
vLLM v0.22.0은 수백 개의 커밋과 함께 출시됐지만, 그중 눈에 잘 띄지 않는 변경 사항 하나가 GPU 성능과는 전혀 무관한 문제를 겨냥합니다. 데이터 병렬 규모가 커질수록 가속기는 유휴 상태에 빠지는 반면, 단일 Python 프로세스는 HTTP 작업에 발목이 잡힙니다.
DP LLM 서빙은 왜 CPU 한계에 부딪히나?
vLLM의 데이터 병렬(DP) 서빙이 CPU 한계에 부딪히는 이유는, 모델이 여러 GPU에 걸쳐 실행되더라도 모든 요청이 단일 Python 프론트엔드 프로세스를 통과해야 하기 때문입니다. 각 DP 랭크는 별도의 "코어 엔진" 프로세스로 실행되며 ZMQ 소켓을 통해 프론트엔드에 연결되지만, HTTP 파싱, 토큰화, 요청 검증, 응답 스트리밍은 모두 단일 API 서버 프로세스에 집중됩니다 . 병목은 카드 용량이 아니라 프로세스 포화 상태에 있습니다.
동작 방식을 정확히 짚어볼 필요가 있습니다. DP 배포에서 내부 로드 밸런싱은 API 서버 프로세스 내부에서 이루어지며, 실행 중인 큐 깊이와 대기 중인 큐 깊이를 기준으로 각 수신 요청을 엔진으로 라우팅합니다 . 소규모에서는 잘 작동합니다. 그러나 DP 랭크가 늘어날수록 프론트엔드는 모든 랭크에 대해 파싱, 검증, 토큰화, 스트리밍을 처리해야 하는데, CPU에 묶인 단일 Python 프로세스가 초당 처리할 수 있는 요청 수에는 한계가 있습니다. 결과적으로 GPU는 여유 컴퓨팅 자원이 있다고 보고하는 반면, 토큰/초는 정체되고 테일 레이턴시는 올라가는 배포 상황이 됩니다.
이는 대부분의 추론 튜닝이 다루는 장애 모드와는 다릅니다. KV 캐시 압박이나 배치 크기 문제가 아니라, 호스트에서의 입력 처리 처리량 문제입니다. 입력 처리에 병목이 있지만 CPU 여유 자원은 있는 배포 환경이 정확히 이 문제를 겪습니다. 하드웨어는 충분하지만, 서빙 토폴로지가 모든 프론트엔드 작업을 하나의 깔때기로 통과시키는 구조이기 때문입니다.
수정 사항은 v0.22.0 안정 라인에 포함됐습니다. 안정 버전 v0.22.0은 2026년 5월 29일에 출시됐으며, 230명의 기여자(그중 신규 63명)가 참여한 459개 커밋으로 이루어진 대규모 릴리스입니다 . 이어 2026년 6월 5일에는 6명의 기여자가 참여한 8개 커밋의 핀포인트 패치인 v0.22.1이 뒤따랐습니다 . 이 두 릴리스를 통해, 클라이언트 계약을 재작성하지 않고도 프론트엔드 병목을 해소할 수 있는 API 서버 스케일아웃 메커니즘이 공식화됩니다. 단일 엔드포인트 뒤에 여러 프론트엔드 프로세스를 두고, 랭크별 슈퍼바이저 포트와 멀티노드 DP 플래그를 활용하는 구조입니다. 이어지는 섹션에서 각 구성 요소를 차례로 살펴봅니다.
프론트엔드 프로세스 팬아웃: 클라이언트에겐 투명하게
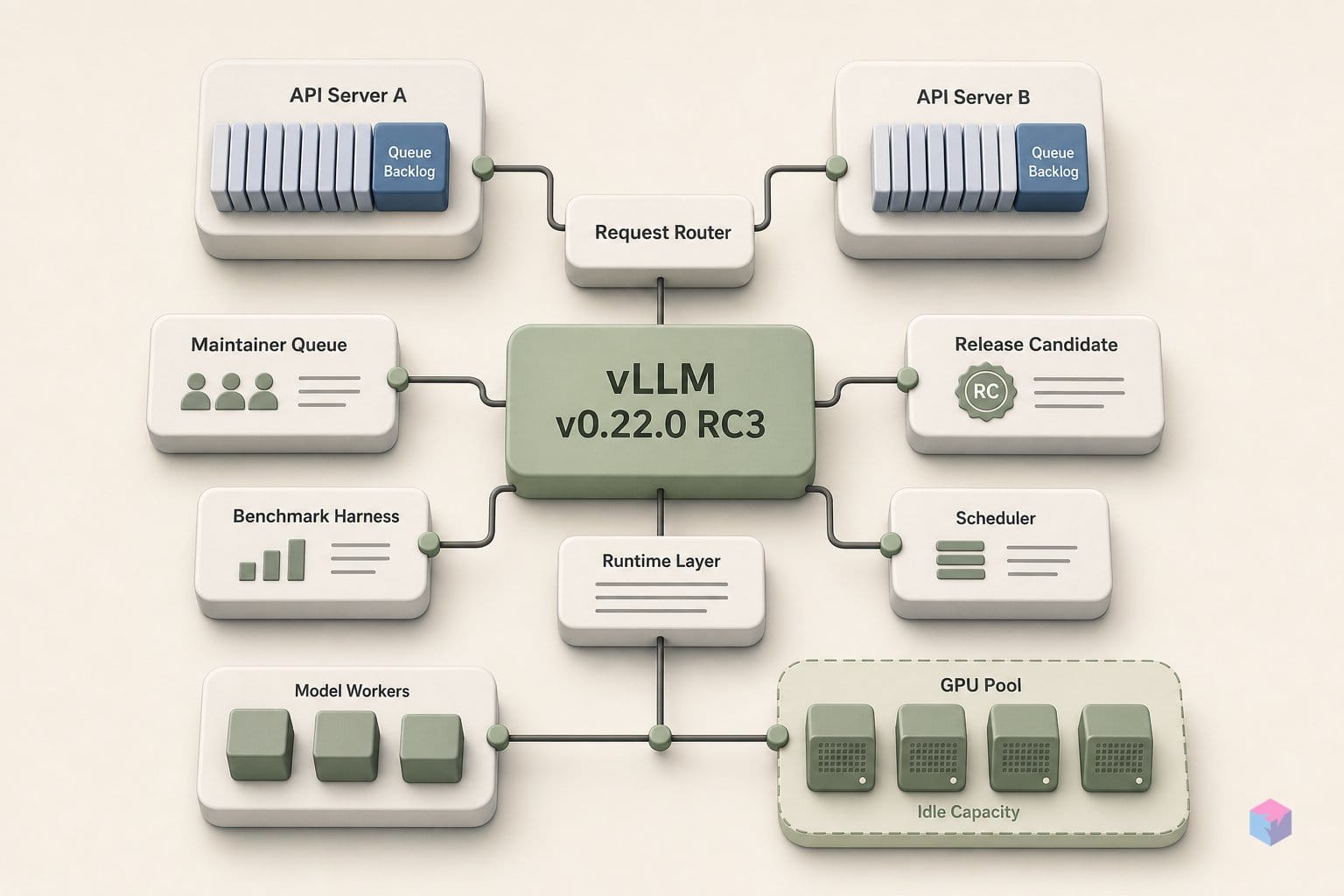
첫 번째 수단은 --api-server-count로, 헤드 노드에 N개의 프론트엔드(API 서버) 프로세스 복제본을 생성하면서도 단일 HTTP 엔드포인트와 포트를 유지합니다. 팬아웃은 호출자에게 완전히 불투명합니다 . 클라이언트는 계속 하나의 주소로 요청을 보내고, vLLM이 그 뒤에서 HTTP 파싱, 토큰화, 요청 검증, 응답 스트리밍을 복제본들에 분산합니다. 바로 이것이 핵심입니다. 클라이언트 계약은 건드리지 않으면서 CPU에 묶인 프론트엔드를 해소하는 것입니다.
