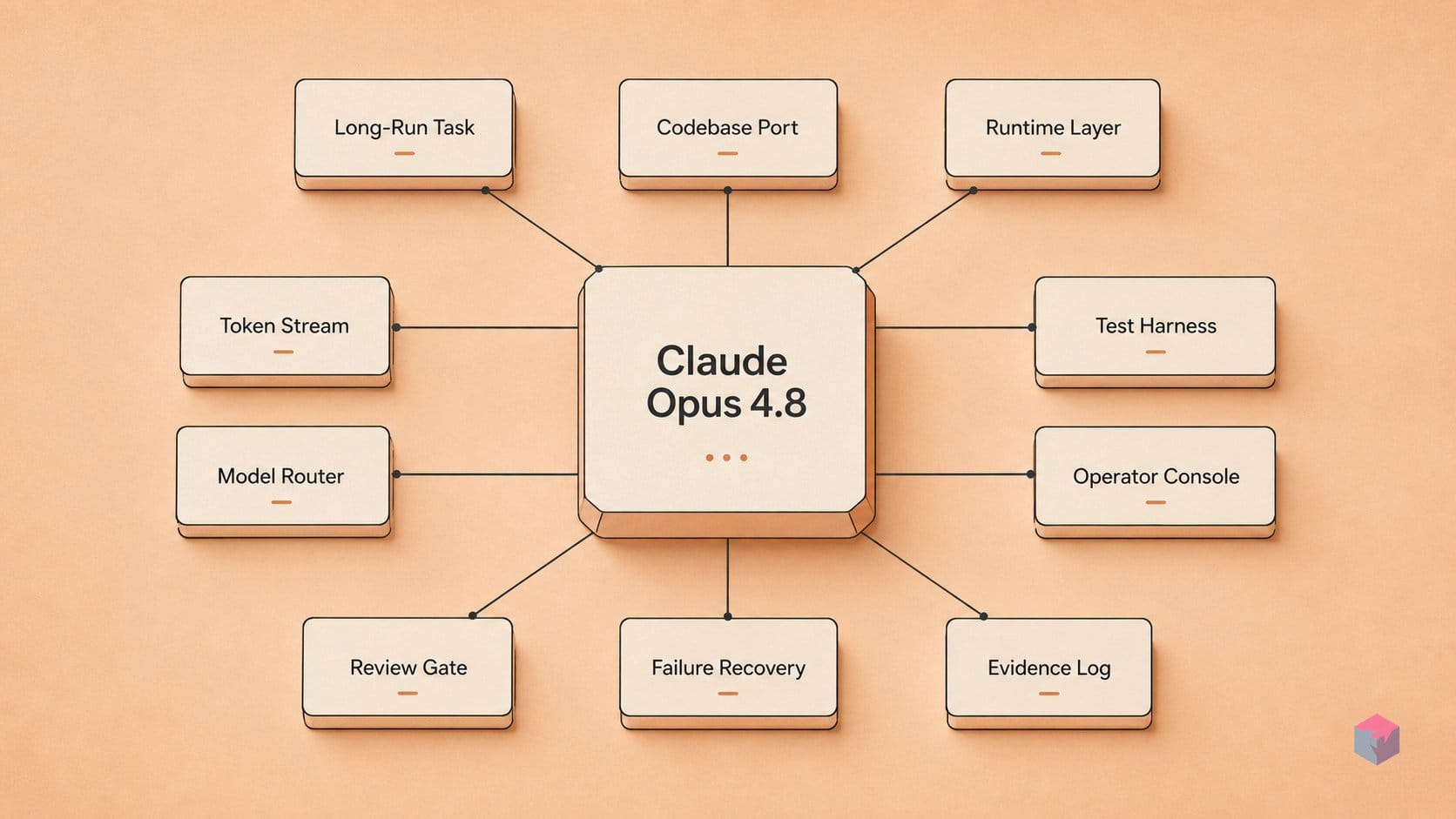
What Opus 4.8 Is (and Isn't) Designed to Solve
Claude Opus 4.8 is a reliability and orchestration upgrade to Opus 4.7, released on May 28, 2026 and exposed through the API model ID claude-opus-4-8 . It is not a new product tier or a raw-reasoning leap. Anthropic frames it as a "more effective collaborator," with the central technical theme being sustained, coherent execution across long-running agentic tasks rather than higher peak intelligence on a single prompt .
