Opus 4.8이 해결하려는 문제와 그렇지 않은 문제
Claude Opus 4.8은 Opus 4.7의 신뢰성과 오케스트레이션을 높인 업그레이드로, 2026년 5월 28일 출시되었으며 API 모델 ID claude-opus-4-8로 제공됩니다 . 새로운 제품 티어나 순수 추론 능력의 도약은 아닙니다. Anthropic은 이를 "더 효과적인 협업자"로 설명하며, 핵심 기술 주제는 단일 프롬프트에서 더 높은 순간 지능을 내는 것이 아니라 장시간 실행되는 에이전트 작업 전반에서 지속적이고 일관된 실행을 유지하는 데 있습니다 .
이런 설명이 중요한 이유는 몇 시간 동안 무인으로 돌아가는 실행에서 지배적인 실패 양상이 나쁜 최종 답변 하나가 아니기 때문입니다. 문제는 조용한 방향 이탈, 누락된 도구 호출, 컨텍스트 압축 이후의 잘못된 복구처럼 자신 있게 틀린 중간 단계가 누적되는 데 있습니다. Opus 4.8은 벤치마크 headline이 아니라 세 가지 신뢰성 레버로 이 실패 양상을 겨냥합니다:
- 오류를 더 자주 스스로 표시합니다. Anthropic은 이 모델이 자체 생성 코드의 결함을 언급 없이 통과시키는 경우가 Opus 4.7보다 대략 4배 적다고 보고합니다. 이 공급업체 주장은 뒤에서 다시 검토합니다.
- 의존성 추적이 더 좋아졌습니다. 이 모델은 모호한 문제를 분해하고, 의존성을 추적하며, 막힌 지점을 우회하고, 더 적은 확인 요청으로 스스로 수정하도록 조정되었습니다 .
- 요청하지 않은 진행 상황 주장이 줄었습니다. 불확실성을 드러낼 가능성은 더 높고, 뒷받침할 수 없는 진행 상황을 단정할 가능성은 더 낮습니다. 자율 루프를 망가뜨리는 거짓 "완료"와 같은 유형입니다 .
도입 판단에서 중요한 시간적 단서가 하나 있습니다. Opus 4.8은 출시 시점에 1위를 차지했지만, 그 자리를 지킨 기간은 2주가 채 되지 않았습니다. 2026년 6월 26일 기준 Anthropic의 자체 문서는 Claude Fable 5(2026년 6월 9일 출시)를 널리 공개된 모델 중 가장 유능한 모델로 제시합니다. Mythos 5는 제한적으로 제공됩니다. 따라서 질문은 Opus 4.8이 잠시 최고였는지가 아닙니다. 그 신뢰성 향상이 무인 파이프라인을 구축할 만큼 지속적이고 독립적으로 검증 가능한지입니다. 이 글의 나머지는 바로 그 점을 검증합니다.
budget_tokens 지원 중단: Opus 4.8이 대신 돌려주는 것
Opus 4.8에서 코드가 가장 먼저 마주칠 것은 거부된 요청입니다. 이 모델은 수동으로 예산을 지정하는 extended thinking을 제거했습니다. thinking: {type: "enabled", budget_tokens: N}가 포함된 호출은 API 수준에서 거부되며, 대신 adaptive thinking으로 이전해야 합니다 . 대체 방식은 한 줄입니다:
// Opus 4.7 and earlier — now rejected on claude-opus-4-8
thinking: { type: "enabled", budget_tokens: 32000 }
// Opus 4.8 — model decides how much to think
thinking: { type: "adaptive" }여기서의 논리는 고정 토큰 예산이 둔한 도구라는 점입니다. 쉬운 단계에는 과하게 할당하거나, 어려운 단계에는 부족하게 배정하게 됩니다. Adaptive thinking은 그 결정을 모델에 넘깁니다. 이는 이번 릴리스가 내세운 효율성 수치, 즉 Opus 4.7보다 작업당 턴 수 15% 감소와 출력 토큰 35% 감소와도 일관됩니다. 오케스트레이션 계층에 budget_tokens를 하드코딩했다면, Opus 4.8 트래픽을 흘리기 전에 반드시 패치해야 하는 breaking change는 이것 하나입니다.
거친 수준의 제어가 사라진 것은 아닙니다. 다섯 단계의 새 effort 파라미터로 이동했습니다: low, medium, high(기본값), xhigh, max . 기본 effort는 Claude API와 Claude Code 모두에서 high입니다. Anthropic은 특히 코딩과 장시간 실행되는 에이전트 작업에는 xhigh를 권장하며, max는 평가에서 추가 비용이 실제로 성과를 낸다는 점이 확인된 워크로드에 남겨둡니다 . max는 지향점이 아니라 명시적으로 선택하는 옵션으로 다루세요. 측정된 이득이 없다면 토큰만 태웁니다.
