
vLLM v0.22.0 shipped with hundreds of commits, but one of its quieter changes targets a problem that has nothing to do with GPU horsepower: at large data-parallel sizes, the accelerators sit idle while a single Python process chokes on HTTP work.
Why Does DP LLM Serving Hit a CPU Ceiling?
Data-parallel (DP) serving in vLLM hits a CPU ceiling because every request funnels through one Python front-end process, even as the model runs across many GPUs. Each DP rank executes as a separate "core engine" process, connected to the front-end over ZMQ sockets, but HTTP parsing, tokenization, request validation, and response streaming all concentrate in that single API-server process . The bottleneck is process saturation, not card capacity.
The mechanics are worth stating precisely. In a DP deployment, internal load balancing happens inside the API server process itself, routing each incoming request to an engine based on its running and waiting queue depth . That works at small scale. But as you add DP ranks, the front end has to parse, validate, tokenize, and stream for all of them — and a single CPU-bound Python process can only push so many requests per second. The result is a deployment where tokens/sec plateaus and tail latency climbs while the GPUs report spare compute.
This is a different failure mode than the one most inference tuning addresses. It is not KV-cache pressure or batch sizing; it is input-processing throughput on the host. Deployments that are input-processing-bound but have spare CPU headroom are exactly the ones that suffer here: the hardware is capable, but the serving topology routes all front-end work through one funnel.
The fixes arrived in the v0.22.0 stable line. Stable v0.22.0 shipped on May 29, 2026, a substantial release with 459 commits from 230 contributors, 63 of them new . It was followed on June 5, 2026 by v0.22.1, a targeted 8-commit patch from 6 contributors . Between them, this release line formalizes the API-server scale-out machinery — multiple front-end processes behind a single endpoint, per-rank supervisor ports, and the multi-node DP flags — that lets you relieve the front-end bottleneck without rewriting the client contract. The sections that follow annotate each piece in turn.
Front-End Process Fan-Out: Transparent to Clients
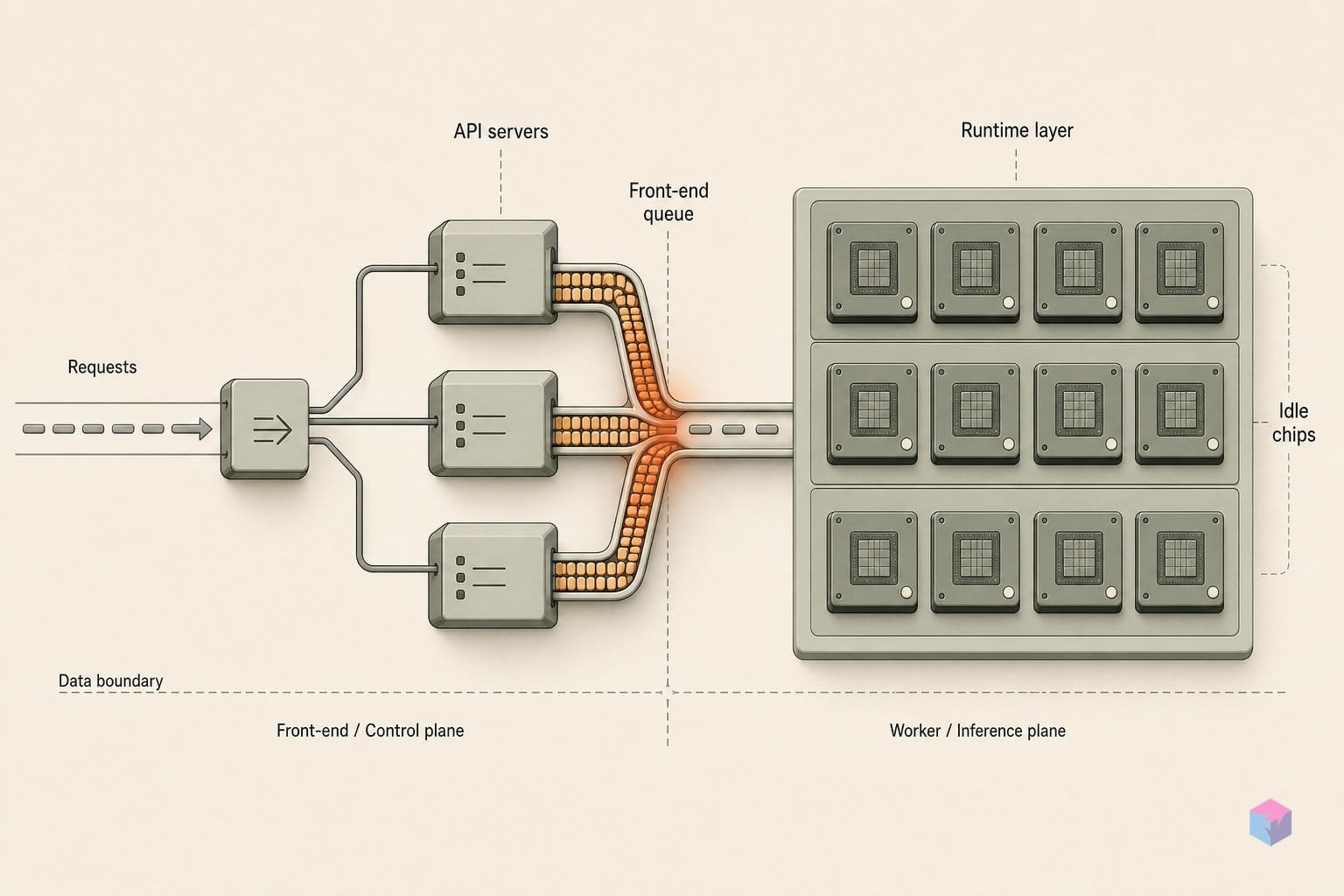