That framing matters because the dominant failure mode in multi-hour, unattended runs is not one bad final answer — it is confidently wrong intermediate steps that compound: silent drift, missed tool calls, and bad recovery after context compaction. Opus 4.8 targets that failure mode with three reliability levers rather than a benchmark headline:
- More frequent error self-flagging. Anthropic reports the model is roughly 4x less likely than Opus 4.7 to let flaws in its own generated code pass without comment — a vendor claim we examine later.
- Better dependency tracking. The model is tuned to break down ambiguous problems, track dependencies, route around blockers, and self-correct with fewer check-ins .
- Fewer unsolicited progress claims. It is more likely to surface uncertainty and less likely to assert progress it cannot support — the kind of false "done" that derails an autonomous loop .
One temporal caveat sets the stakes for any adoption decision. Opus 4.8 ranked #1 at launch, but it held that spot for under two weeks. As of June 26, 2026, Anthropic's own docs list Claude Fable 5 (launched June 9, 2026) as its most capable widely released model, with Mythos 5 in limited availability. So the question is not whether Opus 4.8 was briefly the best — it is whether its reliability gains are durable and independently verifiable enough to build unattended pipelines on. The rest of this piece tests exactly that.
budget_tokens Deprecated: What Opus 4.8 Sends Back Instead
The first thing your code will hit on Opus 4.8 is a rejected request. The model removes manually budgeted extended thinking: a call carrying thinking: {type: "enabled", budget_tokens: N} is refused at the API level, and you migrate to adaptive thinking instead . The replacement is a single line:
// Opus 4.7 and earlier — now rejected on claude-opus-4-8
thinking: { type: "enabled", budget_tokens: 32000 }
// Opus 4.8 — model decides how much to think
thinking: { type: "adaptive" }The reasoning here is that fixed token budgets are a blunt instrument: you either over-allocate on easy steps or starve hard ones. Adaptive thinking hands that decision to the model, which is consistent with the release's headline efficiency numbers — 15% fewer turns and 35% fewer output tokens per task than Opus 4.7. If your orchestration layer hard-codes budget_tokens, that is the one breaking change you must patch before any Opus 4.8 traffic flows.
Coarse control hasn't disappeared — it moved to a new effort parameter with five levels: low, medium, high (the default), xhigh, and max . Default effort is high across both the Claude API and Claude Code. Anthropic recommends xhigh specifically for coding and long-running agentic work, and reserves max for workloads where your evals show the extra cost actually pays off . Treat max as opt-in, not aspirational — without a measured win it just burns tokens.
Two output-and-routing limits round out what changes for pipeline authors. The Batch API now accepts up to 300K output tokens via the output-300k-2026-03-24 beta header, while the synchronous Messages API still caps at 128K . If you generate very long artifacts — full file rewrites, large refactors — that ceiling decides whether a job is a single synchronous call or a batch submission. Separately, pinning traffic to US infrastructure with inference_geo: "us" adds a 1.1x price multiplier , which matters only if data-residency rules force the constraint.
Net effect: the migration itself is small — swap one thinking flag, optionally set an effort level — but the defaults now make more of the cost-versus-quality decision for you. That is the right shift for unattended agents, provided you've measured what each effort tier buys.
4x Fewer Unremarked Flaws: What the Claim Means for Your Pipeline
The headline reliability claim is that Opus 4.8 is roughly 4x less likely than Opus 4.7 to let flaws in its own generated code pass without comment . That is a vendor-reported figure, repeated identically across Anthropic's announcement and trade briefs, and it has not been independently reproduced. Read it as a directional signal about self-checking behavior, not as a production SLA — but it targets a specific, expensive failure pattern, so it is worth understanding precisely what it does and does not promise.