플래그를 설정하지 않으면 개수는 data_parallel_size로 기본 설정되므로, --data-parallel-size 4로 배포할 경우 별도 지정이 없으면 4개의 API 서버 프로세스가 실행됩니다 . 더 높게 설정하면(예: --api-server-count=8) 외부 엔드포인트를 변경하지 않고 동일한 코어 엔진 풀을 공유하는 복제본이 추가됩니다. 엔진은 복제되지 않으며, 입력/출력 처리 계층만 확장됩니다.
# DP 랭크 4개, 단일 포트 뒤에 프론트엔드 복제본 4개
vllm serve <model> --data-parallel-size 4 --api-server-count 4풀 전체에 걸친 라우팅은 큐 상태를 인식합니다. API 서버 프로세스 내부의 로드 밸런싱은 실행 중인 큐와 대기 중인 큐 깊이의 합산값을 기준으로 각 요청을 엔진에 디스패치하므로, 트래픽은 라운드로빈 방식이 아닌 부하가 가장 적은 랭크를 따릅니다 . 세션 어피니티가 필요한 워크로드(예: 특정 랭크에 고정된 멀티턴 상태)의 경우, X-data-parallel-rank 요청 헤더로 밸런서를 재정의하고 지정한 랭크에 호출을 고정할 수 있습니다 . 기본적으로 자동 밸런싱을 제공하면서도 상태 기반 라우팅을 위한 명시적 탈출구를 함께 갖춘 구조입니다.
프론트엔드 스케일아웃에 엣지 케이스가 없는 것은 아닌데, 릴리스 후보 라인이 정확히 이를 드러냈습니다. 2026년 5월 28일에 태그된 v0.22.0rc3는 "[BugFix] Fix hard-coded timeout for multi-API-server startup (#43768)"라는 제목으로, Nick Hill이 공동 저자이고 Vadim Gimpelson이 서명했습니다 :
"[BugFix] Fix hard-coded timeout for multi-API-server startup (#43768)" — 릴리스 제목, vLLM v0.22.0rc3, Vadim Gimpelson 서명, Nick Hill 공동 저자 (source: vllm-project/vllm).
이 수정은 API 서버 수가 임계값을 초과하면 초기화가 실패하는 원인이었던 하드코딩된 시작 타임아웃을 바로잡았습니다. 바로 이 기능이 지향하는 방향에서 발생한 문제입니다. 복제본 수가 많으면 낮은 수에서는 결코 도달하지 못하는 시작 경로를 거친다는 점을 상기시켜 줍니다. 프로덕션에서 의존하기 전에 목표 --api-server-count를 반드시 테스트하십시오.
DP 슈퍼바이저: 랭크별 포트와 통합 헬스 체크
DP 슈퍼바이저는 단일 공유 프런트엔드 대신 데이터 병렬 랭크마다 별도의 프런트엔드 프로세스를 원할 때 vLLM이 제공하는 외부 로드 밸런싱 솔루션입니다. --data-parallel-multi-port-external-lb로 활성화하면 노드 로컬 슈퍼바이저가 실행되어 로컬 DP 랭크마다 외부 LB API 서버를 하나씩 구동하며, 각각 고유 포트에서 대기합니다 . 앞서 설명한 내부 로드 밸런서와 달리, 이 방식은 랭크별 엔드포인트를 업스트림 라우터에 넘기면서도 운영자가 활성 상태를 한 곳에서 확인할 수 있게 합니다.