파이프라인 작성자에게 달라지는 점은 출력과 라우팅 제한 두 가지로 마무리됩니다. Batch API는 이제 output-300k-2026-03-24 베타 헤더를 통해 최대 300K 출력 토큰을 허용하는 반면, 동기 Messages API는 여전히 128K로 제한됩니다 . 전체 파일 재작성이나 대규모 리팩터링처럼 매우 긴 산출물을 생성한다면, 이 상한이 작업을 단일 동기 호출로 처리할지 배치 제출로 보낼지 결정합니다. 별도로 inference_geo: "us"로 트래픽을 미국 인프라에 고정하면 1.1배 가격 배수가 붙습니다 . 이는 데이터 레지던시 규칙 때문에 제약이 강제될 때만 의미가 있습니다.
순효과는 이렇습니다. 마이그레이션 자체는 작습니다. thinking 플래그 하나를 바꾸고, 필요하면 effort 수준을 설정하면 됩니다. 하지만 이제 기본값이 비용 대비 품질 결정을 더 많이 대신합니다. 각 effort tier가 무엇을 사 주는지 측정해 두었다면, 이는 무인 에이전트에 맞는 변화입니다.
결함을 말없이 넘길 가능성이 4배 낮다는 의미
핵심 신뢰성 주장은 Opus 4.8이 자신이 생성한 코드의 결함을 아무 언급 없이 통과시킬 가능성이 Opus 4.7보다 대략 4배 낮다는 것입니다 . 이는 Anthropic 발표와 업계 브리프에서 동일하게 반복된 벤더 보고 수치이며, 아직 독립적으로 재현되지는 않았습니다. 프로덕션 SLA가 아니라 자기 점검 행동에 대한 방향성 신호로 읽어야 합니다. 다만 특정하고 비용이 큰 실패 패턴을 겨냥하므로, 이 수치가 정확히 무엇을 약속하고 무엇을 약속하지 않는지 이해할 필요가 있습니다.
이 주장이 다루는 패턴은 조용한 드리프트입니다. 몇 시간 동안 무인으로 실행되는 작업에서 지배적인 실패 모드는 마지막에 나오는 하나의 치명적인 답변이 아닙니다. 놓친 도구 호출, 잘못된 컨텍스트 압축 복구, 검증되지 않은 가정처럼 자신감 있게 틀린 중간 단계들이 이어지고, 그것이 하위 단계로 전파되어 눈에 보이는 문제가 생기기 전까지 누적되는 방식입니다 . 실행 중간에 모델이 스스로 의심스러운 출력을 표시하면, 그 뒤의 수백 단계가 그 위에 쌓인 뒤가 아니라 아직 수정 비용이 낮을 때 오케스트레이션 계층이 오류를 잡을 기회를 얻습니다.
같은 목표를 강화하는 관련 행동 변화도 두 가지 있습니다. Anthropic은 Opus 4.8이 불확실성을 더 잘 드러내고, 근거 없는 진행 상황 주장을 덜 한다고 밝혔으며, 초기 테스터들도 같은 반응을 보였습니다 . 둘 다 매우 긴 컨텍스트에서 특히 중요합니다. 근거 없는 "완료" 주장과 거짓 자신감은 컨텍스트 압축을 바로 오염시키기 때문입니다. 모델이 아직 절반만 끝난 단계를 완료된 것으로 요약하면, 압축된 상태는 감사 추적 없이 그 오류를 그대로 다음 단계로 가져갑니다. 의심을 드러내는 것은 실행 중인 컨텍스트를 더 정직하게 유지합니다.
더 넓은 일관성 측면에서는 부분적인 외부 근거도 있습니다. 2026년 6월 10일 제출된 WorkBench Revisited는 Opus 4.8을 테스트된 에이전트 중 최고로 평가했으며, 작업 완료율 89%와 의도치 않은 유해 행동 2.5%를 기록했습니다. 이는 2024년 3월 기준 GPT-4의 완료율 43%, 유해 행동 26%와 대비됩니다 . 직장 업무 에이전트 신뢰성에 대한 강한 외부 데이터 포인트입니다. 하지만 이는 작업 수준의 결과를 측정한 것이지, 특정한 "언급되지 않은 결함" 메커니즘을 측정한 것은 아닙니다. 인접 벤치마크들은 상한도 보여줍니다. WildClawBench에서 Opus 4.7은 실제 CLI 에이전트 작업 60개에서 62.2%를 기록했고, RoadmapBench에서는 장기 업그레이드 작업 115개 중 39.1%만 해결했습니다 . 둘 다 4.8을 직접 평가한 것은 아니지만, 이 범주가 여전히 얼마나 어려운지 보여줍니다.