The pattern it addresses is silent drift. In multi-hour unattended runs, the dominant failure mode is not one catastrophic final answer — it is a chain of confidently wrong intermediate steps: a missed tool call, a bad compaction recovery, an unverified assumption that propagates downstream and compounds before anything visibly breaks . A model that flags its own questionable output mid-run gives your orchestration layer a chance to catch the error while it is still cheap to fix, rather than after a hundred subsequent steps have built on it.
Two related behavioral changes reinforce the same goal. Anthropic says Opus 4.8 is more likely to surface uncertainty and less likely to make unsupported progress claims, and early testers reported the same . Both matter most in very long contexts, where unsupported "done" assertions and false confidence are exactly what poison compaction: if the model summarizes a half-finished step as complete, the compacted state carries that error forward with no audit trail. Surfacing doubt keeps the running context honest.
There is partial external corroboration for the broader consistency story. WorkBench Revisited, submitted June 10, 2026, ranked Opus 4.8 the best agent tested at 89% task completion with just 2.5% unintended harmful actions, against GPT-4's 43% completion and 26% harmful actions from March 2024 . That is a strong outside data point for workplace-agent reliability. But it measures task-level outcomes, not the specific "unremarked flaw" mechanism, and adjacent benchmarks bound the ceiling: WildClawBench put Opus 4.7 at 62.2% on 60 real CLI-agent tasks, and RoadmapBench had it resolving only 39.1% of 115 long-horizon upgrade tasks . Neither scored 4.8 directly, but they show how hard the category remains.
"A modest but tangible improvement," — The Decoder, characterizing the Opus 4.8 release overall (source: The Decoder).
The practical caveat: Anthropic has not published the eval harness or test distribution behind the 4x number. You do not know the language mix, task length, or how "flaw" was scored, so you cannot assume the ratio transfers to your codebase. Treat it as a reason to expect fewer silently-passed errors — not a reason to drop the human review, logging, and rollback paths that any unattended pipeline still needs.
Fan-Out and Recovery: How Dynamic Workflows Actually Operate
