
For three years, the question buyers asked of an AI coding tool was simple: how fast does it autocomplete? Gartner's 2026 reframing quietly retired that question — and most procurement scorecards haven't caught up.
From Assistants to Agents: What Gartner Now Measures
Gartner has re-scoped its coding-tool evaluation from autocomplete to autonomy. The firm renamed its "Magic Quadrant for AI Code Assistants" (doc 6948266) to the "Magic Quadrant for Enterprise AI Coding Agents" (doc 7879277), published May 20, 2026 . The new bar is not line completion — it is whether a tool can plan a multi-step implementation, run its own tests, debug failures, and surface a pull request for human review.
That rename is a deliberate scope expansion, not cosmetics. The prior edition measured in-editor assistants that suggested code as you typed; the 2026 edition measures agents that operate across a workflow — reading unfamiliar codebases, using developer tools, making changes, executing tests, and preparing PR-oriented work . Gartner's framing is that the market itself moved: the unit of value shifted from a suggestion to a completed, reviewable task.
The money follows the reframing. Secondary analyst estimates cited alongside the report pegged the addressable market at roughly $9.8–11.0 billion annualized as of April 2026 — a category large enough that vendor positioning carries real procurement weight.
The direct implication for anyone running a vendor evaluation: RFPs built to benchmark autocomplete latency or suggestion-acceptance rate are now measuring the wrong axis. If your scorecard does not test whether an agent can decompose a ticket, run the test suite, recover from a failing build, and hand back a clean diff, it is grading the previous generation of tooling. The rest of this series digs into what that shift exposes — starting with a problem you'll hit immediately: you can't actually see the full Leaders roster to verify any of it.
One caveat worth holding onto: Gartner explicitly states its publications are opinions, not statements of fact, and the underlying graphic sits behind a client paywall. The reframing is real; treat the specific placements that follow as claims to be checked, not settled record.
The Verification Problem: Why You Can't See the Complete Leaders Roster
The complete Leaders roster is not publicly verifiable, because the only ungated Gartner text contradicts the headline. The abstract still live at gartner.com/en/documents/6948266 is titled "Magic Quadrant for AI Code Assistants," published September 15, 2025 with a refresh date of May 20, 2026, and its visible 14-vendor list does not name OpenAI . So before you cite "OpenAI is a Gartner Leader" in a vendor review, know that the primary document a non-subscriber can read says something narrower.
The public list reads: Alibaba Cloud, Amazon, Anysphere (Cursor), Augment Code, Cognition (Windsurf), GitHub, GitLab, Google Cloud, Harness, IBM, JetBrains, Qodo, Tabnine, and Tencent Cloud . The companion Critical Capabilities abstract (doc 6953766) carries the same 14 names and likewise omits OpenAI .
The most plausible reconciliation is timing, not contradiction. A separate document ID — 7879277 — exists for the renamed "Enterprise AI Coding Agents" edition, which is gated client-only content . If the public-facing abstract simply predates the gated May 20, 2026 refresh, then the rescoped quadrant and any OpenAI placement live only behind the paywall, and the ungated page is a stale snapshot of the prior report. That fits the evidence, but it is inference, not confirmation.
What this means in practice: every OpenAI-as-Leader claim traces back to OpenAI's own announcement and downstream tech-press summaries . The underlying graphic, the axis criteria and their weighting, and the full Leaders roster are unverifiable without a Gartner subscription. When a vendor is the sole source for its own ranking, that gap matters.
Gartner is explicit about the epistemics here. Its standard disclaimer states that its research publications "consist of the opinions of Gartner's research organization and should not be construed as statements of fact" . Read with that caveat, the recognition is a defensible analyst opinion sourced largely to the analyzed vendor — useful signal, not settled record. Treat the placements that follow as claims to check.