"작지만 실질적인 개선," — The Decoder가 Opus 4.8 릴리스를 전반적으로 평가한 표현 (source: The Decoder).
실무상 주의할 점은 이렇습니다. Anthropic은 4배 수치의 기반이 된 평가 하네스나 테스트 분포를 공개하지 않았습니다. 언어 구성, 작업 길이, "결함" 채점 방식이 무엇인지 알 수 없으므로, 이 비율이 그대로 자신의 코드베이스에 적용된다고 가정할 수 없습니다. 말없이 통과되는 오류가 줄어들 가능성을 기대할 근거로 보되, 무인 파이프라인이라면 여전히 필요한 사람의 리뷰, 로깅, 롤백 경로를 줄일 이유로 삼아서는 안 됩니다.
팬아웃과 복구: 동적 워크플로는 이렇게 움직입니다
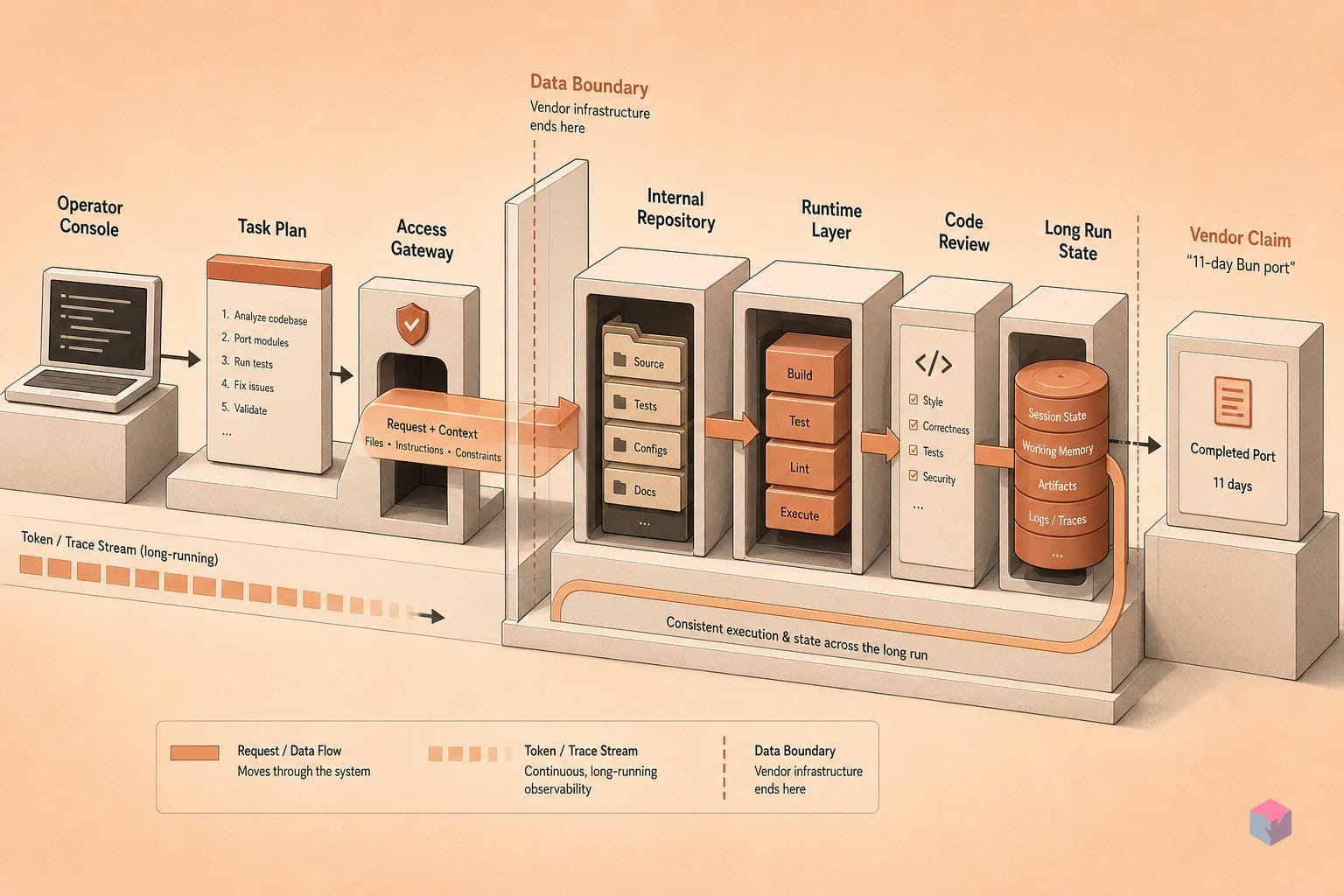
Dynamic Workflows는 Anthropic이 Opus 4.8과 함께 내놓은 오케스트레이션 계층입니다. 하나의 에이전트가 작업을 선형으로 밟아가는 대신, Claude가 작업 그래프를 계획하고 수십 개 또는 수백 개의 병렬 서브에이전트로 팬아웃하며, 각 하위 작업의 출력을 독립적으로 검증한 뒤 결과를 병합합니다. 이 모든 과정은 하나의 Claude Code 세션 안에서 이루어집니다 . 핵심은 턴이 이어질수록 드리프트가 누적되는 긴 직렬 실행을, 결과를 연결하기 전에 확인할 수 있는 짧고 경계가 있는 여러 실행으로 바꾸는 것입니다.