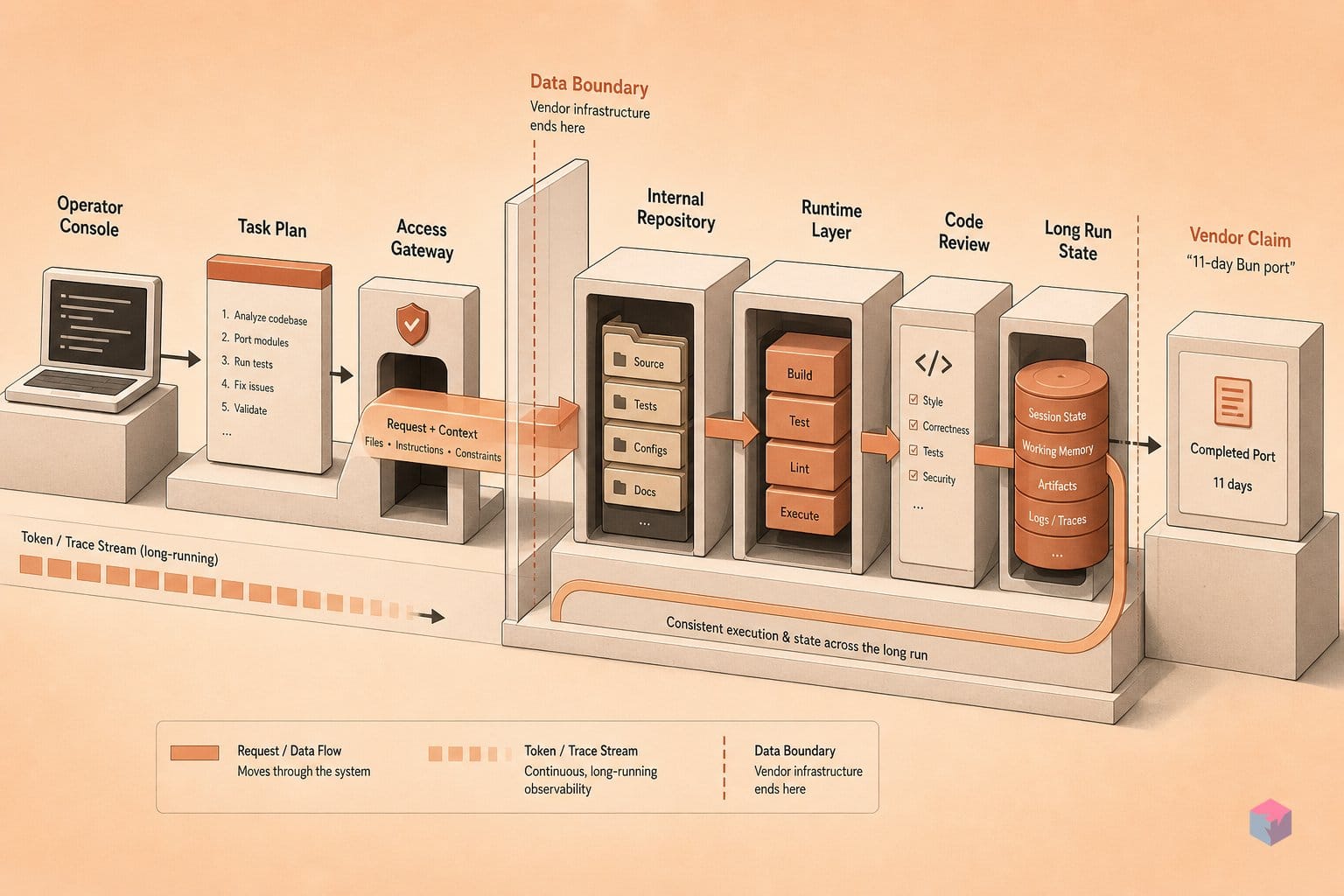
Dynamic Workflows is the orchestration layer Anthropic shipped alongside Opus 4.8: instead of one agent stepping through a task linearly, Claude plans a task graph, fans out to tens or even hundreds of parallel subagents, independently verifies each subtask's output, and merges the findings — all inside a single Claude Code session . The point is to convert a long serial run, where drift compounds turn after turn, into many short bounded runs whose results get checked before they are stitched together.
It launched with Opus 4.8 on May 28, 2026 and was later marked generally available across Claude Code CLI, Desktop, the VS Code extension, the Pro, Max, Team and Enterprise plans, the API, Amazon Bedrock, and Google Cloud . That spread matters because the orchestration is not gated behind a single client — the same fan-out behavior can fire from a terminal session, an IDE extension, or a cloud-hosted API call.
The durability story is the part worth scrutinizing. Workflows can persist for hours or days, checkpoint their progress, and resume after an interruption . For a multi-day task graph, resumability is the difference between a recoverable hiccup and re-running everything from scratch. But the same fan-out that buys you parallel verification is also what makes the bill move. A run that spawns hundreds of subagents, each consuming context and producing output, amplifies token spend substantially relative to a single-agent pass over the same problem — and at Opus 4.8's standard rate of $5 per million input and $25 per million output tokens , an unbounded multi-day workflow is a real cost exposure, not a rounding error.
Anthropic built two brakes into the feature. Admins can disable Dynamic Workflows through org settings, and Claude Code prompts for confirmation the first time a workflow triggers . Neither is a spend cap on its own. Before enabling fan-out in any production environment, set hard budget limits, decide who can authorize a multi-day run, and confirm your logging captures the subagent tree so a failed merge is traceable.
- Plan and fan-out: Claude builds a task graph and dispatches parallel subagents within one session .
- Verify and merge: subtask outputs are independently checked before findings are combined .
- Checkpoint and resume: runs save progress and recover after interruption — at higher token cost .
