
2026년 6월 2일, 블로그 게시물 하나가 일상적인 데스크 리젝션 과정을 AI 작성 감지기가 논문의 게재 여부를 가를 만큼 정확한지에 대한 논쟁으로 뒤바꿔놓았습니다. NeurIPS 2026 포지션 페이퍼 트랙은 모든 제출물을 상용 감지기로 스크리닝한 뒤, 178편을 일반적인 이의 신청 절차조차 없이 거부했습니다.
사건의 전말: 178건 데스크 거부, Pangram 3.3.2, 항소 불가
NeurIPS 2026 포지션 페이퍼 트랙 의장들은 상용 AI 작성 감지기인 Pangram 3.3.2를 이용해 모든 제출 논문을 스크리닝한 뒤, AI 저술 의심을 이유로 178편 — 트랙 전체의 18.4% — 을 이의 신청 경로도 없이 데스크에서 거부했습니다. 이 결정은 의장 Alex Lu, Seth Lazar, David Rügamer(보조 의장 Stanley Hua, Kate Metcalf)가 2026년 6월 2일 게시한 글을 통해 공개되었으며, 약 969~971편의 포지션 페이퍼 제출물을 스크리닝하고 논문은 "실질적으로 인간 저자가 직접 작성해야 한다"는 트랙 규정을 적용했습니다 .
핵심 요약: NeurIPS 2026 포지션 페이퍼 트랙은 의장단의 2026년 6월 2일 게시물에 따라, 약 969편의 제출물 전체를 Pangram 3.3.2 AI 감지기로 스크리닝한 뒤 178편(트랙의 18.4%)을 데스크에서 거부했습니다. 추가로 123편(12.7%)은 조건부 처리되어 6월 15일까지 출처 증빙을 제출하지 않으면 거부될 예정입니다.
178건의 거부 외에도, 의장단은 123편(12.7%)을 조건부 그룹으로 분류했습니다. 해당 저자들은 2026년 6월 15일까지 AI 도입 이전·이후·최종 체크포인트를 식별하는 버전 이력 형태의 출처 증빙을 제출해야 하며, 그렇지 않으면 거부됩니다 . 중요한 점은, 이 조치가 포지션 페이퍼 트랙에만 적용되었다는 것입니다. NeurIPS 2026 메인 프로그램은 정반대 입장을 취합니다. 메인 프로그램 핸드북은 저자들이 논문 준비와 작성에 어떤 도구를 사용해도 무방하며, 편집 보조·문법 교정·기본 코드 지원에 대해서는 별도 문서화가 필요 없다고 명시합니다 — 단, 정확성에 대한 책임은 저자에게 있습니다 .
트랙 전체의 처리 결과 분포:
| 처리 결과 | 논문 수 | 트랙 비중 | 조치 |
|---|---|---|---|
| 데스크 거부 | 178 | 18.4% | 거부, 일반 이의 신청 불가 |
| 조건부 | 123 | 12.7% | 2026년 6월 15일까지 출처 증빙 제출, 미제출 시 거부 |
| 통과 | ~668 | ~68.9% | 심사 진행 |
NeurIPS 자체 수치에는 처음부터 짚어둘 만한 단서가 있습니다. 게시물 본문은 한 곳에서 969편을, 첨부 표에서는 971편을 언급하고 있으며, 이 불일치는 공개된 기록에서 해소되지 않았습니다 — 따라서 제출 수는 어림값으로 받아들여야 합니다 . 어림값이 아닌 것은 이 조치의 규모와, 스크리닝 도구인 Pangram 3.3.2가 데스크 거부 통보가 나가기 불과 몇 주 전인 2026년 5월에 출시됐다는 사실입니다 .