이 기능은 2026년 5월 28일 Opus 4.8과 함께 출시되었고, 이후 Claude Code CLI, Desktop, VS Code 확장, Pro, Max, Team 및 Enterprise 플랜, API, Amazon Bedrock, Google Cloud 전반에서 일반 제공으로 표시되었습니다 . 이 확산이 중요한 이유는 오케스트레이션이 단일 클라이언트에 묶여 있지 않기 때문입니다. 같은 팬아웃 동작이 터미널 세션, IDE 확장, 클라우드 호스팅 API 호출 어디서든 발생할 수 있습니다.
면밀히 봐야 할 부분은 내구성입니다. 워크플로는 몇 시간 또는 며칠 동안 지속될 수 있고, 진행 상황을 체크포인트로 저장하며, 중단 후 재개할 수 있습니다 . 여러 날 이어지는 작업 그래프에서 재개 가능성은 복구 가능한 일시적 문제와 처음부터 다시 실행해야 하는 상황을 가르는 차이입니다. 하지만 병렬 검증을 가능하게 하는 바로 그 팬아웃이 비용을 키우는 요소이기도 합니다. 수백 개의 서브에이전트를 생성하고, 각 에이전트가 컨텍스트를 소비하고 출력을 생성하는 실행은 같은 문제를 단일 에이전트로 처리할 때보다 토큰 지출을 크게 증폭합니다. Opus 4.8의 표준 요금이 입력 100만 토큰당 5달러, 출력 100만 토큰당 25달러라는 점을 고려하면 , 제한 없는 며칠짜리 워크플로는 반올림 오차가 아니라 실제 비용 노출입니다.
Anthropic은 이 기능에 두 가지 제동 장치를 넣었습니다. 관리자는 조직 설정에서 Dynamic Workflows를 비활성화할 수 있고, Claude Code는 워크플로가 처음 트리거될 때 확인을 요청합니다 . 하지만 둘 중 어느 것도 그 자체로 지출 한도는 아닙니다. 프로덕션 환경에서 팬아웃을 활성화하기 전에, 엄격한 예산 한도를 설정하고, 여러 날짜리 실행을 누가 승인할 수 있는지 정하며, 병합 실패를 추적할 수 있도록 로그가 서브에이전트 트리를 포착하는지 확인해야 합니다.
- 계획과 팬아웃: Claude가 하나의 세션 안에서 작업 그래프를 만들고 병렬 서브에이전트를 dispatch합니다 .
- 검증과 병합: 하위 작업 출력은 결과가 결합되기 전에 독립적으로 확인됩니다 .
- 체크포인트와 재개: 실행은 진행 상황을 저장하고 중단 후 복구됩니다. 다만 토큰 비용은 더 높아집니다 .
Artificial Analysis에서 WorkBench까지: 실제 환경에서 본 Opus 4.8
독립 벤치마크는 Anthropic이 내세운 신뢰성 프레이밍의 상당 부분을 뒷받침한다. 다만 가장 강한 수치는 몇 시간짜리 자율성을 입증한다기보다 지능과 효율의 개선을 보여준다. Artificial Analysis는 Opus 4.8을 Intelligence Index 61.4점으로 1위에 올렸다. Opus 4.7의 57.3점보다 4.1점 높고, GPT-5.5 (xhigh)보다 1.2점 앞선 수치다 . 이는 벤더 발표 자료가 아니라, 외부에서 재현된 측정 가능한 우위다.