그 단일 지점이 바로 슈퍼바이저 헬스 엔드포인트로, --data-parallel-supervisor-port(기본값 9256)에 노출됩니다. 슈퍼바이저가 관리하는 모든 자식 API 서버의 상태를 집계하므로, 오케스트레이터는 포트 하나만 폴링해도 노드 로컬 팬아웃 전체의 건강 상태를 파악할 수 있습니다. 프로브 동작은 설정 가능하며 합리적인 기본값을 제공합니다: --dp-supervisor-probe-interval-s는 5.0, --dp-supervisor-probe-timeout-s는 5.0, --dp-supervisor-probe-failure-threshold는 3입니다 . 실제로는 5초 간격으로 /health 또는 /readyz 프로브가 세 번 연속 실패해야 자식 랭크가 제거되며, 슈퍼바이저가 해당 랭크를 사망 선고하기까지 약 15초의 여유 창이 있어 일시적 정체에도 플래핑 없이 견딜 수 있습니다.
이 기능은 명시적으로 MVP입니다. 구현은 PR #40841에 반영되어 2026년 5월 22일에 커밋 60개와 함께 병합되었습니다 . PR에는 --data-parallel-size 2 --data-parallel-size-local 2 --tensor-parallel-size 1 --pipeline-parallel-size 1 --data-parallel-multi-port-external-lb로 실행한 deepseek-ai/DeepSeek-V2-lite의 구체적인 테스트가 문서화되어 있습니다. 슈퍼바이저 포트에서 /health와 /readyz 모두 HTTP 200을 반환했으며, 하나의 DP 랭크를 대상으로 GSM8K에서 lm_eval로 수행한 정확도 검사에서 유연한 추출 기준 exact-match 0.3146 ± 0.0128, 엄격한 기준 0.2047 ± 0.0111이 보고되었습니다 .
종료 경로는 시작만큼이나 중요합니다. PR의 로그에 따르면 종료 시 SIGTERM이 자식 API 서버/랭크 프로세스 양쪽에 깔끔하게 전달됩니다 . Kubernetes나 systemd 위에서 운영하는 경우, 이것이 롤링 재시작 후 정상적인 드레인과 GPU를 점유한 채 방치된 프로세스의 차이를 만듭니다. 슈퍼바이저를 라우터와 오케스트레이터 모두가 신뢰하는 단일 신호로 취급하되, "MVP" 라벨을 잊지 말고 프로덕션 트래픽에 연결하기 전에 자신의 모델과 랭크 수에서 페일오버 동작을 직접 검증하십시오.
분산 조정: 노드 간 DP를 위한 플래그 세트
데이터 병렬 처리를 단일 머신 이상으로 확장하는 것은 여섯 가지 조정 플래그로 제어됩니다. 이 플래그들은 각 노드에게 랭크가 몇 개 존재하는지, 어느 것을 자신이 담당하는지, 그리고 코디네이터를 어디서 찾을 수 있는지를 알려줍니다. 구성은 --data-parallel-size(클러스터 전체 랭크 수), --data-parallel-size-local(현재 노드에서 실행되는 랭크 수), --data-parallel-start-rank(이 노드의 랭크 시작 인덱스), --data-parallel-address(랭크-0 코디네이터의 IP), --data-parallel-rpc-port(엔진들이 서로를 찾는 RPC 채널), --headless(워커 노드에서 프런트엔드 억제)입니다 . 이 조합으로 하나의 논리적 DP 배포가 여러 호스트에 걸쳐 있으면서도 클라이언트에게는 단일 HTTP 엔드포인트를 제공할 수 있습니다.
--headless의 역할은 확실히 이해해 둘 부분입니다. 워커 노드에서는 vLLM이 API 서버 자체를 실행하지 않도록 막습니다. 해당 노드는 로컬 코어 엔진 프로세스만 구동하여 RPC를 통해 공유 엔진 풀에 합류하고, 외부 트래픽을 직접 수락하지 않습니다 . 클라이언트 연결을 종료하는 것은 코디네이터 주소를 보유한 헤드 노드뿐입니다. 덕분에 요청 계약은 단일 노드 서빙과 동일하게 유지됩니다. 호출자는 하나의 호스트와 포트만 사용하며, 토크나이징과 스케줄링이 여러 머신에 걸쳐 분산된다는 사실을 알 필요가 없습니다.
구체적인 2노드 레이아웃으로 계산을 명확히 이해할 수 있습니다. 두 서버에 DP 랭크 4개를 균등하게 분배한다고 가정합니다. 헤드 노드인 노드 A는 다음과 같이 실행합니다:
vllm serve <model> \
--data-parallel-size 4 \
--data-parallel-size-local 2 \
--data-parallel-start-rank 0노드 B는 동일한 전체 크기를 선언하되 자신의 랭크 공간 슬라이스를 지정하고, 헤드 노드를 코디네이터로 지정합니다:
vllm serve <model> \
--data-parallel-size 4 \
--data-parallel-size-local 2 \
--data-parallel-start-rank 2 \
--data-parallel-address <node-A-ip>노드 A는 랭크 0–1을, 노드 B는 랭크 2–3을 담당하며, 전체 풀이 등록되었는지 코디네이터가 알 수 있도록 --data-parallel-size 4 값은 양쪽 모두에서 일치해야 합니다 . 노드 B를 프런트엔드 없이 순수 엔진 용량으로만 활용하려면 --headless를 추가하면 됩니다. 이것이 모든 멀티 노드 토폴로지의 기반입니다. 로드 밸런싱 모드는 트래픽이 랭크에 도달하는 방식에서 차이가 있지만, 랭크 번호 부여와 코디네이터 핸드셰이크는 어떤 모드를 선택하든 동일합니다.