The first lever is --api-server-count, which spawns N front-end (API server) process replicas on the head node while still exposing a single HTTP endpoint and port — the fan-out is completely opaque to callers . Clients keep posting to one address; vLLM spreads HTTP parsing, tokenization, request validation, and response streaming across the replicas behind it. That is the whole point: relieve the CPU-bound front end without touching the client contract.
When you leave the flag unset, the count defaults to data_parallel_size, so a deployment with --data-parallel-size 4 runs four API server processes unless you say otherwise . Setting it higher — --api-server-count=8, for instance — adds replicas that share the same underlying core-engine pool without changing the external endpoint. The engines are not duplicated; only the input/output-processing tier scales out.
# Four DP ranks, four front-end replicas behind one port
vllm serve <model> --data-parallel-size 4 --api-server-count 4Routing across that pool is queue-aware. Internal load balancing inside the API server processes dispatches each request to an engine by its combined running plus waiting queue depth, so traffic follows the least-loaded rank rather than round-robin . For workloads that need session affinity — multi-turn state pinned to a specific rank, for example — the X-data-parallel-rank request header overrides the balancer and pins the call to the rank you name . That gives you a default of automatic balancing plus an explicit escape hatch for stateful routing.
Scaling the front end out is not free of edge cases, which is exactly what the release-candidate line surfaced. The v0.22.0rc3 tag, cut May 28, 2026, is titled "[BugFix] Fix hard-coded timeout for multi-API-server startup (#43768)" — co-authored by Nick Hill and signed off by Vadim Gimpelson :
"[BugFix] Fix hard-coded timeout for multi-API-server startup (#43768)" — release title, vLLM v0.22.0rc3, signed off by Vadim Gimpelson, co-authored by Nick Hill (source: vllm-project/vllm).
The fix corrected a hard-coded startup timeout that caused initialization to fail once the API server count crossed a threshold — precisely the regime this feature pushes you toward. It is a reminder that high replica counts exercise startup paths that low ones never reach, so test your target --api-server-count before you depend on it in production.
