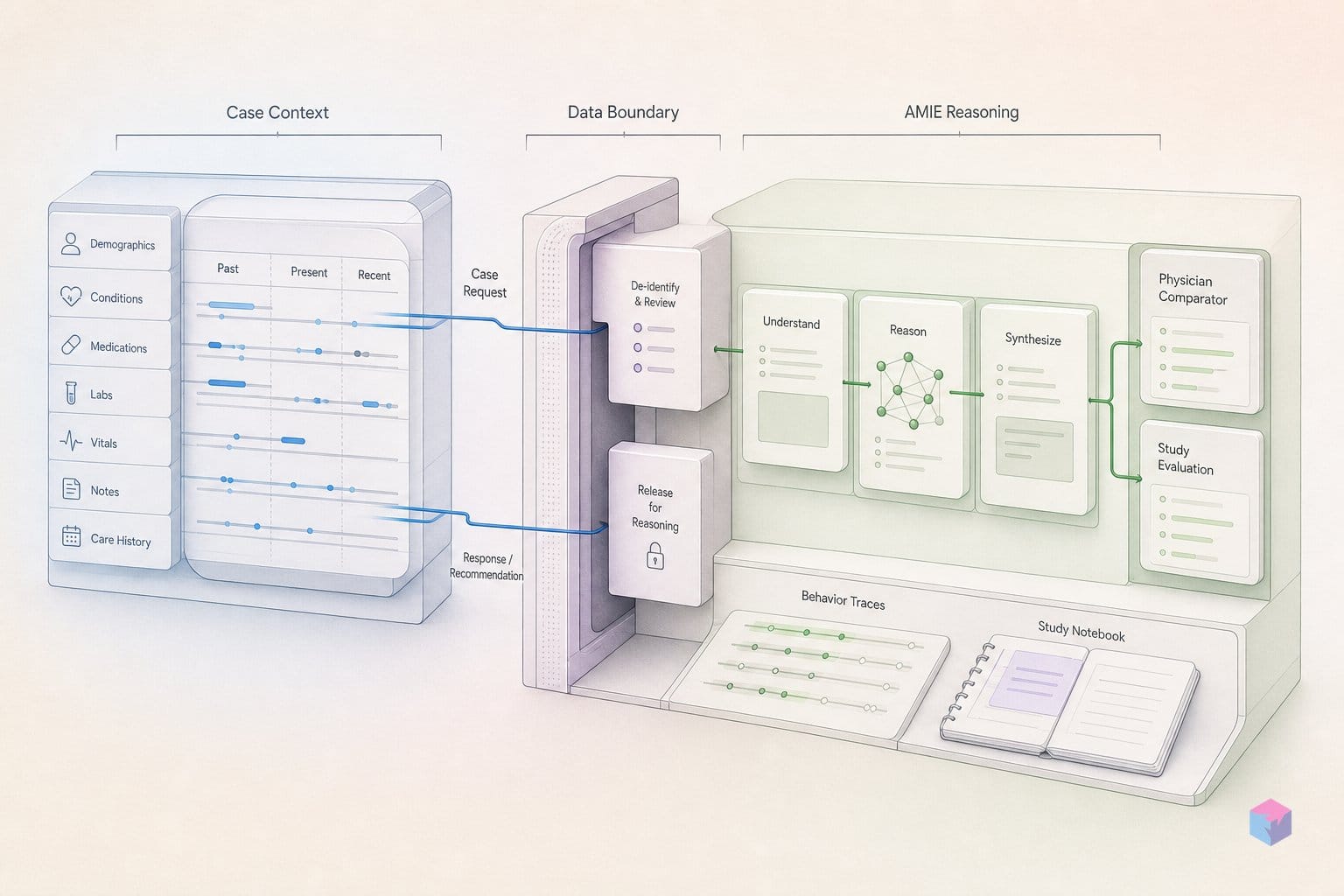
To keep the comparison fair, AMIE and all 21 board-certified physicians drew on the same evidence base: a corpus of 627 documents — 527 UK NICE Guidance plus 100 BMJ Best Practice items, roughly 10 million tokens in total — of which 50 NICE and 50 BMJ documents were directly relevant to the scenarios . Neither side had a private reference advantage; the question was who used the same guidelines better across visits.