Pangram의 논문 분류 및 플래깅 방식
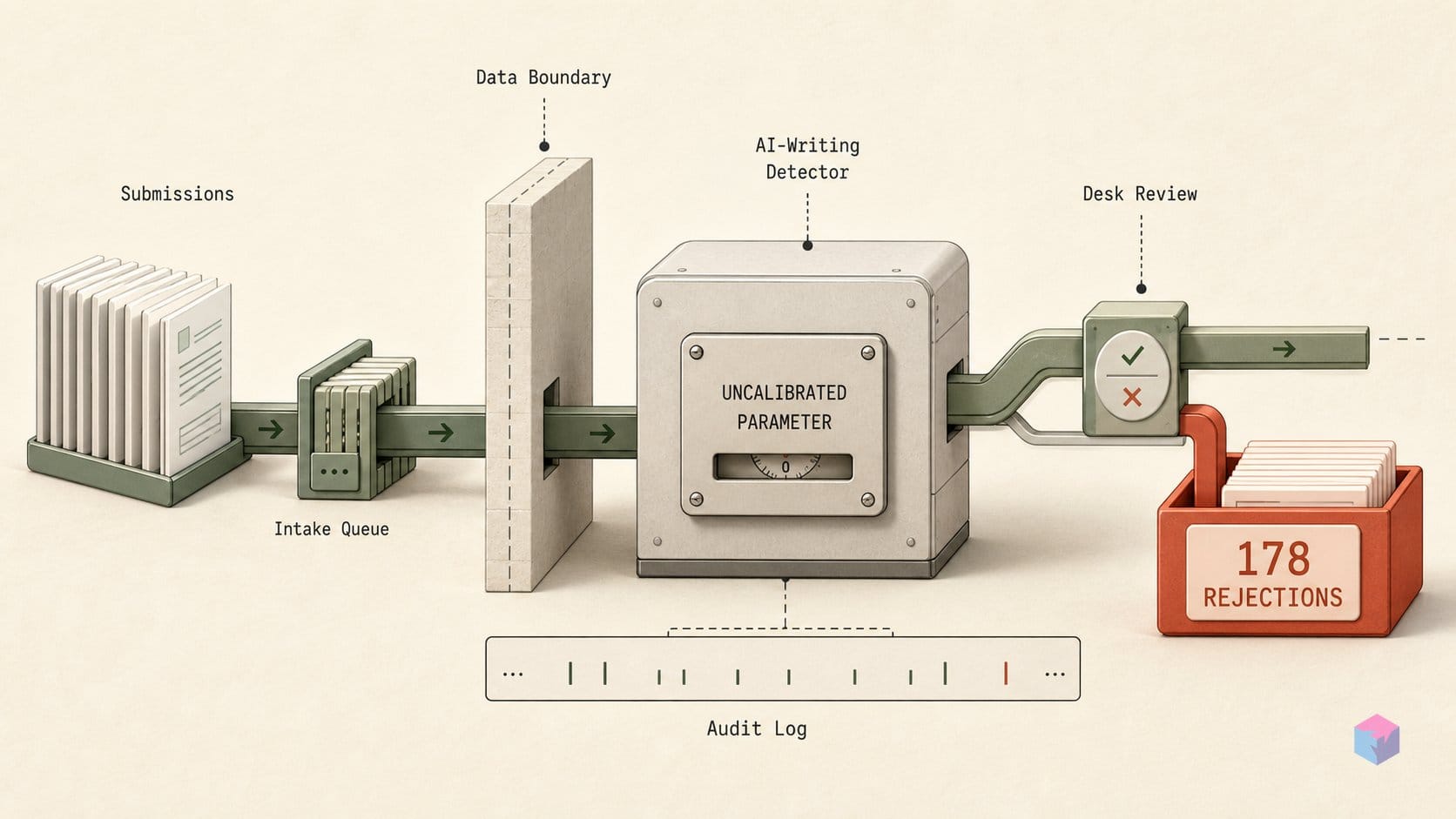
Pangram은 논문 전체를 하나의 텍스트 덩어리로 판단하지 않습니다. 문서를 고정 크기의 텍스트 윈도우로 분할해 각 윈도우에 독립적인 AI 확률값을 부여하고, 0.75 확률 임계값을 넘는 윈도우에 플래그를 표시한 뒤, 플래그된 윈도우의 비율을 논문의 헤드라인 'Pangram AI 점수'로 보고합니다 . 결정적인 함의가 있습니다. 점수 100%는 모든 윈도우가 임계값을 넘었다는 뜻이지, 단어의 100%가 기계가 생성했다는 의미가 아닙니다. 이 지표는 얼마나 많은 청크가 AI처럼 보였는지를 측정할 뿐, 실제 산문이 얼마나 AI로 작성됐는지를 측정하지 않습니다.