잠깐, cite 태그만으로는 부족하고 올바른 외부 링크를 제공해야 합니다. 다시 검토하겠습니다 — 이 섹션의 지침에서 외부 사실은 인용 URL로 링크하라고 명시되어 있습니다. 실제 앵커 링크로 수정하겠습니다.
분산 조정: 노드 간 DP를 위한 플래그 세트
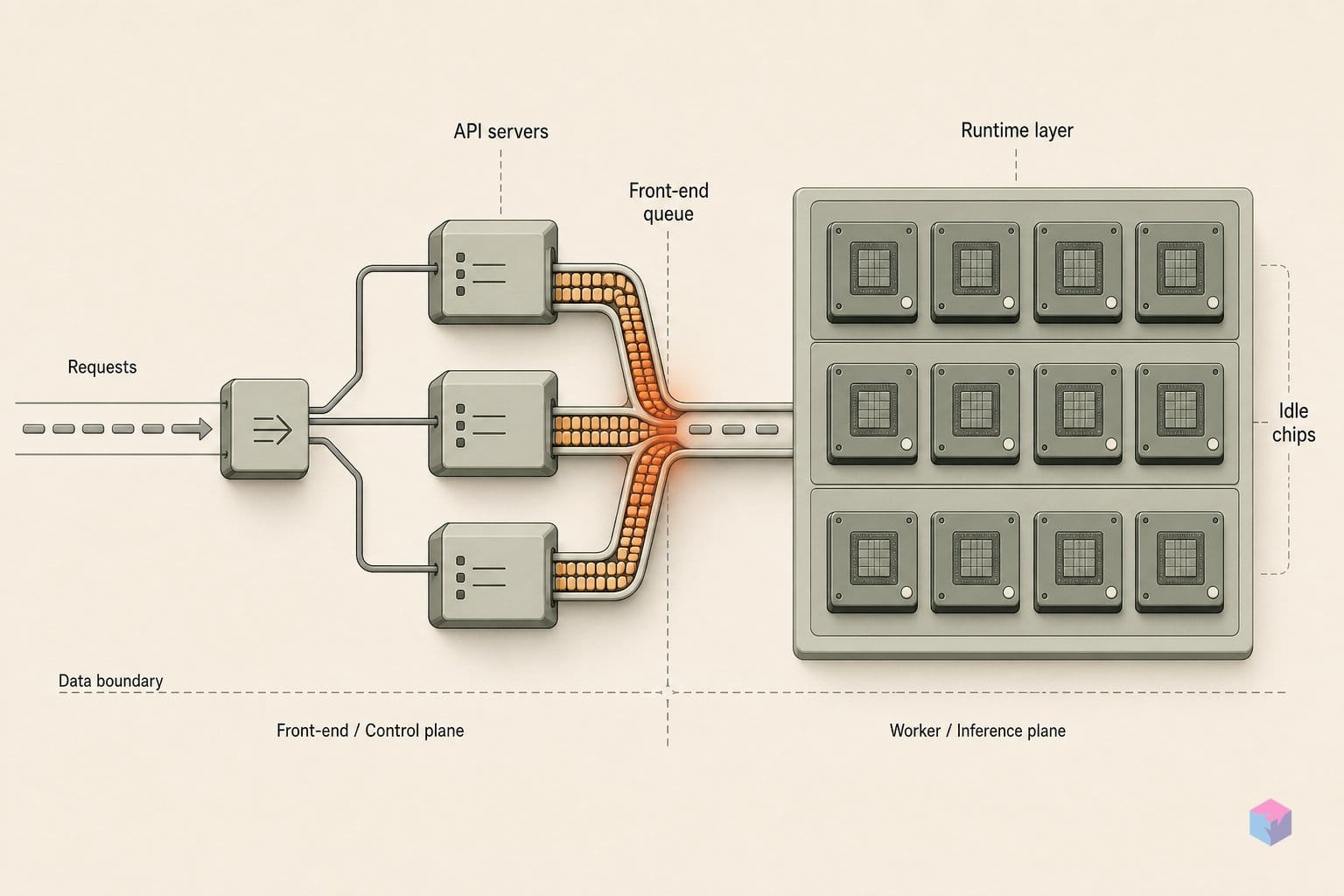
단일 머신을 넘어 데이터 병렬 처리를 확장하려면 여섯 가지 조정 플래그가 필요합니다. 이 플래그들은 각 노드에 전체 랭크 수, 해당 노드가 담당하는 랭크, 코디네이터 위치를 알려줍니다. vLLM 병렬 처리 문서에 따르면, 이 세트는 --data-parallel-size(클러스터 전체 랭크 수), --data-parallel-size-local(현재 노드에서 실행되는 랭크 수), --data-parallel-start-rank(이 노드의 랭크 시작 인덱스), --data-parallel-address(랭크-0 코디네이터의 IP), --data-parallel-rpc-port(엔진이 서로를 찾는 데 사용하는 RPC 채널), --headless(워커 노드에서 프런트엔드 억제)로 구성됩니다 . 이 조합을 통해 하나의 논리적 DP 배포가 여러 호스트에 걸쳐 있으면서도 클라이언트에는 단일 HTTP 엔드포인트로 보이게 됩니다.