Worth separating from the simulated trial is a parallel real-world feasibility preprint, run on 100 urgent-care patients with human safety supervision. There, AMIE's differential included the final diagnosis in 90% of cases, with 75% top-3 accuracy — but PCPs still outperformed it on practicality and cost-effectiveness . The signal cuts both ways, which is also how the authors frame it.
"Not ready for clinical use" — the position Google Research states plainly, describing the work as a milestone that still requires prospective feasibility studies under ethical and safety oversight (source: Google Research).
Conversational Module Plus Mx Reasoner: Under the Hood
AMIE's architecture splits the work across two agents built on Gemini models: a fast Dialogue Agent that talks to the patient, and a slower Management Reasoning Agent (the Mx Agent) that retrieves and reasons over clinical guidelines. The Dialogue Agent runs on Gemini 1.5 Flash — replacing the PaLM-2 base of earlier AMIE work — and handles synchronous text chat, gathering information and maintaining rapport across multiple visits . It is optimized for latency and conversational flow, not deep deliberation.
The Mx Agent is the deliberate half. It targets a response time of no more than one minute and is tuned for long-context guideline reasoning . Its pipeline is a four-step retrieve-and-refine loop:
- Coarse retrieval over the titles and generated abstracts of the full corpus using Gecko 1B embeddings .
- Context allocation of roughly 256,000 tokens for external knowledge — averaging about six guideline documents per query .
- Parallel drafting of four independent management plans.
- Merge and refine into a single cited final plan covering investigations, treatments, and follow-up .
The corpus both AMIE and physicians drew on contained 627 documents — 527 UK NICE Guidance and 100 BMJ Best Practice documents, totalling about 10 million tokens . The coarse-retrieval-then-long-context step is what lets the Mx Agent ground recommendations in named guidelines rather than parametric memory.
| Component | Base model | Role | Optimized for |
|---|---|---|---|
| Dialogue Agent | Gemini 1.5 Flash | Synchronous chat, info-gathering, rapport across visits | Speed, conversation |
| Mx (Management Reasoning) Agent | Gemini long-context | Retrieve guidelines, draft 4 plans, merge into one cited plan | ≤1 min, guideline reasoning |
The decoupling is the portable lesson here. A latency-sensitive conversational front end is paired with a slower, retrieval-heavy reasoning back end that exploits Gemini's long context window . Neither agent does both jobs, which is precisely why the system can hold a natural conversation while still citing six guideline documents per turn. The pattern is domain-agnostic: anywhere you have a structured knowledge corpus and need both responsiveness and defensible, citation-backed output, splitting the chat loop from the reasoning loop is a credible blueprint — clinical guidelines here, but equally legal statutes, compliance manuals, or internal engineering docs.
Where Medical AI Edged Out Physicians: Treatment and Investigation
Across the blinded OSCE, AMIE was rated non-inferior to primary care physicians on all 15 management-plan quality axes and across all three visits, and there was no single axis where physicians significantly outperformed it . The system's clearest edge was specificity. On treatment precision — how narrowly and correctly a plan targets the actual problem — AMIE scored 94%, 90%, and 91% across visits 1–3, versus 67%, 70%, and 70% for PCPs . That is roughly a 27-percentage-point gap at the first visit that does not close as cases evolve.
Investigation precision tells a more interesting longitudinal story. The two groups tied at 91% on the first visit, then AMIE pulled ahead as cases accumulated history: 99% versus 84% at visit 2, and 100% versus 88% at visit 3 . The gap widening over follow-ups is the signal worth noting: the advantage of long-context retrieval shows up most where prior results, evolving symptoms, and earlier decisions all have to be held in working memory at once.
| Metric | Group | Visit 1 | Visit 2 | Visit 3 |
|---|---|---|---|---|
| Treatment precision | AMIE | 94% | 90% | 91% |
| Treatment precision | PCPs | 67% | 70% | 70% |
| Investigation precision | AMIE | 91% | 99% | 100% |
| Investigation precision | PCPs | 91% | 84% | 88% |
| Treatment guideline alignment | AMIE | 89% | 91% | 93% |
| Treatment guideline alignment | PCPs | 75% | 76% | 81% |
Some of this is mechanical: AMIE explicitly cited treatment guidelines at 98–100% of the time versus 86–88% for PCPs, and its treatment guideline alignment ran 89%, 91%, and 93% across the three visits against 75%, 76%, and 81% for physicians . A system whose reasoning agent retrieves and merges roughly six guideline documents per plan will cite sources more consistently than a clinician working from memory under time pressure — that is the architecture doing exactly what it was built to do, not an emergent surprise.