청크 크기는 파라미터이고 점수는 그 값에 따라 달라지기 때문에 이 구분은 중요합니다 — 이 민감도는 다음 절에서 자세히 살펴봅니다. 지금은 점수가 플래그된 윈도우 수를 전체 윈도우 수로 나눈 비율이라는 점만 기억해 두면 됩니다. 즉, 거부를 이끈 수치는 파생 백분율이지 단어 수준의 직접 측정값이 아닙니다 .
버전 타임라인을 보면 상황이 더 명확해집니다. Pangram 3.3은 2026년 5월 13일 출시됐고, 5월 15일 3.3.1 세그멘테이션 업데이트, 5월 18일 3.3.2 버그픽스가 뒤따랐습니다 — 회사 측은 3.3.2가 예측의 3% 미만을 변경할 수 있다고 밝혔습니다 . NeurIPS는 데스크 거부 통보 시점 기준 공개된 지 약 3주밖에 되지 않은 모델인 3.3.2를 사용했습니다.
정확도 면에서 Pangram이 공개한 수치는 실제로 인상적입니다. 3.3 모델 카드는 62,971개 샘플 기준 학술 글쓰기(영어) 위양성률 0.02%, 65,053개 샘플 기준 생의학 연구 논문 위양성률 0.01%를 보고합니다 . 그러나 같은 카드는 위양성 위험을 높이는 조건들도 명시합니다: 복잡한 수식, PDF 파싱 아티팩트, 참고문헌 목록, 템플릿화된 글쓰기 — 이는 정규 학술 포지션 페이퍼를 정의하는 구조적 특징들과 정확히 일치합니다. 감지기는 산문처럼 읽히는 텍스트에서는 신뢰할 수 있습니다. 문제는 수식과 인용이 빼곡한 문서에 적용했을 때 어떤 결과가 나오느냐입니다.
공개되지 않은 설정 하나가 탐지율을 30%포인트 흔들었다
전체 절차에서 가장 결정적인 선택은 저자들에게 한 번도 공개되지 않은 윈도우 크기 매개변수였다. Pangram의 기본 분할 방식—대략 250~350단어 윈도우—을 적용했을 때, Position Paper Track 제출 논문의 42.7%가 AI 점수 ≥0.9를 받았고, 28.2%(969편 중 약 273편)가 100%를 기록했다 . 운영위원회가 동일한 문서를 "medium" ~100단어 윈도우 전략으로 재실행하자 ≥0.9 비율은 12.7%로, 100% 비율은 2.16%로 급감했다 . ≥0.9 수치 기준으로 약 30%포인트의 차이가, 텍스트를 어떻게 잘라내느냐만으로 발생한 것이다.
| 설정 | 윈도우 크기 | ≥0.9 탐지율 | 100% 탐지율 |
|---|---|---|---|
| 기본값 (거절 적용) | ~250–350단어 | 42.7% | 28.2% |
| "Medium" | ~100단어 | 12.7% | 2.16% |
NeurIPS는 기본값인 더 큰 청크 설정으로 데스크 거절 절차를 진행했다 . 저자들에게는 어떤 분할 전략이 적용됐는지 고지되지 않았기 때문에, 한 설정에서는 기준을 통과했을 논문이 다른 설정에서는 아무런 통보 없이 탐지될 수 있었다. 이 차이의 메커니즘은 구조적이다. 더 큰 윈도우는 확률 추정당 더 많은 텍스트를 평균 내며, 수식·참고문헌·템플릿이 밀집된 학술 문서에서 이 평균화는 더 많은 윈도우를 Pangram의 0.75 탐지 기준선 이상으로 끌어올려, 최종 논문 점수로 집계되는 탐지 윈도우 비율을 부풀린다.