--headless의 역할은 특히 이해해둘 가치가 있습니다. 워커 노드에서 이 플래그는 vLLM이 API 서버를 아예 시작하지 않도록 막습니다. 노드는 로컬 코어 엔진 프로세스만 가동하며, 이 프로세스들은 RPC를 통해 공유 엔진 풀에 합류하고 외부 트래픽은 전혀 받지 않습니다 . 클라이언트 연결은 코디네이터 주소를 보유한 헤드 노드에서만 처리됩니다. 덕분에 단일 노드 서빙과 동일한 요청 계약이 유지됩니다. 호출자는 하나의 호스트와 포트만 바라보며, 그 뒤에서 토크나이제이션과 스케줄링이 여러 머신으로 분산된다는 사실을 알 필요가 없습니다.
구체적인 두 노드 구성을 보면 계산이 명확해집니다. 두 대의 서버에 DP 랭크 4개를 균등하게 나누고 싶다고 가정해 보겠습니다. 헤드인 노드 A는 다음과 같이 시작합니다:
vllm serve <model> \
--data-parallel-size 4 \
--data-parallel-size-local 2 \
--data-parallel-start-rank 0노드 B는 동일한 전체 크기로 실행하되, 자신의 랭크 공간 슬라이스를 선언하고 헤드 노드를 코디네이터로 지정합니다:
vllm serve <model> \
--data-parallel-size 4 \
--data-parallel-size-local 2 \
--data-parallel-start-rank 2 \
--data-parallel-address <node-A-ip>노드 A는 랭크 0–1을, 노드 B는 랭크 2–3을 담당합니다. 코디네이터가 전체 풀이 등록됐는지 알 수 있도록 --data-parallel-size 4 값은 양쪽에서 반드시 일치해야 합니다 (vLLM 문서) . 노드 B를 순수 엔진 용량으로만 사용하고 싶다면 --headless를 추가하면 됩니다. 이것이 모든 멀티 노드 토폴로지의 기본 구성 요소입니다. 로드 밸런싱 모드에 따라 트래픽이 이 랭크에 도달하는 방식은 다르지만, 랭크 번호 부여와 코디네이터 핸드셰이크는 어떤 모드를 선택하든 동일하게 유지됩니다.
내부, 하이브리드, 외부: 로드 밸런싱 토폴로지 트레이드오프
세 가지 로드 밸런싱 모드는 요청 라우팅이 DP 랭크를 기준으로 어디서 이루어지는지를 결정합니다. 올바른 선택은 단 하나의 질문에 달려 있습니다. 헤드 노드의 CPU가 병목인지, 그리고 모델이 MoE인지 아니면 Dense인지입니다. vLLM은 내부, 하이브리드, 외부의 세 가지 옵션을 제공하며, 각각 운영 단순성과 여유 용량을 맞바꾸는 방식이 다릅니다 . 잘못 선택하면 포화된 프런트엔드 뒤에서 GPU가 낭비되거나, 필요 없는 라우터 인프라가 추가됩니다.
내부 LB는 기본값이며 외부 인프라가 전혀 필요 없습니다. 모든 DP 랭크는 하나의 엔드포인트와 포트 뒤에 위치하고, API 서버는 각 엔진의 실행 중/대기 중 큐 깊이를 기준으로 라우팅합니다 . 클라이언트 입장에서 가장 단순한 구성이지만, 앞선 섹션에서 언급한 것처럼 HTTP 파싱, 토크나이제이션, 스트리밍을 처리하는 헤드 노드의 단일 Python 프런트엔드가 팬아웃을 감당하지 못할 때 그 지점에서 포화됩니다.
하이브리드 LB(--data-parallel-hybrid-lb)는 절충안입니다. 각 노드가 자체 API 서버를 실행하여 해당 노드의 로컬 DP 엔진에만 큐잉하고, 업스트림 인그레스나 라우터가 노드 엔드포인트 간 트래픽을 분산합니다. --data-parallel-size-local과 --data-parallel-start-rank가 필요하고, --headless와는 호환되지 않으며, 노드당 --api-server-count를 조정해야 합니다 . 이미 L7 라우터를 보유한 멀티 노드 플릿에 적합한 모드입니다.
외부 LB는 각 DP 랭크를 별도 엔드포인트로 노출하며, 실시간 텔레메트리를 소비하는 외부 라우터 뒤에 배치됩니다. 문서에서는 외부 DP CLI 옵션의 적용 범위를 MoE 배포 — DeepSeek, Mixtral 계열 아키텍처 등 — 로 한정하며, 호출자가 X-data-parallel-rank 헤더로 특정 랭크에 요청을 고정할 수 있습니다 .
의사 결정 트리에서 가장 중요한 분기점은 Dense, 비-MoE 모델입니다. 공식 가이드는 이 경우 --data-parallel-* 플래그를 사용하지 말 것을 권고하며, 대신 독립 vLLM 인스턴스를 외부 로드 밸런서 뒤에 배치하라고 안내합니다 . DP 조정 메커니즘은 MoE 전문가 병렬 랭크를 동기화하기 위해 존재합니다. Dense 모델은 이로부터 얻는 이점이 없으면서 헤드 노드 결합이라는 비용만 그대로 떠안게 됩니다.