The picture is more mixed on the study's novel MXEKF management-reasoning rubric, where evaluators expressed a direct preference between plans. Roughly half of comparisons were ties or marked not applicable; among the rest, AMIE's median win rate was 42% versus 8% for PCPs across 51 rater-axis-visit combinations . A roughly 5-to-1 preference ratio is substantial, but the large share of ties is a reminder that on many axes the two were judged equivalent rather than AMIE dominating outright.
Read these numbers for what they measure. As Google's team frames it:
"AMIE is not ready for clinical use," the authors state, calling the work "a milestone" that requires prospective feasibility studies with ethical and safety oversight (source: Google Research).
The scores reflect plan quality as graded by specialist raters in a simulated setting — higher precision and tighter guideline grounding, not validated patient outcomes.
A New Drug Competency Instrument: Pharmacist-Validated, 600 Items
Alongside the management evaluation, the team built RxQA, a 600-question medication-reasoning benchmark designed to probe drug knowledge directly rather than infer it from dialogue . Its questions are derived from OpenFDA/US FDA data and the British National Formulary, then validated by board-certified pharmacists, and span five competency areas: indications, contraindications, dosages, side effects, and drug interactions . For builders, this is the most portable artifact in the paper — a structured, source-grounded test you can run before shipping any medication-adjacent LLM feature.
The set splits into 282 lower-difficulty and 318 higher-difficulty items, and it was hard for both groups . On the lower-difficulty open-book setting, AMIE scored 73.8% versus 67.4% for primary care physicians — a gap that did not reach statistical significance (p=0.071) .
The separation widened on the harder questions. AMIE beat PCPs in the closed-book setting (50.6% vs 41.5%, p=0.013) and in the open-book setting (57.9% vs 47.8%, p<0.001) . That open-book result is the most statistically robust gap in the entire publication — notable because open-book conditions give both parties the reference material, isolating reasoning over the formulary rather than recall alone.
As the authors frame it, "RxQA is released as a standalone contribution," intended for reuse by teams evaluating medication reasoning independent of the AMIE system itself (source: Google Research). For an engineering team, that reframes the contribution: the dialogue agent and Mx reasoner stay locked behind a research wall with no API, but the benchmark is a concrete, pharmacist-validated yardstick you can wire into an evaluation harness today. Two caveats stay attached — the questions were constructed with definitive answers, and accuracy on a curated set is not evidence of safe behavior on live, multimorbid patients.
Scripted Scenarios, Trained Actors: What the Trial Excluded

The headline numbers describe a tightly controlled simulation, not a clinic. Every one of the 100 multi-visit cases was scripted with a definitive answer and acted out in synchronous text chat by 21 trained patient actors. The authors are explicit that these cases were deliberately constructed to be non-representative of routine primary care, where presentations are ambiguous and a single correct plan rarely exists (source: Google Research, 2026-06).
Just as important is what the harness left out. The consultations were text-only from start to finish — no electronic health records, no order-entry constraints, no live e-prescribing, and no pharmacist in the medication workflow. That is a long way from real telehealth, which routinely carries video, images, and live lab feeds. The setup also models none of the friction that shapes actual practice:
- No multimorbidity outside the five chosen specialties — cardiology, pulmonology, OB/GYN and urology, gastroenterology, and neurology, at 20 scenarios each (source: Google, 2026-06).
- Compressed timelines — visits spaced roughly two days apart with a 24-hour minimum, standing in for narrative weeks or months .
- No local formulary, insurance, or patient-adherence constraints modeled at all.
There is also a reference-frame mismatch worth flagging. The guideline corpus was UK-centric — 527 NICE and 100 BMJ Best Practice documents — while the comparison physicians practiced in North America and India. That gap could cut either way: it may flatter a system that retrieves directly from the same NICE/BMJ texts, or penalize clinicians reasoning from different national standards.
The most consequential limit is the endpoint itself. The primary measure was specialist-judged plan quality, rated blind on appropriateness, completeness, guideline use, and patient-centeredness — not actual patient outcomes. A plan that reads well to a reviewer is not the same as a plan that helps a real patient over months. Google says plainly that AMIE is not ready for clinical use and calls for prospective feasibility studies under ethical and safety oversight (source: Google, 2026-06). For any deployment inference, that outcome gap is the one to keep in front.