From Artificial Analysis to WorkBench: Opus 4.8 in the Wild
Independent benchmarks back most of Anthropic's reliability framing, but the strongest numbers are intelligence and efficiency gains, not proof of multi-hour autonomy. Artificial Analysis ranked Opus 4.8 first on its Intelligence Index at 61.4 — up 4.1 points from Opus 4.7's 57.3 and 1.2 points ahead of GPT-5.5 (xhigh) . That is a measurable, externally reproduced lead, not a vendor slide.
The agentic gap is wider than the general one. On GDPval-AA, Artificial Analysis recorded Opus 4.8 at 1,890 Elo versus 1,753 for Opus 4.7 — a 137-point jump and 121 points ahead of GPT-5.5, implying roughly a 67% head-to-head win rate . For long-running pipelines, the more useful figure is efficiency: it reaches those scores using about 15% fewer turns per task and 35% fewer output tokens than Opus 4.7 . Fewer turns and fewer tokens directly cut drift and cost over extended sessions — the failure mode that compounds in unattended agents.
| Signal | Result | Source |
|---|---|---|
| Intelligence Index | 61.4 (vs 57.3 for 4.7; +1.2 over GPT-5.5) | Artificial Analysis |
| GDPval-AA agentic Elo | 1,890 (vs 1,753 for 4.7; ~67% win rate) | Artificial Analysis |
| Efficiency vs 4.7 | 15% fewer turns, 35% fewer output tokens | Artificial Analysis |
| WorkBench Revisited completion | 89% tasks, 2.5% harmful actions | WorkBench Revisited |
| WildClawBench (Opus 4.7) | 62.2% on 60 real CLI tasks | WildClawBench |
| RoadmapBench (Opus 4.7) | 39.1% on 115 upgrade tasks | RoadmapBench |
The strongest real-world signal comes from outside Anthropic. WorkBench Revisited, submitted June 10, 2026, named Opus 4.8 the best agent it tested at 89% workplace task completion with only 2.5% unintended harmful actions — against GPT-4 in March 2024 at 43% completion and 26% harmful actions . That is independent corroboration of the consistency story Anthropic tells, on a workload that resembles enterprise automation more than a leaderboard.
The ceiling is the part to keep in view. Two adjacent benchmarks scored Opus 4.7, not 4.8, but bound how hard the difficult tier remains: WildClawBench found Opus 4.7 reached only 62.2% on 60 real CLI-agent tasks , and RoadmapBench found it resolved just 39.1% of 115 long-horizon version-upgrade tasks across 17 repos and 5 languages . Even allowing for a generational uplift, multi-repo upgrades and unconstrained CLI work are still where agents fail most often.
The honest read: Opus 4.8's intelligence and efficiency gains are independently confirmed, and WorkBench Revisited is a genuine external vote for workplace consistency. But the hard-task benchmarks where agents stall were measured on 4.7, and no independent suite has yet stress-tested 4.8 on multi-day autonomy. Treat the headline scores as real and the long-horizon durability as still thinly benchmarked — which is exactly why consequential unattended runs need task-specific evals.
Eleven Days, 750K Lines: What the Bun Rewrite Demonstrates
Anthropic's flagship demonstration for Opus 4.8 plus Dynamic Workflows is a port of the Bun runtime from Zig to Rust: roughly 750,000 lines of Rust, 99.8% of the existing test suite passing, and 11 days from first commit to merge . As an existence proof of multi-day unattended orchestration at production scope, it lands. As evidence that you can hand this workload to an agent and walk away, it does not — and the gap between those two readings is the whole story.
Start with the caveat Anthropic states plainly: the port is not in production as of late June 2026 . This is a vendor-curated engineering showcase, run under conditions Anthropic chose, on a codebase with an unusually strong existing test suite to grade against. It is not a battle-tested deployment, and nothing about it has been independently reproduced.
What it genuinely demonstrates is meaningful for anyone weighing long-horizon agents. The fan-out architecture held together across an 11-day run that could plan work, dispatch parallel subagents, verify, and merge without collapsing into drift . That is the failure mode multi-hour runs usually hit, and surviving it at 750K lines is a real signal that the orchestration layer can sustain coherence at scope. It also produced output that passes 99.8% of an existing suite — strong against the bar that was set.