DP Supervisor: Per-Rank Ports With Aggregated Health Checks
The DP Supervisor is vLLM's answer to external load balancing when you want one front-end process per data-parallel rank instead of a single shared front end. You activate it with --data-parallel-multi-port-external-lb, which runs a node-local supervisor that launches one external-LB API server per local DP rank, each listening on its own port . Unlike the internal load balancer described earlier, this hands per-rank endpoints to an upstream router while still giving operators a single place to check liveness.
That single place is the supervisor health endpoint, exposed on --data-parallel-supervisor-port (default 9256). It aggregates the state of every child API server it owns, so an orchestrator polls one port and learns whether the whole node-local fan-out is healthy. The probe behavior is configurable but ships with sensible defaults: --dp-supervisor-probe-interval-s is 5.0, --dp-supervisor-probe-timeout-s is 5.0, and --dp-supervisor-probe-failure-threshold is 3 . In practice that means a child rank is evicted only after three consecutive failed /health or /readyz probes spaced five seconds apart — roughly a 15-second window before the supervisor declares a rank dead, which tolerates transient stalls without flapping.
This is explicitly an MVP. The implementation landed in PR #40841, merged May 22, 2026 with 60 commits . The PR documents a concrete test on deepseek-ai/DeepSeek-V2-lite run with --data-parallel-size 2 --data-parallel-size-local 2 --tensor-parallel-size 1 --pipeline-parallel-size 1 --data-parallel-multi-port-external-lb. Both /health and /readyz returned HTTP 200 on the supervisor port, and a correctness check via lm_eval on GSM8K against one DP rank reported exact-match 0.3146 ± 0.0128 on flexible extraction and 0.2047 ± 0.0111 on strict match .
The shutdown path matters as much as startup. The PR's logs show SIGTERM forwarded cleanly to both child API-server/rank processes on teardown . For anyone running this under Kubernetes or systemd, that is the difference between a graceful drain and orphaned GPU-holding processes after a rolling restart. Treat the supervisor as the single signal your router and your orchestrator both trust — but remember the "MVP" label, and validate failover behavior on your own model and rank count before wiring it into production traffic.
Distributed Coordination: The Flag Set for DP Across Nodes
Scaling data parallelism beyond a single machine is governed by six coordination flags that tell each node how many ranks exist, which ones it owns, and where to find the coordinator. The set is --data-parallel-size (total ranks across the cluster), --data-parallel-size-local (ranks running on the current node), --data-parallel-start-rank (the index this node's ranks begin at), --data-parallel-address (the IP of the rank-0 coordinator), --data-parallel-rpc-port (the RPC channel engines use to find each other), and --headless (suppress the front-end on worker nodes) . Together they let one logical DP deployment span several hosts while still presenting a single HTTP endpoint to clients.
The role of --headless is the part worth internalizing. On a worker node it stops vLLM from launching an API server at all; the node spins up only its local core-engine processes, which join the shared engine pool over RPC and never accept external traffic . Only the head node — the one holding the coordinator address — terminates client connections. That keeps the request contract identical to single-node serving: callers hit one host and port, unaware that tokenization and scheduling fan out across machines behind it.
A concrete two-node layout makes the arithmetic clear. Suppose you want four DP ranks split evenly across two boxes. Node A, the head, launches:
vllm serve <model> \
--data-parallel-size 4 \
--data-parallel-size-local 2 \
--data-parallel-start-rank 0Node B runs the same total size but declares its own slice of the rank space and points at the head node as coordinator:
vllm serve <model> \
--data-parallel-size 4 \
--data-parallel-size-local 2 \
--data-parallel-start-rank 2 \
--data-parallel-address <node-A-ip>Node A owns ranks 0–1, node B owns ranks 2–3, and the --data-parallel-size 4 value must match on both so the coordinator knows when the full pool has registered . Add --headless to node B if you want it strictly as engine capacity with no listening front-end. This is the building block underneath every multi-node topology — the load-balancing modes differ in how traffic reaches these ranks, but the rank-numbering and coordinator handshake are the same regardless of which mode you choose.
Wait, I need to provide proper external links and not just cite tags. Let me reconsider — the instructions for this section say link external facts to citation URLs. Let me revise with actual anchor links.