에이전트형 작업에서의 격차는 일반 성능 격차보다 더 크다. GDPval-AA에서 Artificial Analysis는 Opus 4.8을 1,890 Elo로 기록했다. Opus 4.7의 1,753보다 137점 오른 수치이며, GPT-5.5보다 121점 앞서 약 67%의 정면 대결 승률을 시사한다 . 장시간 파이프라인에서 더 유용한 수치는 효율이다. Opus 4.8은 Opus 4.7보다 작업당 턴 수를 약 15%, 출력 토큰을 35% 적게 쓰면서도 같은 점수대에 도달한다 . 턴과 토큰이 줄어들면 장기 세션에서 드리프트와 비용이 직접적으로 줄어든다. 무인 에이전트에서 누적되는 바로 그 실패 양식이다.
| 신호 | 결과 | 출처 |
|---|---|---|
| Intelligence Index | 61.4 (4.7의 57.3 대비, GPT-5.5보다 +1.2) | Artificial Analysis |
| GDPval-AA 에이전트 Elo | 1,890 (4.7의 1,753 대비, 승률 약 67%) | Artificial Analysis |
| 4.7 대비 효율 | 턴 15% 감소, 출력 토큰 35% 감소 | Artificial Analysis |
| WorkBench Revisited 완료율 | 작업 89%, 유해 행동 2.5% | WorkBench Revisited |
| WildClawBench (Opus 4.7) | 실제 CLI 작업 60개에서 62.2% | WildClawBench |
| RoadmapBench (Opus 4.7) | 업그레이드 작업 115개에서 39.1% | RoadmapBench |
가장 강한 실제 환경 신호는 Anthropic 바깥에서 나온다. 2026년 6월 10일 제출된 WorkBench Revisited는 Opus 4.8을 테스트 대상 중 최고의 에이전트로 꼽았다. 직장 업무 완료율은 89%, 의도치 않은 유해 행동은 2.5%에 그쳤다. 2024년 3월 GPT-4의 완료율 43%, 유해 행동 26%와 대비된다 . 이는 Anthropic이 말하는 일관성 서사를 독립적으로 뒷받침하는 결과이며, 리더보드보다 기업 자동화에 더 가까운 작업 부하에서 나온 신호다.
다만 상한선은 계속 봐야 한다. 인접한 두 벤치마크는 Opus 4.8이 아니라 4.7을 평가했지만, 어려운 구간이 여전히 얼마나 힘든지 경계를 그어준다. WildClawBench에서 Opus 4.7은 실제 CLI 에이전트 작업 60개에서 62.2%에 그쳤고 , RoadmapBench에서는 17개 저장소와 5개 언어에 걸친 장기 버전 업그레이드 작업 115개 중 39.1%만 해결했다 . 세대 간 개선을 감안하더라도, 여러 저장소를 넘나드는 업그레이드와 제약 없는 CLI 작업은 여전히 에이전트가 가장 자주 실패하는 영역이다.
정직하게 읽으면 이렇다. Opus 4.8의 지능과 효율 개선은 독립적으로 확인됐고, WorkBench Revisited는 직장 업무 일관성에 대한 진짜 외부 지지표다. 하지만 에이전트가 멈춰서는 고난도 작업 벤치마크는 4.7에서 측정됐고, 여러 날에 걸친 자율성을 4.8로 압박 테스트한 독립 스위트는 아직 없다. 헤드라인 점수는 실제라고 보고, 장기 내구성은 아직 벤치마크가 얇다고 봐야 한다. 중요한 무인 실행에 작업별 평가가 필요한 이유도 바로 여기에 있다.
11일, 75만 줄: Bun 재작성 사례가 보여주는 것
Anthropic이 Opus 4.8과 Dynamic Workflows를 앞세워 내놓은 대표 시연은 Bun 런타임을 Zig에서 Rust로 포팅한 작업이다. Rust 코드 약 75만 줄, 기존 테스트 스위트 99.8% 통과, 첫 커밋부터 병합까지 11일이라는 결과다 . 프로덕션 규모에서 여러 날짜리 무인 오케스트레이션이 가능하다는 존재 증명으로는 충분히 의미가 있다. 하지만 이 작업을 에이전트에 맡기고 자리를 비워도 된다는 증거는 아니다. 이 두 해석 사이의 간극이 핵심이다.
먼저 Anthropic이 명확히 밝힌 단서부터 봐야 한다. 2026년 6월 말 기준 이 포팅 결과물은 프로덕션에 투입되지 않았다 . 이는 Anthropic이 선택한 조건에서, Anthropic이 큐레이션한 엔지니어링 쇼케이스다. 평가 기준으로 삼을 수 있는 강력한 기존 테스트 스위트가 유난히 잘 갖춰진 코드베이스에서 실행됐다. 실전 배포로 검증된 사례가 아니며, 독립적으로 재현된 것도 아니다.