Reading the 2026 Quadrant: Named Leaders, Visionaries, and What's Absent
The placements reported from the 2026 quadrant cluster around four vendors: GitHub Copilot, OpenAI Codex, and Cursor share the Leaders zone, while Tabnine sits a tier down as a Visionary. None of this is visible in the public abstract, so each position below is sourced to vendor posts and secondary tech-press reconstructions rather than the gated Gartner graphic — useful for orientation, not confirmation.
GitHub Copilot is reported to rank highest on Ability to Execute, the axis Gartner uses for delivery and market traction, reflecting its largest installed base, broadest IDE coverage, and deepest enterprise customer density . OpenAI Codex is named a Leader alongside it; Gartner is reported to credit Codex's agentic software development, OS-level sandboxing, and enterprise governance . Cursor (Anysphere) is positioned strongest on Completeness of Vision — the fastest-growing independent tool, model-agnostic by design, and a strong performer on acceptance rates in independent pull-request studies, where one February 2026 arXiv analysis of 7,156 PRs found no single agent dominated every task type . Tabnine lands as a Visionary, not a Leader, differentiating on on-prem and air-gapped deployment for regulated industries .
| Vendor | Reported position | Strongest axis | Key differentiator |
|---|---|---|---|
| GitHub Copilot | Leader | Ability to Execute (highest) | Largest installed base, broadest IDE coverage, enterprise density |
| OpenAI Codex | Leader | Agentic execution + governance | OS-level sandboxing, RBAC, approval gates |
| Cursor (Anysphere) | Leader | Completeness of Vision (strongest) | Model-agnostic, fastest-growing independent tool |
| Tabnine | Visionary | Deployment flexibility | On-prem / air-gapped for regulated sectors |
What's absent matters as much as what's named. Independent analysis pegs the addressable market at roughly $9.8–11.0 billion annualized as of April 2026 , so a roster reshuffle has real budget consequences — yet the full Leaders list, the other quadrant tiers, and the criteria weighting that produced these positions all remain client-only. The four placements above are the ones vendors and secondary outlets chose to surface; treat the rest of the chart as unread.