What Medical AI Teams Can Extract From This
The transferable lesson from this study is architectural, not the model itself: decoupling a fast conversational front-end from a slower, retrieval-heavy reasoning agent outperformed single-pass generation on longitudinal clinical tasks . AMIE ships with no API, no pricing, and no announced timeline, so what you can actually reuse is the pattern — the Dialogue Agent / Mx Agent split — applied to your own domain and corpus.
Three concrete takeaways for medical-AI and adjacent teams:
- The split is the asset, not the weights. Any domain with a large, structured knowledge corpus — legal precedent, compliance frameworks, technical documentation — can attempt the same separation: a synchronous chat agent for information-gathering, plus a deep-retrieval agent that reads many long documents before committing to an answer.
- Long-context grounding with per-plan citations measurably improves precision. AMIE allocated roughly 256,000 context tokens for retrieved guidelines and emitted explicit references, and its treatment precision reached 94% on first visit versus 67% for primary care physicians . That result is replicable on any long-context LLM given a curated, citation-traceable corpus — the citations are not decoration, they are part of why precision rose over single-pass output.
- RxQA is a usable eval today. The 600-question, pharmacist-validated medication-reasoning benchmark — built from OpenFDA/FDA and British National Formulary data — is a standalone contribution . Adopt it to assess medication reasoning before clinical validation, not as a substitute for it; on its harder split AMIE scored 57.9% open-book versus 47.8% for PCPs , so even the leading system leaves substantial headroom.
Frame this correctly. It is a controlled research milestone showing what is achievable under favorable simulation conditions — text-only, scripted cases, specialist-judged plan quality — not evidence that autonomous chronic disease management is solved or deployable. Google's stated next step is prospective feasibility studies under ethical and safety oversight . The concrete action for builders: borrow the two-agent retrieval pattern and the RxQA benchmark now, and treat any clinical-deployment claim as unproven until real-patient outcome data exists.
Frequently asked questions
Is AMIE available as an API or developer tool right now?
No. AMIE is a pure research system with no public API, no pricing, and no announced deployment timeline. Google states plainly that it is not ready for clinical use and calls for prospective feasibility studies with ethical and safety oversight before any real-world rollout . The current audience is researchers, health-system AI teams, clinicians, and regulators — not application developers shipping a product. Treat any consumer- or clinician-facing AMIE integration as nonexistent today.
How does the two-component design differ from prompting a single LLM for disease management?
The split decouples latency from depth. The Dialogue Agent, built on Gemini 1.5 Flash, handles low-latency conversation and rapport across visits, while the Management Reasoning Agent (Mx Agent) does the slow, citation-heavy work — coarse retrieval over guideline titles, allocating roughly 256,000 context tokens, generating four draft management plans, then merging them into one cited plan targeting under a minute . A single LLM must trade off response speed against reasoning depth on every turn; separating the roles lets each component optimize independently.
What is RxQA, and can it be used independently of AMIE?
RxQA is a 600-question medication-reasoning benchmark derived from OpenFDA/US FDA data and the British National Formulary, validated by board-certified pharmacists and covering indications, contraindications, dosages, side effects, and interactions . It splits into 282 lower-difficulty and 318 higher-difficulty items . It was released as a standalone contribution, so any team evaluating medication reasoning in LLMs can adopt it without touching AMIE — it is the most immediately usable artifact from the publication.
Why does it matter that patients were trained actors playing scripted cases?
Because scripted cases with definitive answers are systematically easier than real clinical ambiguity. The trial used simulated, text-only consultations with trained patient actors — not real patients — and deliberately constructed cases that the authors describe as non-representative of routine primary care . There were no electronic health records, no multimodal inputs, and none of the emotional complexity of genuine illness. Crucially, the study measured specialist-judged plan quality, not actual patient outcomes — which is exactly why Google frames it as a milestone, not a clinical validation.
Can the fast-conversational / slow-reasoning pairing be applied outside medicine?
Yes — the pattern is domain-agnostic. A fast conversational front end paired with a slow, long-context retrieval reasoner is relevant anywhere large structured knowledge corpora exist: legal research, compliance, financial advice, or technical documentation. In AMIE's case the reasoner drew on a corpus of 627 guideline documents totaling about 10 million tokens . The real constraint is not the architecture but having a validated knowledge corpus and a defensible rubric for plan quality — without those, decoupling the agents buys you little.