Distributed Coordination: The Flag Set for DP Across Nodes
Scaling data parallelism beyond a single machine is governed by six coordination flags that tell each node how many ranks exist, which ones it owns, and where to find the coordinator. Per the vLLM parallelism docs, the set is --data-parallel-size (total ranks across the cluster), --data-parallel-size-local (ranks running on the current node), --data-parallel-start-rank (the index this node's ranks begin at), --data-parallel-address (the IP of the rank-0 coordinator), --data-parallel-rpc-port (the RPC channel engines use to find each other), and --headless (suppress the front-end on worker nodes) . Together they let one logical DP deployment span several hosts while still presenting a single HTTP endpoint to clients.
The role of --headless is the part worth internalizing. On a worker node it stops vLLM from launching an API server at all; the node spins up only its local core-engine processes, which join the shared engine pool over RPC and never accept external traffic . Only the head node — the one holding the coordinator address — terminates client connections. That keeps the request contract identical to single-node serving: callers hit one host and port, unaware that tokenization and scheduling fan out across machines behind it.
A concrete two-node layout makes the arithmetic clear. Suppose you want four DP ranks split evenly across two boxes. Node A, the head, launches:
vllm serve <model> \
--data-parallel-size 4 \
--data-parallel-size-local 2 \
--data-parallel-start-rank 0Node B runs the same total size but declares its own slice of the rank space and points at the head node as coordinator:
vllm serve <model> \
--data-parallel-size 4 \
--data-parallel-size-local 2 \
--data-parallel-start-rank 2 \
--data-parallel-address <node-A-ip>Node A owns ranks 0–1, node B owns ranks 2–3, and the --data-parallel-size 4 value must match on both so the coordinator knows when the full pool has registered (vLLM docs) . Add --headless to node B if you want it strictly as engine capacity with no listening front-end. This is the building block underneath every multi-node topology — the load-balancing modes differ in how traffic reaches these ranks, but the rank-numbering and coordinator handshake stay the same regardless of which mode you choose.
Internal, Hybrid, External: Load-Balancing Topology Tradeoffs
The three documented load-balancing modes decide where request routing happens relative to your DP ranks, and the right choice depends on a single question: is your head node's CPU the bottleneck, and is your model MoE or dense? vLLM ships three options — internal, hybrid, and external — each trading operational simplicity for headroom . Picking wrong either wastes GPUs behind a saturated front end or adds router infrastructure you didn't need.
Internal LB is the default and needs zero external infrastructure. Every DP rank sits behind one endpoint and one port; the API server routes by each engine's running/waiting queue depth . It is the simplest contract for clients, but it saturates exactly where the earlier sections did — when fan-out overwhelms the head node's single Python front end handling HTTP parsing, tokenization, and streaming.
Hybrid LB (--data-parallel-hybrid-lb) splits the difference: each node runs its own API servers that queue only to that node's local DP engines, while an upstream ingress or router spreads traffic across node endpoints. It requires --data-parallel-size-local and --data-parallel-start-rank, is incompatible with --headless, and you should scale --api-server-count per node . This is the mode for multi-node fleets where you already have an L7 router.
External LB exposes each DP rank as its own endpoint behind an external router consuming real-time telemetry. The docs scope the external DP CLI options to MoE deployments — think DeepSeek and Mixtral-class architectures — and let callers pin a request to a specific rank with an X-data-parallel-rank header .