Sandboxing, RBAC, and Approval Gates: What the New Bar Looks Like
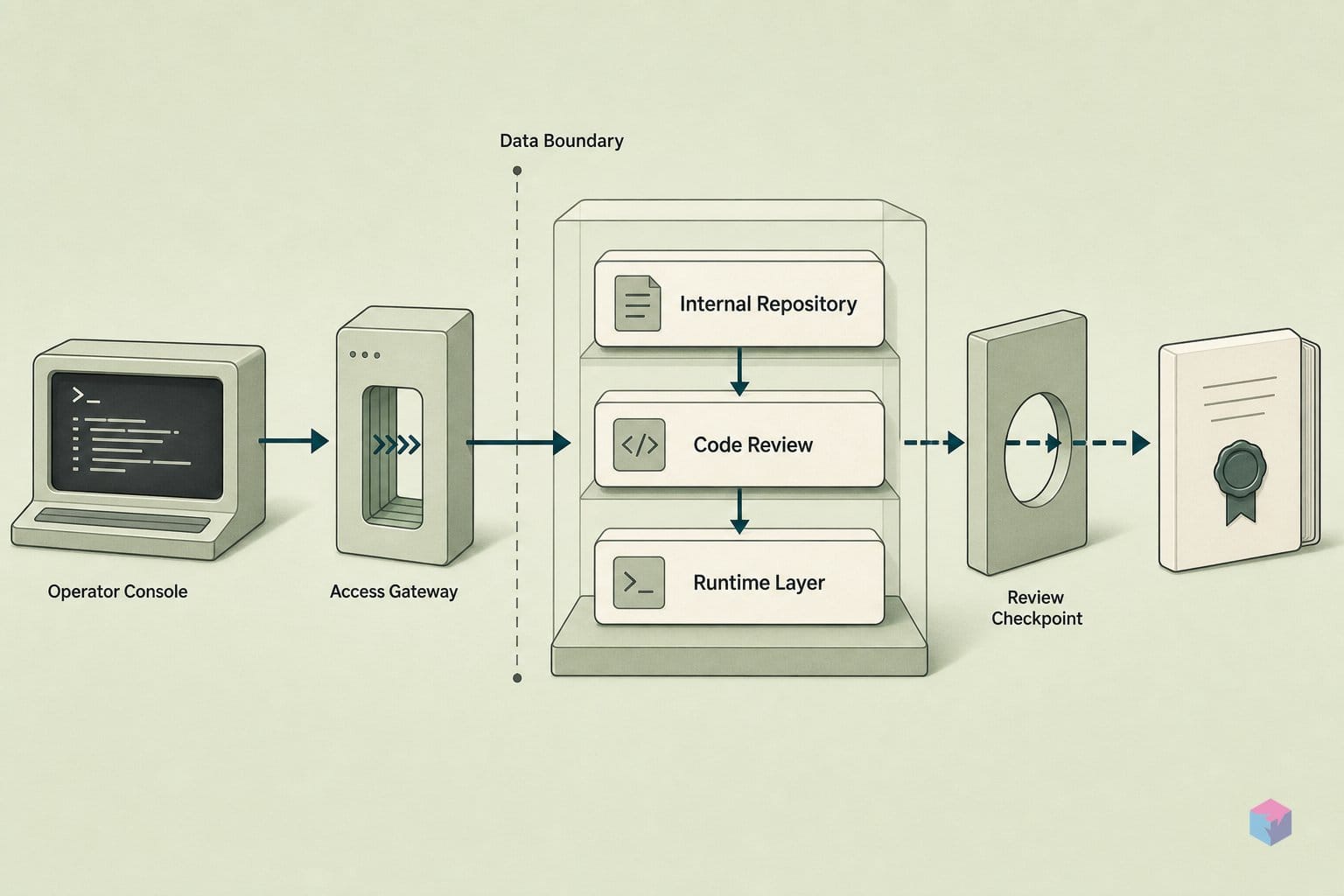
The features that earned Codex its reported Leader placement are governance controls, not raw code-generation speed. Gartner is reported to have highlighted OS-level sandboxing, flexible deployment, role-based access control with customizable policies, and auditable workspace governance as Codex strengths . The practical read for a platform team: when an agent can plan, edit, run tests, and open pull requests on its own, the evaluative weight shifts to how tightly you can constrain and audit that autonomy.
The deployment surface is broad. Codex ships as a desktop and web app (macOS and Windows), IDE extensions, a CLI, and SDKs, with cloud-based orchestration and distribution through Amazon Bedrock; OpenAI also cites HIPAA-compliant usage options . Enterprise controls include approval gates, RBAC, customizable policies, and workspace governance auditable through the Compliance API . Treat these as vendor-reported — they are the differentiators OpenAI chose to surface, not independently audited results.
Approval gates are the structural detail worth noting. Codex stages pull-request-oriented work for human review rather than auto-committing, so the human-in-the-loop handoff is an evaluated feature rather than an afterthought . The agent prepares the diff, runs tests, and proposes the change; a person still merges it.
On the compliance question developers ask most: OpenAI states that Business, Enterprise, Edu, and API inputs and outputs are not used to improve models by default — note the precise scope, since consumer-tier defaults differ .
"Cisco used Codex to build its AI Defense security platform, reducing development time from months to weeks," — OpenAI, in its recognition announcement (source: OpenAI).
5 Million Weekly Users, 20% Not in Engineering
Codex's reach is the clearest growth signal OpenAI has put on record, and the trajectory is steep. In its June 2, 2026 announcement, "Codex for every role, tool, and workflow," OpenAI reported more than 5 million weekly users — up from the 4 million-plus figure cited around the May 20 Gartner recognition . That delta, roughly two weeks apart, is the most recent adoption number available and reads as a deliberate framing: Codex is no longer a developer-only tool.