그럼에도 장기 에이전트를 검토하는 사람에게 이 사례가 실제로 보여주는 바는 중요하다. 팬아웃 아키텍처는 11일 동안 이어진 실행에서 작업을 계획하고, 병렬 서브에이전트에 배분하고, 검증하고, 병합하는 흐름을 드리프트로 무너지지 않게 유지했다 . 보통 몇 시간짜리 실행이 부딪히는 실패 양식이 바로 이것이고, 75만 줄 규모에서 버텼다는 점은 오케스트레이션 계층이 큰 범위에서도 일관성을 유지할 수 있다는 실제 신호다. 또한 기존 스위트의 99.8%를 통과하는 산출물을 냈다. 설정된 기준에 대해서는 강한 결과다.
입증하지 못한 부분은 테스트 스위트가 보지 못하는 모든 것이다. 기존 테스트의 99.8%를 통과했다는 말은 원 작성자들이 이미 인코딩해 둔 동작에 부합한다는 뜻이다. 남은 0.2%의 간극, 테스트되지 않은 경로, 컴파일되고 테스트를 통과하지만 부하 상황에서 다르게 동작하는 미묘한 의미론적 회귀에 대해서는 아무 말도 하지 않는다. JavaScript 런타임을 Zig에서 Rust로 재작성하는 작업은 메모리 모델, 동시성, 엣지 케이스 차이가 테스트 커버리지 아래 숨어 있기 딱 좋은 영역이다. 이 시연은 이 규모에서 비용 효율이 어떤지도 알려주지 않는다. Dynamic Workflows는 몇 시간 또는 며칠 동안 실행되기 때문에 토큰을 훨씬 많이 소비한다고 문서화되어 있다 .
유지해야 할 프레이밍은 The Decoder가 이번 릴리스 전체에 적용한 표현이다. "a modest but tangible improvement"라는 말처럼, 실제이지만 경계가 있는 능력으로 읽어야지 완성된 자율성 이야기로 읽어서는 안 된다 (source: The Decoder, 2026-05). Bun 포팅은 이 메커니즘이 큰 범위에서도 작동한다는 증거로 받아들이면 된다. 그리고 자신의 코드베이스에서는 테스트 스위트가 정확성의 상한이 아니라 하한이라고 가정해야 한다. 이 정도로 큰 포팅에서 녹색 실행이 나왔다는 것은 리뷰가 끝났다는 뜻이 아니라 리뷰가 시작되는 지점이다.
Opus 4.8 출시 전에 잡아야 할 예산

Opus 4.8의 표준 요금은 Opus 4.7과 동일합니다. 입력 토큰 100만 개당 $5, 출력 토큰 100만 개당 $25이며, 100만 토큰 컨텍스트 창도 유지됩니다 . 실제 비용 모델을 바꾸는 항목은 fast mode입니다. Opus 4.6과 4.7에서 부과되던 MTok당 $30/$150에서 $10/$50으로 내려가 약 3배 저렴해졌고, 초당 출력 토큰 처리량은 약 2.5배 높습니다 . 이 변화 하나가 고처리량, 저지연 워크로드를 애매한 선택지에서 현실적인 선택지로 옮깁니다. 헤드라인 요금이 아니라 이 항목을 기준으로 예산을 잡아야 합니다.
캐싱과 배칭은 여러 시간 동안 실행되는 에이전트가 마진을 회복하는 지점입니다. 캐시 쓰기는 MTok당 $6.25(5분) 또는 $10(1시간), 캐시 히트는 MTok당 $0.50이며, Batch API는 일괄 50% 할인을 적용해 표준 요금을 입력 $2.50, 출력 $12.50으로 낮춥니다 . 안정적인 시스템 프롬프트와 재사용되는 컨텍스트가 있는 장기 오케스트레이션에서는 1시간 캐시와 비대화형 단계의 배칭이 감당 가능한 청구서와 부담스러운 청구서를 가르는 경우가 많습니다.