같은 매개변수가 운영위원회가 의존한 비교 근거 자체를 흔든다. 위원회는 훨씬 낮은 기본 윈도우 비율을 보인 학회들—FAccT 2022, FAccT 2025, NeurIPS Datasets & Benchmarks 2025 트랙—을 기준점으로 삼았다 . 그러나 분할 설정 하나로 ≥0.9 비율이 30%포인트 움직일 수 있다면, 이 트랙과 비교 대상 사이의 격차는 저자 행동의 실질적 차이만큼이나 문서 구조와 청킹 방식의 상호작용을 반영하는 것일 수 있다. NeurIPS Ethics & Datasets 2026 비교군 자체도 2025년 대비 급등했는데 , 이는 기준선이 깨끗한 통제군으로 취급하기에 충분히 안정적이지 않았음을 시사한다.
개발자 관점에서 교훈은 명확하다. 탐지기의 출력이 이의 제기 없는 이산적 결정으로 이어질 때, 파이프라인의 숨겨진 하이퍼파라미터가 곧 결정의 일부다. 250단어 기본값과 100단어 설정의 차이는 여기서 사소한 조정이 아니다—제출 논문의 28%를 100%로 탐지하느냐, 2%를 탐지하느냐의 차이다.
178편을 거절한 정확한 기준과 휴리스틱
178건의 데스크 거절은 단일 컷오프가 아니라 세 단계로 쌓인 규칙이었으며, 각 단계는 Pangram 점수 구간과 서로 다른 보조 신호를 조합했다 . 단계를 순서대로 살펴보면, 점수 단독으로 얼마나 큰 비중을 차지했는지, 그리고 그 위에 저자 수준 휴리스틱이 얼마나 얹혔는지가 드러난다.
- Tier A — 77편: Pangram 점수 ≥0.9이면 추가 조건 없이 그 자체로 데스크 거절 사유가 됐다 . 탐지기 출력이 결정의 전부였다.
- Tier B — 79편: 점수 ≥0.8에 저자 수준 신호—복수의 단독 저자 제출, 또는 별도의 데스크 거절 신호—가 결합되면 거절로 처리됐다 . 점수 단독으로는 불충분하다고 보고, 행동 휴리스틱이 이를 뒷받침해야 했다.
- Tier C — 22편: 점수 ≥0.5이면서 저자가 AI 미사용을 선언했거나 아무 선언도 하지 않은 경우 . 서약 자체가 점수 기준을 낮추는 보조 신호가 됐다.
별도로, 123편(트랙 전체의 12.7%)은 조건부 그룹에 해당됐다. 추가 조건 없이 점수가 ≥0.8이고 <0.9인 경우였다 . 이 저자들은 즉시 거절되지는 않았지만, 2026년 6월 15일까지 출처 증빙—AI 적용 전·후·최종 체크포인트를 식별한 버전 이력과 AI 편집이 새로운 실질 내용을 추가했는지에 대한 분석—을 제출하거나 거절 처리될 것을 요구받았다 .
단계 체계가 시사하는 정밀함을 흔드는 세부 사항이 하나 있다. 집계가 완전히 일치하지 않는다. 본문은 100% 코호트를 969편 중 273편으로 보고하는 반면, 첨부 표에는 971편이 기재되어 있다 . 이 분모 불일치는 공개 기록에서 해소되지 않은 채로 남아 있어, 제출 편수와 이를 기반으로 산출된 모든 비율은 근사치로 봐야 한다. 이의 제기 없는 거절을 내리는 절차에서 기준 모집단의 설명되지 않는 2편 오차는 무시할 수 없는 기록 공백이다. 위에서 인용된 모든 기준 비율의 닻이 바로 그 데이터이기 때문이다.
교정 격차: 공개 기록에 없는 것들
교정 격차란, 완전한 데스크 리젝션 규칙이 판단 대상 모집단을 기준으로 검증되었다는 공개된 증거가 전혀 없다는 것을 의미합니다. 2026년 6월 9일 기준, NeurIPS 공개 게시물에는 기각 논문의 Pangram 점수 원시 분포, 실제 2026 포지션 페이퍼 제출물에서 추출한 정답 검증 세트, 신뢰 구간, 교정 곡선, PDF 파싱 아티팩트 분석 중 어느 것도 포함되어 있지 않습니다 . 빠진 것은 탐지기의 보고된 정확도가 아니라, 복합 절차가 이 특정 코퍼스에서 의도한 대로 작동한다는 증명입니다.