The composition matters more than the headcount. OpenAI states that non-developers make up about 20% of Codex users, and that this cohort is growing more than 3× faster than the developer segment . For a product positioned in Gartner's "Enterprise AI Coding Agents" category, that is a notable drift — the agent is being pulled toward workflows that do not involve writing code at all.
The June 2 expansion is built to absorb that demand. It introduced six role-specific plugins — data analytics, creative production, sales, product design, public-equity investing, and investment banking — bundling 62 apps and 110 skills . Alongside them, OpenAI shipped Sites in preview for Business and Enterprise customers, letting Codex create and host workspace-internal apps and websites; named ecosystem partners include Vercel, Wix, Figma, Replit, and Lovable .
For a developer evaluating Codex, the read-through is twofold: the same governance surface you standardize on for engineering now extends to finance analysts and sales teams spinning up internal tools — which raises the stakes on the RBAC and audit controls covered earlier, not lowers them.
PR Acceptance Rates Across Nine Task Types: No Single Tool Wins

No single coding agent dominates every task category — the leaderboard rank you standardize on may not match the work your queue actually contains. A February 2026 arXiv study analyzed 7,156 pull requests across OpenAI Codex, GitHub Copilot, Devin, Cursor, and Claude Code, reporting Codex acceptance rates ranging from 59.6% to 88.6% across nine task categories . The same analysis found no agent led all nine: Claude Code led documentation and feature tasks, while Cursor led fix tasks .
That spread matters because acceptance rate is task-conditional, not a global score. An agent that tops fix tasks can trail on documentation, and vice versa. The study's own framing — that leadership rotates by category — undercuts the idea that one vendor's Gartner placement settles your tooling decision.
| Task type | Reported category leader | Source signal |
|---|---|---|
| Documentation | Claude Code | Highest acceptance in category |
| Feature work | Claude Code | Highest acceptance in category |
| Fixes | Cursor | Highest acceptance in category |
| Several remaining categories | OpenAI Codex | Within 59.6%–88.6% acceptance band |
Scale gives the finding weight. The companion AIDev dataset paper reported 932,791 agent-authored pull requests across 116,211 repositories and 72,189 developers, covering the same five agents — the largest published cross-agent PR corpus available as of this writing . This is observational data from real repositories, not a vendor benchmark, which makes it a useful counterweight to the marketing-adjacent capability claims attached to the Gartner recognition.
The practical implication for engineering teams is concrete: the task-category composition of your queue matters more than overall leaderboard rank. A team shipping mostly bug fixes weights differently than one writing greenfield features or migrating documentation. Where the volume justifies it, a polyglot setup — routing fixes, features, and docs to whichever agent leads that category — can outperform single-vendor standardization, provided your governance surface (the RBAC and approval gates covered earlier) can span more than one agent without fragmenting audit trails.
Picking a Vendor When Governance Outweighs Autocomplete
When you standardize on a single agent, weight the governance surface — sandboxing, RBAC, approval gates, and auditability — ahead of raw pull-request acceptance rates. The Gartner rename from "AI Code Assistants" to "Enterprise AI Coding Agents" is the signal: the institutional bar is now whether an agent can be delegated multi-step work under controls, not how often its autocomplete is accepted. Acceptance percentages tell you who codes well; governance tells you who you can actually deploy.
Deployment posture is where shortlists diverge most. For regulated environments weighing HIPAA or FedRAMP constraints, three Leaders offer meaningfully different answers: Codex ships a HIPAA-compliant usage option and distribution through Amazon Bedrock ; Tabnine targets on-prem and air-gapped installs; and GitLab leans on self-hosted control. Match the posture to your compliance perimeter before you compare features.
If compliance constraints are looser and developer experience is the priority, Cursor's model agnosticism and Windsurf's strong Completeness-of-Vision placement are worth evaluating . Flexibility in model routing matters more for teams that aren't locked to one provider.