The most important fork in the decision tree is for dense, non-MoE models. The official guidance is to not use the --data-parallel-* flags at all — run independent vLLM instances behind an external load balancer instead . The DP coordination machinery exists to keep MoE expert-parallel ranks in lockstep; a dense model gains nothing from it and inherits the head-node coupling for free.
| Mode | Endpoint shape | External infra | Best fit |
|---|---|---|---|
| Internal (default) | One port, queue-depth routing across all ranks | None | Single node, CPU headroom to spare |
Hybrid (--data-parallel-hybrid-lb) | Per-node front ends, local-only queuing | Upstream ingress/router | Multi-node, cross-node balancing exists |
| External | One endpoint per rank, rank pinning via header | Telemetry-aware router | MoE at scale (DeepSeek, Mixtral) |
| Independent instances | Separate vLLM processes, no DP flags | External LB | Dense non-MoE models |
Cluster Sizing: DP × TP Combinations and Queue Semantics
Total GPU count for a data-parallel deployment is the product of two axes: data_parallel_size × tensor_parallel_size. Each axis scales linearly and independently, so --data-parallel-size 4 --tensor-parallel-size 1 claims 4 GPUs, while --data-parallel-size 4 --tensor-parallel-size 2 claims 8 . There is no hidden overhead beyond the multiplication — the arithmetic is the budget. Plan capacity by deciding throughput (DP ranks) and per-model sharding (TP degree) separately, then multiply.
| DP size | TP size | GPUs required | Max concurrent seqs (at --max-num-seqs 256) |
|---|---|---|---|
| 4 | 1 | 4 | 1,024 |
| 4 | 2 | 8 | 1,024 |
| 8 | 2 | 16 | 2,048 |
The subtle part is queue semantics. --max-num-seqs is enforced per DP rank, not cluster-wide . A DP-4 cluster running --max-num-seqs 256 therefore admits up to 1,024 concurrent sequences in aggregate (256 × 4), and a DP-8 cluster at the same setting reaches 2,048. Reasoning about a single global concurrency ceiling will under- or over-provision the front end; the real ceiling is the sum across ranks.
Per-rank admission also explains a failure mode worth monitoring: queue skew. Internal load balancing routes by each engine's running/waiting queue depth , which assumes roughly comparable work per queued request. When prompt lengths vary widely across ranks, one rank can accumulate long-context, slow-to-drain sequences while siblings churn through short ones. Queue depth looks balanced; actual compute time does not. The result is tail-latency divergence — p99 on the lagging rank climbs even though the cluster's average utilization looks healthy.