이 구분이 중요한 이유는, 공개된 위양성률이 Pangram 분류기 자체만을 설명할 뿐, 그 위에 구축된 의사결정 규칙을 설명하지 않기 때문입니다. 3.3 모델 카드에는 학술 글쓰기(영어) FPR 0.02%(N=62,971)와 생의학 연구 논문 FPR 0.01%(N=65,053)가 보고되어 있으며 , 2025년 9월 NBER 워킹 페이퍼(w34223)는 Pangram이 정확도 손실 없이 FPR ≤0.005라는 엄격한 기준을 충족한 유일한 탐지기였다고 밝혔습니다 . 그러나 이 수치들은 여기서 실제로 적용된 규칙, 즉 탐지기 출력과 AI 사용 확인서 및 저자 수준 휴리스틱을 결합한 절차를 설명하지 않습니다. 그 복합 절차의 오류율은 공개되지 않았습니다.
동일한 모델 카드는 참고문헌, 기술 매뉴얼, 템플릿 글쓰기, 복잡한 수식, 파싱 아티팩트가 위양성 위험을 높인다고 경고합니다 . 이는 정식 포지션 페이퍼에 가득한 바로 그 텍스트적 특징들입니다. Pangram은 2025년 11월 분석에서 자사 도구에 대한 기준을 다음과 같이 제시했습니다:
"위양성률이 0이 아닌 경우, 데스크 리젝션과 같이 논문 운명을 결정짓는 개별 판단을 권고하기 전에 신뢰도를 수치화할 책임이 생긴다." — Pangram, 2025년 11월 분석 (source: Pangram).
운영위원회의 절차는 이 기준을 공개적으로 충족하지 못했습니다. 그들의 검증은 12개 AI 활용 시나리오에서 테스트한 생성된 포지션 페이퍼 10편과 선별된 FAccT 2022 텍스트 윈도우 10개에 기반하였으며, FAccT 2022, FAccT 2025, NeurIPS Datasets & Benchmarks 2025 등 비교 행사들을 참조했습니다 . 2026년 arXiv 연구에 따르면, 모델이 안정적인 신호 대신 데이터셋별 문체 단서에 의존하기 때문에 강력한 도메인 내 탐지기 성능이 교차 도메인 및 교차 생성기 평가에서 무너질 수 있습니다. 10개 샘플 합성 실험과 외부 행사 비교자는 NeurIPS 2026 포지션 페이퍼 모집단, 즉 178건의 이의 없는 기각을 수용한 바로 그 모집단에 대한 분포 일치 검증을 구성하지 않습니다.
절차에 대한 비판의 목소리

절차 비판자들은 두 가지 뚜렷한 약점을 지적했습니다: 의사결정 방식의 논리적 순환성, 그리고 일반적인 인간의 글쓰기가 탐지기를 신뢰할 수 있을 만큼 작동시킨다는 주장입니다. 피해 저자 Sergey Berezin은 2026년 6월 3일, 기각을 위해 고려된 자료가 각 저자의 AI 사용 확인서와 결합된 Pangram 출력이었기 때문에 확인서 자체가 사실상 탐지기에 의해 판단되고 있다고 주장했습니다. AI 사용 부인이 높은 점수 앞에서 아무 효력도 없다는 순환논리라는 것입니다 . 그는 또한 FAccT 통제군과 운영위원회가 생성한 합성 논문으로는 분포 이동 상황에서 실제 NeurIPS 2026 제출물의 위양성률을 확인할 수 없다고 주장했습니다.
이를 설명하기 위해 Berezin은 트랙 운영위원 본인들의 최근 2026년 논문에 Pangram을 적용해 69%, 45%, 36%, 24%의 점수를 관찰했다고 보고했습니다. AI 저작을 주장하는 것이 아니라, 인간이 작성한 것으로 추정되는 글에도 0이 아닌 점수가 나타난다는 점을 지적한 것입니다 .