One procurement shift deserves attention: with non-developers now roughly 20% of Codex users and role-specific plugins reaching sales, finance, and product, evaluation no longer belongs to engineering alone. IT and procurement leads become co-evaluators.
The concrete takeaway: write your shortlist from your compliance perimeter inward — posture first, governance second, benchmarks third — and bring procurement into the room before you sign.
Frequently asked questions
Is OpenAI actually a Gartner Magic Quadrant Leader for Enterprise AI Coding Agents?
Yes, according to OpenAI's official announcement and downstream tech press — but you cannot independently confirm it without a Gartner license. OpenAI states it was named a Leader in the inaugural Gartner Magic Quadrant for Enterprise AI Coding Agents, published May 20, 2026, with the recognition tied to Codex. The catch: the underlying Gartner graphic is client-only gated content. The publicly visible abstract is still titled "Magic Quadrant for AI Code Assistants" and lists 14 vendors — Alibaba Cloud, Amazon, Anysphere (Cursor), Augment Code, Cognition (Windsurf), GitHub, GitLab, Google Cloud, Harness, IBM, JetBrains, Qodo, Tabnine, and Tencent Cloud — none of them OpenAI. The most plausible reading is that this abstract predates the gated refresh, so any OpenAI placement lives only in the licensed report. The Leader claim therefore rests on vendor posts, not non-vendor primary text.
What changed when Gartner renamed the quadrant from "AI Code Assistants" to "Enterprise AI Coding Agents"?
The rename re-scopes what gets measured. The prior framing ("AI Code Assistants," Gartner doc 6948266) centered on in-editor autocomplete and single-line or block completion. The 2026 edition (doc 7879277) shifts the bar to whether a tool can autonomously plan, implement, run tests, debug, perform code review, and submit pull-request-ready work for human approval . For a vendor evaluation, that means governance features tied to delegation — sandboxing, approval gates, role-based access control, auditability — move from nice-to-have to decisive, because you are now handing agents multi-step engineering tasks rather than inline suggestions.
Which vendor leads on Ability to Execute versus Completeness of Vision in the 2026 report?
Per secondary reporting, GitHub Copilot ranked highest on Ability to Execute — reflecting the largest installed base and broadest enterprise penetration — while Cursor (Anysphere) was positioned strongest on Completeness of Vision, citing fast growth, model agnosticism, and architectural flexibility . OpenAI Codex was also named a Leader, and Tabnine was placed as a Visionary. Treat these as secondary-source attributions: Gartner evaluates on the two standard axes, but the primary graphic, criteria weighting, and exact dot positions are behind the paywall and unverifiable from non-vendor sources.
What governance features should engineering leads evaluate when standardizing on an Enterprise AI Coding Agent?
Build the checklist around your compliance perimeter: OS-level sandboxing granularity, RBAC scope and customizability, approval-gate configuration, and auditability through a compliance API. Critically, confirm whether your inputs are used to train models — OpenAI states that Business, Enterprise, Edu, and API inputs and outputs are not used to improve models by default . For regulated industries, HIPAA-compliant usage options and availability through Amazon Bedrock are real differentiators . Codex exposes approval gates, RBAC, customizable policies, and auditable workspace governance, with usage available via the Compliance API.
Is OpenAI Codex only for software developers?
No, and that mix is shifting fast. As of June 2, 2026, OpenAI says more than 5 million people use Codex weekly, that roughly 20% are non-developers, and that non-developer usage is growing more than 3× as fast as the developer segment . The same announcement introduced six role-specific plugins — covering data analytics, creative production, sales, product design, public-equity investing, and investment banking — bundling 62 apps and 110 skills, plus Sites in preview for hosting internal apps. The target is knowledge workers who need internal dashboards and automated workflows without writing code.