What it does not prove is everything the test suite cannot see. Passing 99.8% of existing tests measures conformance to behavior the original authors already encoded; it says nothing about correctness in the 0.2% gap, in untested paths, or in subtle semantic regressions that compile and pass yet behave differently under load. A Zig-to-Rust rewrite of a JavaScript runtime is exactly where memory-model, concurrency, and edge-case differences hide below test coverage. The demo also tells you nothing about cost-effectiveness at this scale, and Dynamic Workflows are documented as consuming substantially more tokens precisely because they run for hours or days .
The framing to keep is the one The Decoder applied to the release as a whole: "a modest but tangible improvement" — best read as capability that is real but bounded, not a finished autonomy story (source: The Decoder, 2026-05). Treat the Bun port as proof that the mechanism works at scope, then assume that on your own codebase the test suite is the floor of correctness, not the ceiling. A green run on a port this large is where review starts.
What to Budget Before Shipping Opus 4.8

Standard pricing for Opus 4.8 is unchanged from Opus 4.7: $5 per million input tokens and $25 per million output tokens, with the 1M-token context window retained . The line item that actually changes your cost model is fast mode, which drops to $10/$50 per MTok from the $30/$150 charged on Opus 4.6 and 4.7 — roughly 3x cheaper — and runs at about 2.5x higher output tokens per second . That single change is what moves high-throughput, latency-sensitive workloads from marginal to viable; budget around it, not the headline rate.
Caching and batching are where multi-hour agents recover margin. Cache writes cost $6.25/MTok (5-minute) or $10/MTok (1-hour), cache hits are $0.50/MTok, and the Batch API applies a flat 50% discount, bringing standard rates to $2.50 input and $12.50 output . For long-running orchestration with a stable system prompt and reused context, the 1-hour cache plus batched non-interactive steps is usually the difference between a workable and a punishing bill.
| Mode / lever | Input ($/MTok) | Output ($/MTok) |
|---|---|---|
| Standard | $5.00 | $25.00 |
| Fast mode (4.8) | $10.00 | $50.00 |
| Fast mode (4.6 / 4.7) | $30.00 | $150.00 |
| Batch API (−50%) | $2.50 | $12.50 |
| Cache write (5-min / 1-hr) | $6.25 / $10.00 | — |
| Cache hit | $0.50 | — |
Two platform constraints belong in the design phase, not the post-mortem. The 1M-token context applies on the Claude API, Amazon Bedrock, and Google Cloud, but Microsoft Foundry caps at 200K — a hard ceiling for multi-document pipelines on Azure-hosted deployments. Synchronous Messages API output maxes at 128K tokens, with up to 300K available on the Batch API via the output-300k-2026-03-24 beta header, and US-only routing (inference_geo: "us") adds a 1.1x multiplier . Pick your platform for the context budget your workload actually needs.
Dynamic Workflows multiply token spend by design: fan-out across tens to hundreds of subagents, independent verification, and runs that span hours or days all consume substantially more tokens than a single-agent loop . Before enabling them for consequential unattended runs, put four things in place: spend caps, structured logging, rollback paths, and task-specific evals with human review checkpoints — the same controls Anthropic itself recommends . Admins can disable Workflows outright, and Claude Code confirms on first trigger, so the default posture is conservative; the budgeting work is making sure your guardrails are funded before you turn fan-out loose on a real codebase.
Which Pipelines Benefit Most from Opus 4.8 (and Which Won't)
Opus 4.8 pays off most in long-running, low-supervision work where confidently-wrong intermediate steps compound: multi-hour unattended coding agents, enterprise automation where a false-confidence failure cascades downstream, and teams already on Claude Code CLI who want parallel subagent orchestration. The supporting signal is concrete — a 137-point GDPval-AA jump to 1,890 Elo while using 15% fewer turns and 35% fewer output tokens than Opus 4.7 , plus 89% task completion at 2.5% unintended harmful actions on WorkBench Revisited . For those profiles, fewer turns directly mean less drift and lower cost over a session.