| 모드 / 조정 항목 | 입력 ($/MTok) | 출력 ($/MTok) |
|---|---|---|
| 표준 | $5.00 | $25.00 |
| Fast mode (4.8) | $10.00 | $50.00 |
| Fast mode (4.6 / 4.7) | $30.00 | $150.00 |
| Batch API (−50%) | $2.50 | $12.50 |
| 캐시 쓰기 (5분 / 1시간) | $6.25 / $10.00 | — |
| 캐시 히트 | $0.50 | — |
두 가지 플랫폼 제약은 사후 분석이 아니라 설계 단계에 들어가야 합니다. 100만 토큰 컨텍스트는 Claude API, Amazon Bedrock, Google Cloud에는 적용되지만 Microsoft Foundry는 200K로 제한됩니다 . Azure 호스팅 배포에서 다중 문서 파이프라인을 운영한다면 이것은 단단한 상한입니다. 동기식 Messages API 출력은 최대 128K 토큰이며, Batch API에서는 output-300k-2026-03-24 베타 헤더로 최대 300K까지 사용할 수 있습니다. 미국 전용 라우팅(inference_geo: "us")은 1.1배 배율을 추가합니다 . 워크로드에 실제로 필요한 컨텍스트 예산을 기준으로 플랫폼을 고르십시오.
Dynamic Workflows는 설계상 토큰 지출을 키웁니다. 수십에서 수백 개의 서브에이전트로 팬아웃하고, 독립 검증을 수행하며, 몇 시간 또는 며칠에 걸쳐 실행되는 구조는 단일 에이전트 루프보다 훨씬 많은 토큰을 소비합니다 . 중요한 무인 실행에 이를 켜기 전에 네 가지를 마련해야 합니다. 지출 상한, 구조화된 로깅, 롤백 경로, 사람 검토 체크포인트가 포함된 작업별 평가입니다. Anthropic도 같은 통제를 권장합니다 . 관리자는 Workflows를 완전히 비활성화할 수 있고, Claude Code는 첫 트리거 시 확인을 요구하므로 기본 태도는 보수적입니다. 예산 작업의 핵심은 실제 코드베이스에 팬아웃을 풀기 전에 가드레일 비용까지 확보하는 것입니다.
Opus 4.8이 가장 잘 맞는 파이프라인과 그렇지 않은 경우
Opus 4.8은 자신 있게 틀린 중간 단계가 누적될 수 있는 장기 실행, 저감독 작업에서 가장 큰 효과를 냅니다. 여러 시간 동안 무인으로 돌아가는 코딩 에이전트, 잘못된 확신이 하위 단계로 연쇄되는 엔터프라이즈 자동화, 병렬 서브에이전트 오케스트레이션을 원하는 Claude Code CLI 사용 팀이 여기에 해당합니다. 이를 뒷받침하는 신호도 구체적입니다. GDPval-AA는 137점 상승해 1,890 Elo에 도달했고, Opus 4.7보다 턴 수는 15%, 출력 토큰은 35% 적게 사용했습니다 . WorkBench Revisited에서는 작업 완료율 89%, 의도치 않은 유해 행동 2.5%를 기록했습니다 . 이런 프로필에서는 턴 수 감소가 세션 전반의 드리프트 감소와 비용 절감으로 곧장 이어집니다.
다른 영역에서는 적합성이 크지 않습니다. 대화형 앱과 지연 시간에 민감한 파이프라인에서는 자기 수정 동작이 턴을 줄이기보다 늘릴 수 있고, 내구성 있는 실행 추적보다 최종 답변이 더 중요한 곳에서는 adaptive-thinking 오버헤드가 낭비됩니다. Opus 4.7이 이미 평가를 통과한다면 반드시 이전해야 할 이유는 없습니다. Anthropic도 4.8을 점진적 업그레이드로 설명했고, The Decoder는 이를 "modest but tangible improvement"라고 불렀습니다 . 또한 2026년 6월 26일 기준 Anthropic 자체 문서에는 더 새로운 모델인 Fable 5와 제한 제공되는 Mythos 5가 올라와 있으므로, 4.8은 더 이상 라인업 최상단 모델이 아닙니다 .
성능과 별개로 다시 평가할 만한 변화가 하나 있습니다. fast mode가 입력/출력 토큰 100만 개당 $10/$50으로 내려갔다는 점입니다. Opus 4.6과 4.7의 $30/$150에서 낮아져 약 3배 저렴해졌습니다 . 고처리량 사용 사례에서 비용 때문에 빠른 Opus를 제외했다면 모델을 다시 돌려볼 만합니다. 표준 요금($5/$25 per MTok, 100만 토큰 컨텍스트)은 그대로입니다 . 경제성이 바뀐 지점은 처리량 티어입니다.