다른 연구자들은 문체적 교란 요인을 지적했습니다. UCL NLP의 Pasquale Minervini는 잦은 em 대시 사용 등의 습관을 이유로 자신의 대부분 인간이 작성한 초안이 플래그될 것이 대략 "80% 확실하다"고 말했습니다 . Panos Ipeirotis는 문법 교정을 위해 LLM을 사용하는 것이 이제 Pangram 같은 탐지기에서 "AI 작성"으로 인식되어, 메인 트랙이 명시적으로 허용하는 워크플로우에 불이익을 준다고 경고했습니다. Jessica Hullman은 더 근본적인 범주 오류를 직접 설명했습니다.
"탐지기는 누가 단어를 엮었는지를 측정할 뿐, 아이디어에 대한 실질적인 인간의 기여는 측정하지 않습니다." — Jessica Hullman, 비판의 요지를 정리하며 (source: Startup Fortune).
더 넓은 도구 사용 기록도 신중함을 뒷받침합니다. OpenAI는 2023년 7월 20일 낮은 정확도를 이유로 자체 AI 텍스트 분류기를 중단하고, 이를 주요 의사결정 도구로 사용해서는 안 된다고 경고했습니다 . Turnitin의 공식 지침도 AI 탐지 결과가 불이익 조치의 단독 근거가 되어서는 안 된다고 명시합니다 . 이러한 배경에서, 178건의 이의 없는 기각을 단일 탐지기 점수에 실질적으로 의존하는 것은 탐지 기술 공급업체 스스로가 권고하는 기술 활용 방식에 반하는 것입니다 .
2026년 학술대회 정책, 어디로 향하는가
NeurIPS 사태는 'AI 보조 작성'의 의미를 놓고 학술대회들이 첨예하게 엇갈리는 해에 터졌다. ICLR 2026은 NeurIPS보다 강경한 입장을 취했다. 미공개 LLM 사용은 즉시 게재 거절 사유가 된다. 이는 저자가 논문 준비·작성에 어떤 도구든 자유롭게 사용할 수 있으며 맞춤법 검사, 문법 교정, 편집 보조, 기본 코드 지원에 대한 별도 서류를 요구하지 않는 NeurIPS 2026 본 프로그램보다 훨씬 엄격한 자세다 . 같은 학술대회의 두 위원회가 같은 사이클에서 정반대의 기본 운영 방침에 도달한 셈이다.
정책만큼이나 도구도 제각각이다. GPTZero는 별도로, 채택된 NeurIPS 2025 논문에서 약 100건의 환각(hallucination)을 발견했다고 주장했다 — 다른 도구, 다른 대상(단일 트랙의 저자 여부가 아닌 채택된 주류 논문의 사실 오류), 그리고 AI가 이미 출판 작업에 얼마나 깊이 스며들어 있는지에 관한 다른 암묵적 주장이었다. 조작된 내용의 탐지와 '문장을 엮은 주체'의 탐지는 동일한 측정이 아니며, 이를 혼동하면 정책 논의만 흐려진다.
전환도 급작스러웠다. 2025년 최초의 Position Paper Track은 책상 거절 심사를 전적으로 수작업으로 진행했으며 그 과정에서 AI를 전혀 사용하지 않았다 . 2026년 트랙은 한 사이클 만에 자동화 집행으로 전환했는데, 두 방식 간의 정확도 비교 데이터는 공개되지 않았다 .
핵심 시사점은 이렇다. 같은 학술대회 내에서 한쪽은 어떤 작성 도구든 서류 없이 허용하고, 다른 트랙은 탐지기 점수만으로 책상 거절을 내린다면, 그 간극은 나중에 조율할 세부 사항이 아니라 미해결 핵심 질문 그 자체다. 학술대회들이 조작 여부, 공개 여부, 인간 저자성 중 무엇을 단속할지 합의할 때까지는 사이클마다 뒤집히는 사례가 더 나올 것이다. 공통 기준이 있다고 가정하지 말고, 제출 전에 각 학술대회의 실제 핸드북을 직접 확인하라.
자주 묻는 질문
책상 거절이란 무엇이며, 영향받은 NeurIPS 저자들에게 이의 신청 절차가 없는 이유는?