The fit is marginal elsewhere. Conversational apps and latency-sensitive pipelines may see the self-correction behavior add turns rather than remove them, and the adaptive-thinking overhead is wasted where a final answer matters more than a durable execution trace. If Opus 4.7 already passes your evals, there is no forcing reason to migrate — Anthropic itself frames 4.8 as an incremental upgrade, and The Decoder called it a "modest but tangible improvement" . Note too that as of June 26, 2026 Anthropic's own docs list newer models — Fable 5 and limited-availability Mythos 5 — so 4.8 is no longer the top of the lineup .
One change is worth re-evaluating independent of capability: fast mode dropped to $10/$50 per million input/output tokens, down from $30/$150 on Opus 4.6 and 4.7 — roughly 3x cheaper . If you ruled out fast Opus on cost for a high-throughput use case, re-run the model. Standard pricing ($5/$25 per MTok, 1M-token context) is unchanged , so the throughput tier is where the economics shifted.
The takeaway holds regardless of which model you land on: stronger self-checking is not a substitute for operational safeguards. The strongest consistency claims — Super-Agent end-to-end completion, 4x-fewer-unremarked-flaws, sustained coherence over many turns — are Anthropic-reported and not yet independently reproduced , and a June 16, 2026 red-team paper still broke the model on 11.5% of 7,826 harmful intents . So keep task-specific evals, human review checkpoints, structured logging, rollback paths, and spend caps in place. Pick Opus 4.8 when you are funding a long-horizon agent that will fail silently without them — and skip the migration when your current model already clears your bar.
Last updated: 2026-06-26.
Frequently asked questions
What is the difference between Claude Opus 4.8 and Opus 4.7?
Opus 4.8 is an incremental reliability and orchestration upgrade, not a new capability tier. Anthropic reports it is roughly 4x less likely than Opus 4.7 to let flaws in its own generated code pass without comment . It also swaps manually budgeted extended thinking for adaptive thinking and adds Dynamic Workflows for long-running tasks . Independent benchmark gains are real but modest: a 4.1-point lift on Artificial Analysis's Intelligence Index (to 61.4) and a 137-point jump in agentic GDPval-AA Elo (to 1,890) .
How do I migrate from budget_tokens to the new Opus 4.8 API?
Opus 4.8 rejects thinking: {type: "enabled", budget_tokens: N}, so replace it with thinking: {type: "adaptive"} and add an effort parameter — one of low, medium, high, xhigh, or max . The default is high across the Claude API and Claude Code. Anthropic recommends xhigh for coding agents and long-running agentic runs, and reserves max for workloads where your evals justify the added cost .
Which Opus 4.8 benchmark results are independently verified?
The Artificial Analysis figures are the strongest independently sourced numbers: Intelligence Index 61.4, GDPval-AA Elo 1,890, and roughly 15% fewer turns and 35% fewer output tokens per task than Opus 4.7 . WorkBench Revisited (submitted June 10, 2026) is also external, reporting 89% task completion with 2.5% unintended harmful actions . By contrast, the 4x self-correction claim, the 69.2% SWE-Bench Pro score, and the Super-Agent end-to-end results are Anthropic-reported and not yet reproduced by third parties .
What are Dynamic Workflows and when should I enable them?
Dynamic Workflows are Claude Code's built-in fan-out orchestration: Claude plans a task graph, spawns tens to hundreds of parallel subagents, independently verifies their outputs, and merges the findings . They are opt-in and admin-disableable, and can run for hours or days, save progress, and resume after interruption. They suit multi-day coding or research tasks but consume substantially more tokens, so set spend caps, structured logging, and rollback paths before enabling them in production .
Is Claude Opus 4.8 still the most capable Claude model as of mid-2026?
No. As of June 26, 2026, Anthropic's docs identify Claude Fable 5 — launched June 9, 2026 — as its most capable widely released model, with Mythos 5 in limited availability . Opus 4.8 ranked #1 at its May 28, 2026 launch but held the top position for under two weeks . It remains a sound choice for long-horizon agents, but it is no longer the frontier model in Anthropic's lineup.