어떤 모델을 선택하든 결론은 같습니다. 더 강한 자기 점검은 운영상 안전장치를 대체하지 못합니다. Super-Agent 엔드투엔드 완료, 지적되지 않은 결함 4배 감소, 많은 턴에 걸친 지속적 일관성 같은 가장 강한 주장들은 Anthropic이 보고한 것이며 아직 독립적으로 재현되지 않았습니다 . 또한 2026년 6월 16일 레드팀 논문은 7,826개의 유해 의도 중 11.5%에서 여전히 모델을 뚫었습니다 . 따라서 작업별 평가, 사람 검토 체크포인트, 구조화된 로깅, 롤백 경로, 지출 상한을 유지하십시오. 이런 장치가 없으면 조용히 실패할 수 있는 장기 에이전트에 투자할 때 Opus 4.8을 선택하고, 현재 모델이 이미 기준을 넘는다면 마이그레이션은 건너뛰는 편이 낫습니다.
마지막 업데이트: 2026-06-26.
자주 묻는 질문
Claude Opus 4.8과 Opus 4.7은 무엇이 다른가요?
Opus 4.8은 새로운 역량 등급이라기보다 신뢰성과 오케스트레이션을 점진적으로 끌어올린 업그레이드입니다. Anthropic에 따르면 Opus 4.8은 Opus 4.7보다 자신이 생성한 코드의 결함을 지적 없이 그냥 통과시킬 가능성이 약 4배 낮습니다 . 또한 수동으로 예산을 정하던 extended thinking을 adaptive thinking으로 바꾸고, 장시간 작업을 위한 Dynamic Workflows를 추가했습니다 . 독립 벤치마크 개선도 실제로 확인되지만 폭은 크지 않습니다. Artificial Analysis의 Intelligence Index는 4.1점 오른 61.4를 기록했고, agentic GDPval-AA Elo는 137점 오른 1,890을 기록했습니다 .
budget_tokens에서 새로운 Opus 4.8 API로 어떻게 이전하나요?
Opus 4.8은 thinking: {type: "enabled", budget_tokens: N}을 거부하므로, 이를 thinking: {type: "adaptive"}로 바꾸고 effort 파라미터를 추가해야 합니다. 값은 low, medium, high, xhigh, max 중 하나입니다 . Claude API와 Claude Code 전반의 기본값은 high입니다. Anthropic은 코딩 에이전트와 장시간 agentic 실행에는 xhigh를 권장하고, max는 자체 평가에서 추가 비용이 정당화되는 워크로드에만 쓰라고 안내합니다 .
독립적으로 검증된 Opus 4.8 벤치마크 결과는 무엇인가요?
가장 탄탄한 독립 출처 수치는 Artificial Analysis의 결과입니다. Intelligence Index 61.4, GDPval-AA Elo 1,890, 그리고 작업당 턴 수는 Opus 4.7보다 약 15% 적고 출력 토큰은 약 35% 적다는 수치입니다 . WorkBench Revisited도 외부 결과로, 2026년 6월 10일 제출된 평가에서 작업 완료율 89%, 의도치 않은 유해 행동 2.5%를 보고했습니다 . 반면 자기 수정 능력이 4배 높다는 주장, SWE-Bench Pro 69.2% 점수, Super-Agent 엔드투엔드 결과는 Anthropic이 보고한 수치이며 아직 제3자가 재현하지는 않았습니다 .
Dynamic Workflows는 무엇이고 언제 켜야 하나요?
Dynamic Workflows는 Claude Code에 내장된 fan-out 오케스트레이션입니다. Claude가 작업 그래프를 계획하고, 수십에서 수백 개의 병렬 서브에이전트를 띄우며, 각 출력물을 독립적으로 검증한 뒤 결과를 병합합니다 . 이 기능은 사용자가 직접 켜야 하며 관리자가 비활성화할 수 있습니다. 몇 시간 또는 며칠 동안 실행될 수 있고, 진행 상황을 저장하며, 중단 후에도 재개할 수 있습니다. 여러 날에 걸친 코딩이나 리서치 작업에는 적합하지만 토큰을 훨씬 더 많이 쓰므로, 프로덕션에서 켜기 전에는 지출 한도, 구조화된 로깅, 롤백 경로를 먼저 마련해야 합니다 .
2026년 중반 기준 Claude Opus 4.8은 여전히 가장 뛰어난 Claude 모델인가요?
아닙니다. 2026년 6월 26일 기준 Anthropic 문서는 2026년 6월 9일 출시된 Claude Fable 5를 널리 공개된 모델 중 가장 강력한 모델로 제시하며, Mythos 5는 제한적으로 제공된다고 설명합니다 . Opus 4.8은 2026년 5월 28일 출시 당시에는 1위였지만, 최상위 자리를 지킨 기간은 2주가 채 되지 않았습니다 . 장기 실행 에이전트에는 여전히 합리적인 선택이지만, Anthropic 라인업에서 더 이상 최전선 모델은 아닙니다.