책상 거절은 논문이 동료 심사에 도달하기 전에 내려지는 행정적 거절, 즉 심사자 판정이 아닌 사전 심사 결정이다. NeurIPS는 이를 Position Paper Track의 정책 집행 수단으로 활용해, 일반적인 이의 신청 절차 없이 178건(트랙 전체의 18.4%)의 책상 거절을 발행했다 . 이의 신청 절차가 없는 이유는 구조적이다. 동료 심사 이의 신청 경로는 심사 결과에 적용되며, 위원장들은 이러한 심사 전 행정 결정에 대한 별도 이의 신청 경로를 열지 않았다. 123건의 '조건부' 사례(12.7%)만이 구제 경로를 제공받은 유일한 그룹이며, 그 경로는 이의 신청이 아닌 증거 제출이다 .
제출 논문에서 Pangram AI 100% 평점은 실제로 무엇을 의미하는가?
Pangram AI 100% 점수는 도구가 분할한 모든 텍스트 윈도우에 플래그가 지정됐다는 뜻이다 — 각각 0.75 이상의 AI 확률이 할당된 것으로, 단어의 100%가 AI에 의해 작성됐다는 의미가 아니다 . Pangram은 문서를 윈도우로 분할하고 각각에 점수를 매긴 뒤 0.75 초과 항목에 플래그를 지정하며, 플래그된 윈도우의 비율로 점수를 보고한다. 측정 기준이 윈도우 단위이므로, 평점은 전적으로 윈도우 크기에 달려 있다 — 저자들에게는 공개되지 않은 매개변수다. 기본 윈도우 설정에서는 Position Paper 제출물의 28.2%가 100% 점수를 기록했다 .
청크 크기가 플래그 비율을 왜 그토록 극적으로 바꾸는가?
윈도우 크기가 비율을 바꾸는 이유는, 짧은 윈도우는 더 많은 지역적 문체 변화를 포착해 단일 윈도우가 일관되게 AI 생성으로 보이기 어렵게 만드는 반면, 큰 윈도우는 더 넓은 텍스트를 평균화해 AI스러운 구절 하나가 윈도우 전체 확률을 지배할 수 있기 때문이다. NeurIPS는 이 효과를 직접 문서화했다. 기본 약 250~350단어 윈도우에서 '중간' 약 100단어 전략으로 전환하자 ≥0.9 비율이 42.7%에서 12.7%로, 100% 비율이 28.2%에서 2.16%로 떨어졌다 — 저자들이 본 적도 없는 설정 하나에서 약 30포인트의 변동이 생긴 것이다 .
조건부 그룹 123명의 저자는 2026년 6월 15일까지 무엇을 제출해야 하는가?
조건부 그룹 저자 — Pangram 점수 ≥0.8이면서 <0.9이고 추가 고려 사항이 없는 저자 — 는 2026년 6월 15일까지 출처 증거를 제출해야 하며, 그렇지 않으면 추가 심사 없이 거절된다 . 구체적으로는 AI 적용 전, 적용 후, 최종 원고 체크포인트를 식별하는 버전 기록과 함께, AI 편집이 새로운 실질적 내용을 도입했는지에 대한 분석이 필요하다. 이는 근본 결정에 대한 이의 신청이 아닌, 탐지기 점수를 반박하기 위해 저자에게 부과된 서류 작성 부담이다.
Pangram 자체는 자사 도구를 논문 거절의 유일한 근거로 사용하도록 권장하는가?
아니다. 2025년 11월 분석에서 Pangram은, 양의 위양성(false-positive) 비율이 책상 거절과 같은 개별적인 논문 운명 결정을 권고하기 전에 신뢰성을 정량화할 책임을 만든다고 주장했다 . 이는 광범위한 탐지기 지침과 일치한다. OpenAI는 낮은 정확도를 이유로 2023년 7월 20일 자체 분류기를 중단하고 이를 주요 의사결정 도구로 사용하지 말 것을 경고했으며, Turnitin의 공식 지침도 AI 탐지 결과가 불이익 조치의 유일한 근거가 되어서는 안 된다고 명시한다 . NeurIPS 위원장들은 이 긴장을 인정했지만 그럼에도 자동화 절차를 진행했다 .