The practical instrumentation is per-rank queue depth and per-rank latency, watched side by side rather than as a single cluster aggregate. If one rank consistently trails — its queue draining slower under equal admission — add front-end capacity with --api-server-count so request parsing, tokenization, and streaming stop competing for CPU on the path feeding that rank . Tuning the API-server count is the lever for CPU-bound skew; it does not rebalance GPU work, but it removes the front end as the variable when diagnosing which axis to grow next.
The Head-Node Concentration Constraint and Why #25371 Closed
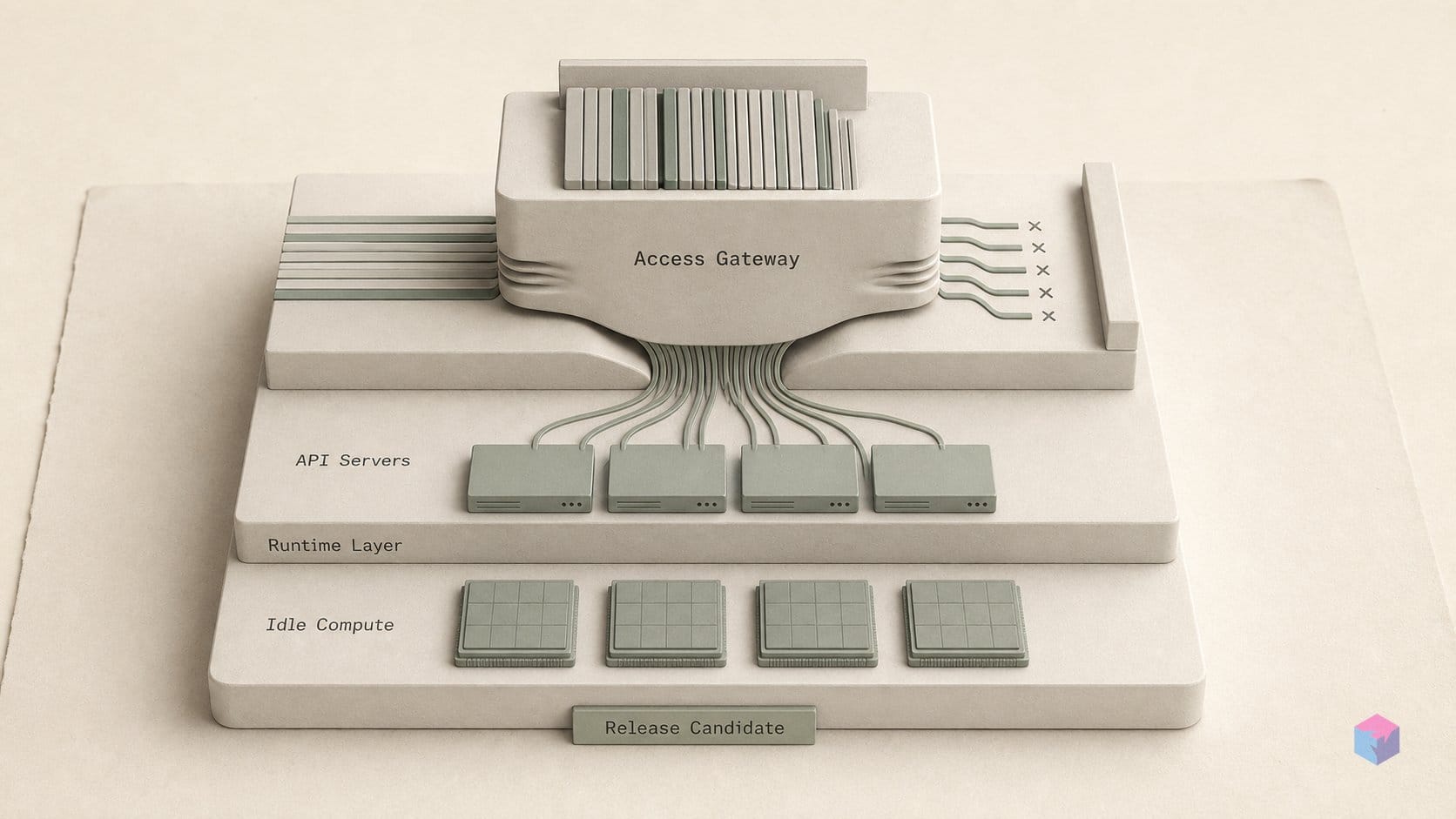
--api-server-count scales front-end processes on the head node only, so node 0 keeps concentrating every HTTP ingress, tokenization, validation, and response-streaming task no matter how many replicas you launch. Adding API servers raises CPU throughput on that one node, but it does not spread the front-end load across the cluster — at large data-parallel sizes, node 0 remains the single machine parsing and streaming for every DP rank, and its NIC and CPU cores become the shared ceiling .
The community noticed. Issue #25371, opened September 22, 2025, requested distributing front-end processes across nodes rather than pinning them to the head node; it was closed as not planned / stale, with no further commits as of June 2026 . The earlier RFC that framed the broader goal — scaling the API server across CPUs — is issue #12705, which is also inactive . Taken together, cross-node front-end fan-out is not on the stated roadmap. The supported scale-out unit for input processing is the head node's core count, not the cluster's.
Hybrid load balancing softens this, but does not erase it. Because hybrid LB places per-node API servers next to their local DP ranks, request parsing and streaming for those ranks happen on the node that hosts them — so adding nodes adds front-end capacity, provided you scale --api-server-count per node . What hybrid LB cannot remove is the coordinating layer: the upstream ingress or router still fronts the node endpoints, and the DP coordination still anchors to the head node. The CPU concentration shifts outward toward the per-node fronts rather than disappearing.