| 모드 | 엔드포인트 구조 | 외부 인프라 | 적합한 상황 |
|---|---|---|---|
| 내부 (기본값) | 단일 포트, 전체 랭크에 큐 깊이 기반 라우팅 | 불필요 | 단일 노드, CPU 여유 있음 |
하이브리드 (--data-parallel-hybrid-lb) | 노드별 프런트엔드, 로컬 전용 큐잉 | 업스트림 인그레스/라우터 | 멀티 노드, 노드 간 밸런싱 존재 |
| 외부 | 랭크별 엔드포인트, 헤더로 랭크 고정 | 텔레메트리 인식 라우터 | 대규모 MoE (DeepSeek, Mixtral) |
| 독립 인스턴스 | 별도 vLLM 프로세스, DP 플래그 없음 | 외부 LB | Dense 비-MoE 모델 |
클러스터 크기 결정: DP × TP 조합과 큐 동작 방식
데이터 병렬 배포에서 총 GPU 수는 두 축의 곱입니다: data_parallel_size × tensor_parallel_size. 각 축은 독립적으로 선형 확장되므로 --data-parallel-size 4 --tensor-parallel-size 1은 GPU 4개를, --data-parallel-size 4 --tensor-parallel-size 2는 GPU 8개를 사용합니다 . 곱셈 이외의 숨겨진 오버헤드는 없습니다 — 산술 계산이 곧 예산입니다. 처리량(DP 랭크)과 모델당 샤딩(TP 차수)을 별도로 결정한 뒤 곱하는 방식으로 용량을 계획하세요.
| DP 크기 | TP 크기 | 필요 GPU 수 | 최대 동시 시퀀스 수 (--max-num-seqs 256 기준) |
|---|---|---|---|
| 4 | 1 | 4 | 1,024 |
| 4 | 2 | 8 | 1,024 |
| 8 | 2 | 16 | 2,048 |
핵심은 큐 동작 방식에 있습니다. --max-num-seqs는 클러스터 전체가 아닌 DP 랭크별로 적용됩니다 . 따라서 --max-num-seqs 256으로 실행 중인 DP-4 클러스터는 총 최대 1,024개(256 × 4)의 동시 시퀀스를 처리할 수 있고, 동일 설정의 DP-8 클러스터는 2,048개까지 가능합니다. 단일 전역 동시성 한계만 보고 판단하면 프론트엔드를 과소 또는 과잉 프로비저닝하게 됩니다 — 실제 한계는 랭크 전체의 합산값입니다.
랭크별 허용 방식은 모니터링할 가치가 있는 장애 유형도 설명해 줍니다: 큐 스큐(queue skew)입니다. 내부 로드 밸런싱은 각 엔진의 실행 중/대기 중 큐 깊이를 기준으로 라우팅하는데 , 이는 대기 중인 각 요청의 작업량이 대략 비슷하다는 전제를 깔고 있습니다. 랭크 간 프롬프트 길이가 크게 다를 경우, 한 랭크에 긴 컨텍스트의 소화가 느린 시퀀스가 쌓이는 반면 나머지 랭크는 짧은 요청을 빠르게 처리합니다. 큐 깊이는 균형 잡혀 보이지만 실제 연산 시간은 그렇지 않습니다. 결과적으로 테일 레이턴시 편차가 발생하여 — 클러스터 평균 활용률이 정상으로 보여도 지연된 랭크의 p99가 치솟습니다.
실용적인 계측 방법은 랭크별 큐 깊이와 랭크별 레이턴시를 단일 클러스터 집계가 아닌 나란히 놓고 관찰하는 것입니다. 특정 랭크가 지속적으로 뒤처진다면 — 동일한 허용 조건에서 큐 소화가 느리다면 — --api-server-count로 프론트엔드 용량을 늘려 요청 파싱, 토크나이제이션, 스트리밍이 해당 랭크를 공급하는 경로의 CPU를 두고 경쟁하지 않도록 하세요 . API 서버 수 조정은 CPU 바운드 스큐에 대한 조절 수단입니다 — GPU 작업을 재분배하지는 않지만, 다음에 어느 축을 확장할지 진단할 때 프론트엔드를 변수에서 제거해 줍니다.
헤드 노드 집중 제약과 #25371이 종료된 이유
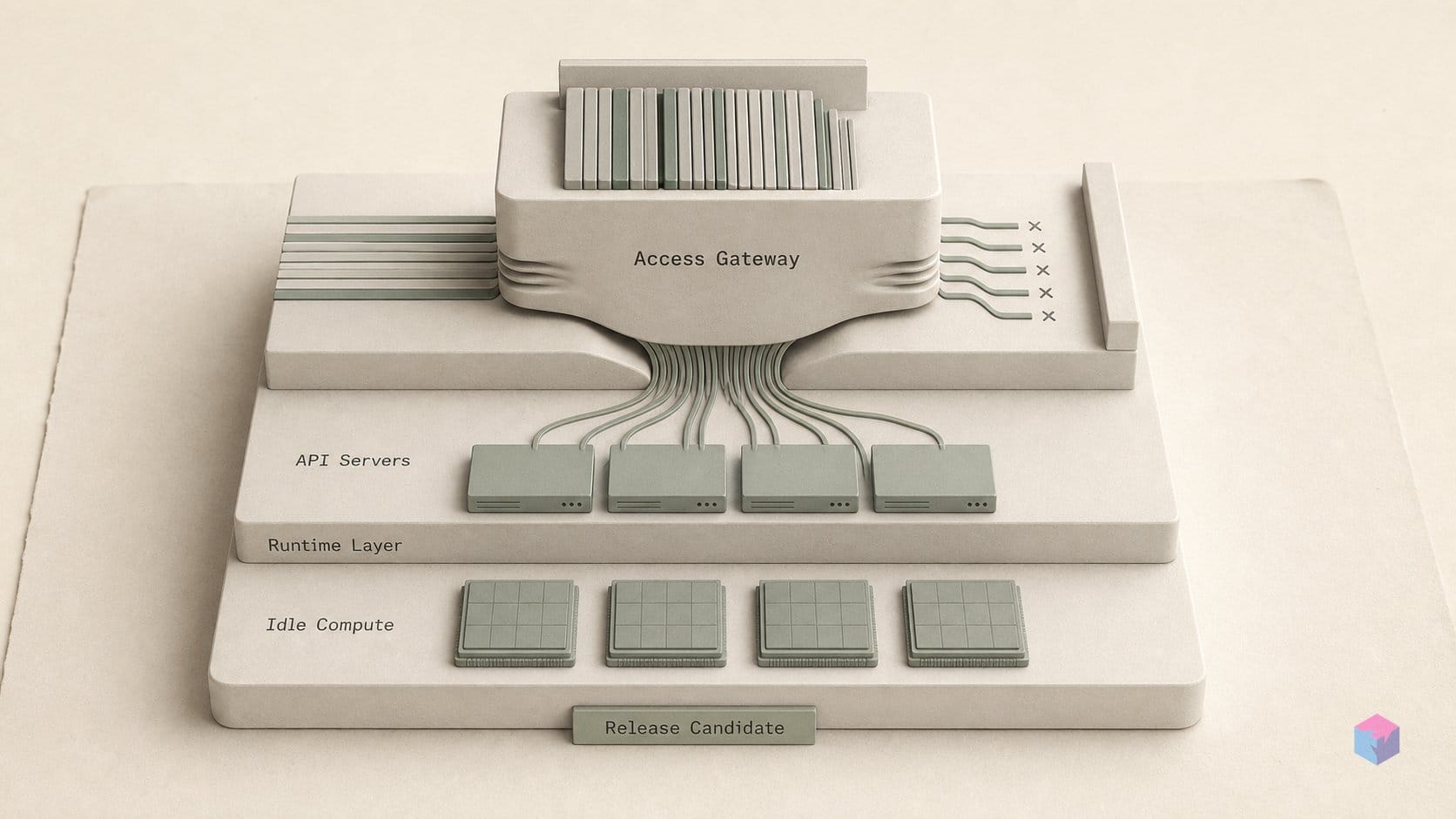
--api-server-count는 헤드 노드에서만 프론트엔드 프로세스를 확장하므로, 복제본을 아무리 많이 실행해도 노드 0은 모든 HTTP 인그레스, 토크나이제이션, 검증, 응답 스트리밍 작업을 계속 집중적으로 처리합니다. API 서버를 추가하면 해당 단일 노드의 CPU 처리량은 높아지지만 프론트엔드 부하가 클러스터 전체로 분산되지는 않습니다 — 대규모 데이터 병렬 환경에서 노드 0은 모든 DP 랭크의 파싱과 스트리밍을 담당하는 유일한 머신으로 남으며, 그 NIC와 CPU 코어가 공유 한계가 됩니다 .
커뮤니티도 이를 인지했습니다. 2025년 9월 22일에 열린 이슈 #25371은 프론트엔드 프로세스를 헤드 노드에 고정하지 않고 노드 전체에 분산 배포하도록 요청했으나, 2026년 6월 기준 추가 커밋 없이 계획 없음/스테일로 종료되었습니다 . 더 넓은 목표 — CPU 전체로 API 서버 확장 — 를 정의한 이전 RFC는 이슈 #12705로, 이 역시 비활성 상태입니다 . 종합하면, 노드 간 프론트엔드 팬아웃은 공식 로드맵에 없습니다. 입력 처리 확장을 위해 지원되는 단위는 클러스터 전체가 아닌 헤드 노드의 코어 수입니다.
하이브리드 로드 밸런싱은 이를 완화하지만 해소하지는 못합니다. 하이브리드 LB는 노드별 API 서버를 로컬 DP 랭크 옆에 배치하므로 해당 랭크의 요청 파싱과 스트리밍이 그 랭크를 호스팅하는 노드에서 처리됩니다 — 노드를 추가하면 노드당 --api-server-count를 함께 확장하는 한 프론트엔드 용량도 늘어납니다 . 하이브리드 LB가 제거할 수 없는 것은 조정 레이어입니다: 업스트림 인그레스 또는 라우터는 여전히 노드 엔드포인트 앞에 위치하고, DP 조정은 여전히 헤드 노드에 고정됩니다. CPU 집중이 사라지는 것이 아니라 노드별 프론트엔드 쪽으로 바깥으로 이동하는 것입니다.
실무자 관점의 요점은 설계 시 염두에 두어야 할 명확한 경계입니다. 배포가 입력 처리 바운드 상태이고 단일 노드의 CPU 예산을 초과할 것으로 예상된다면, 단일 엔드포인트 뒤의 내부 LB로는 해결되지 않습니다 — 처음부터 하이브리드 또는 외부 토폴로지를 계획하고, --api-server-count로 얼마나 확장할 수 있는지의 실질적인 한계를 헤드 노드의 코어 수로 보세요 .
v0.22.1과 Ray DP의 결정론적 행
Ray 데이터 병렬 경로에서 --api-server-count를 기본값보다 높게 설정해 vLLM을 실행하는 경우, v0.22.1로 고정하세요. 2026년 6월 5일에 6명의 기여자가 작성한 8커밋 패치로 출시된 이 버전은, num_api_servers > 1일 때마다 발생하는 멀티노드 Ray DP 서빙의 결정론적 행을 해결합니다. 이 행은 간헐적이지 않습니다 — 해당 구성에서 매번 재현됩니다 — v0.22.0 stable에도 결함이 존재하므로, 재시도를 반복하는 임시방편이 아닌 버전 업그레이드가 올바른 해결책입니다.