For practitioners, the takeaway is a hard boundary worth designing around. If your deployment is input-processing-bound and you expect to outgrow one node's CPU budget, internal LB behind a single endpoint will not save you — plan for hybrid or external topologies up front, and treat the head node's core count as the real limit on how far --api-server-count can take you .
v0.22.1 and the Deterministic Hang in Ray DP
If you run vLLM on the Ray data-parallel path with --api-server-count above its default, pin v0.22.1. Released June 5, 2026 as an 8-commit patch from 6 contributors, it resolves a deterministic hang in multi-node Ray DP serving that triggers whenever num_api_servers > 1. The hang is not flaky — it reproduces every time on the affected configuration — and v0.22.0 stable carries the defect, so upgrading is the fix rather than a retry-until-it-works workaround.
That patch is the tail of a fast-moving release train. The three release candidates each closed a distinct startup or runtime defect: rc1 (May 27, 2026) fixed a Model Runner V2 / KV-connector speculative-decoding issue; rc2 (also May 27) addressed early CUDA initialization; and rc3 (May 28) fixed a hard-coded timeout for multi-API-server startup, the change that landed as PR #43768. Stable v0.22.0 shipped May 29, 2026, and v0.22.1 followed a week later. The pattern is consistent: the scale-out features added in this line — multi-API-server fan-out, the DP supervisor, hybrid and external LB — exposed edge cases in process startup and coordination that took several point releases to settle.
The concrete takeaway: the architecture that lets the front end stop starving idle GPUs is sound, but it is young. Run v0.22.1, not v0.22.0, if any part of your stack sets --api-server-count > 1 on Ray — and watch the data-parallel deployment docs for the next patch before you commit a large MoE deployment to it.
Frequently asked questions
What does --api-server-count do in vLLM v0.22.0?
--api-server-count spawns N front-end (API server) process replicas on the head node that share a single HTTP endpoint and port, so the fan-out is invisible to callers — the client address and port never change. When unspecified it defaults to data_parallel_size . Internal load balancing inside those front-end processes routes each request to a core engine by its running/waiting queue depth, which lets CPU-bound input processing (HTTP parsing, tokenization, validation, streaming) scale out instead of starving idle GPUs .
What is the difference between internal, hybrid, and external load balancing in vLLM DP serving?
vLLM documents three data-parallel load-balancing modes :
- Internal: a single endpoint where the front end routes by per-engine queue depth; no external infrastructure required.
- Hybrid (
--data-parallel-hybrid-lb): per-node API servers queue only to their local DP engines while an upstream ingress/router spreads traffic across node endpoints. It requires--data-parallel-size-localand--data-parallel-start-rank, and is incompatible with--headless. - External: each DP rank is its own endpoint behind an external, telemetry-driven router. The docs state external DP CLI options target MoE deployments, while non-MoE dense models should run as independent vLLM instances.
How many GPUs does a DP + TP vLLM configuration require?
Total GPUs equals data_parallel_size × tensor_parallel_size. So --data-parallel-size 4 needs 4 GPUs, and --data-parallel-size 4 --tensor-parallel-size 2 needs 8 GPUs . Note that --max-num-seqs applies per DP rank, not cluster-wide, so concurrency budgets multiply with rank count. The official docs recommend that dense, non-MoE models run as independent vLLM instances behind an external load balancer rather than with --data-parallel-* flags .
What did vLLM v0.22.1 fix that v0.22.0 stable missed?
v0.22.1 fixed a deterministic hang in multi-node Ray data-parallel serving when num_api_servers > 1 — that is, when --api-server-count was set above its default. It was a small patch of 8 commits from 6 contributors and was the latest GitHub release by June 5, 2026 . Any team running Ray DP with a non-default --api-server-count on v0.22.0 should upgrade to v0.22.1 .
Can vLLM distribute front-end API server processes across multiple nodes?
No. --api-server-count fans the front-end processes out on the head node only, concentrating pre- and post-processing on node 0. Issue #25371, which requested distributing API servers across nodes, was closed as not planned and remained stale with no activity as of June 2026 . The DP Supervisor (--data-parallel-multi-port-external-lb) runs a node-local supervisor that launches one external-LB API server per local DP rank, but it does not distribute the coordinating role across nodes .