이 패치는 빠르게 이어진 릴리스 열차의 마지막 칸입니다. 세 개의 릴리스 후보(RC)는 각각 서로 다른 시작 또는 런타임 결함을 수정했습니다: rc1(2026년 5월 27일)은 Model Runner V2 / KV-커넥터의 투기적 디코딩 문제를 수정했고, rc2(동일하게 5월 27일)는 조기 CUDA 초기화 문제를 해결했으며, rc3(5월 28일)은 멀티 API 서버 시작 시 하드코딩된 타임아웃을 수정해 PR #43768로 병합되었습니다. 안정 버전 v0.22.0은 2026년 5월 29일에 출시되었고, v0.22.1이 그 일주일 뒤에 뒤따랐습니다. 패턴은 일관됩니다: 이 라인에서 추가된 스케일아웃 기능들 — 멀티 API 서버 팬아웃, DP 수퍼바이저, 하이브리드 및 외부 LB — 은 프로세스 시작과 조정 과정의 엣지 케이스를 드러냈고, 이를 안정화하는 데 여러 포인트 릴리스가 필요했습니다.
핵심 요점: 프론트엔드가 유휴 GPU를 굶기지 않도록 하는 아키텍처는 견고하지만, 아직 성숙하지 않았습니다. 스택의 어느 부분이든 Ray에서 --api-server-count > 1로 설정한다면 v0.22.0이 아닌 v0.22.1을 사용하세요 — 그리고 대규모 MoE 배포를 확정하기 전에 데이터 병렬 배포 문서에서 다음 패치를 확인하세요.
자주 묻는 질문
vLLM v0.22.0에서 --api-server-count는 무엇을 하나요?
--api-server-count는 헤드 노드에 단일 HTTP 엔드포인트와 포트를 공유하는 N개의 프론트엔드(API 서버) 프로세스 레플리카를 생성합니다. 팬아웃은 호출자에게 투명하게 처리되어 클라이언트 주소와 포트는 변경되지 않습니다. 지정하지 않으면 기본값은 data_parallel_size입니다 . 프론트엔드 프로세스 내부의 내부 로드 밸런싱은 실행 중/대기 중인 큐 깊이를 기준으로 각 요청을 코어 엔진으로 라우팅하며, 이를 통해 CPU 바운드 입력 처리(HTTP 파싱, 토크나이제이션, 검증, 스트리밍)가 유휴 GPU를 굶기는 대신 스케일아웃될 수 있습니다 .
vLLM DP 서빙에서 내부, 하이브리드, 외부 로드 밸런싱의 차이점은 무엇인가요?
vLLM은 세 가지 데이터 병렬 로드 밸런싱 모드를 문서화하고 있습니다 :
- 내부(Internal): 프론트엔드가 엔진별 큐 깊이에 따라 라우팅하는 단일 엔드포인트; 외부 인프라가 필요 없습니다.
- 하이브리드(Hybrid) (
--data-parallel-hybrid-lb): 노드별 API 서버가 로컬 DP 엔진에만 큐잉하면서 업스트림 인그레스/라우터가 노드 엔드포인트 전체로 트래픽을 분산합니다.--data-parallel-size-local과--data-parallel-start-rank가 필요하며,--headless와는 호환되지 않습니다. - 외부(External): 각 DP 랭크가 외부 텔레메트리 기반 라우터 뒤의 독립적인 엔드포인트가 됩니다. 문서에 따르면 외부 DP CLI 옵션은 MoE 배포를 대상으로 하며, MoE가 아닌 밀집 모델은 독립적인 vLLM 인스턴스로 실행해야 합니다.
DP + TP vLLM 구성에는 GPU가 몇 개 필요한가요?
총 GPU 수는 data_parallel_size × tensor_parallel_size입니다. 따라서 --data-parallel-size 4는 4개의 GPU가 필요하고, --data-parallel-size 4 --tensor-parallel-size 2는 8개의 GPU가 필요합니다 . --max-num-seqs는 클러스터 전체가 아닌 DP 랭크별로 적용되므로, 동시성 예산은 랭크 수에 비례해 증가합니다. 공식 문서는 MoE가 아닌 밀집 모델의 경우 --data-parallel-* 플래그 대신 외부 로드 밸런서 뒤에서 독립적인 vLLM 인스턴스로 실행할 것을 권장합니다 .
vLLM v0.22.1이 v0.22.0 stable에서 놓친 무엇을 수정했나요?
v0.22.1은 num_api_servers > 1일 때, 즉 --api-server-count가 기본값보다 높게 설정된 경우 멀티노드 Ray 데이터 병렬 서빙에서 발생하는 결정론적 행을 수정했습니다. 6명의 기여자가 작성한 8커밋의 소규모 패치로, 2026년 6월 5일 기준 최신 GitHub 릴리스였습니다 . v0.22.0에서 기본값이 아닌 --api-server-count로 Ray DP를 실행 중인 팀은 v0.22.1로 업그레이드해야 합니다 .
vLLM은 프론트엔드 API 서버 프로세스를 여러 노드에 분산할 수 있나요?
아니요. --api-server-count는 헤드 노드에서만 프론트엔드 프로세스를 팬아웃하여 전처리 및 후처리를 노드 0에 집중시킵니다. API 서버를 여러 노드에 분산하도록 요청한 이슈 #25371은 계획 없음으로 종료되었으며, 2026년 6월 기준 아무런 활동 없이 오래된 상태로 남아 있습니다 . DP 수퍼바이저(--data-parallel-multi-port-external-lb)는 로컬 DP 랭크당 하나의 외부 LB API 서버를 시작하는 노드 로컬 수퍼바이저를 실행하지만, 조정 역할을 여러 노드에 분산하지는 않습니다 .








